EMNLP 2018 | 短文本分类,腾讯AI Lab联合港中文提出主题记忆网络
机器之心发布
来源:腾讯 AI Lab
在 EMNLP 2018 中,针对短文本的处理,腾讯 AI Lab 发布了 论文 Topic Memory Networks for Short Text Classification。这篇论文由腾讯 AI Lab 主导,与香港中文大学合作完成。本文是主题模型与文本分类在神经网络框架下的一次结合,作为主题模型与深度学习联合训练的一个早期的探索,能够很自然地被扩展到很多深度学习任务的上。
论文:Topic Memory Networks for Short Text Classification

论文链接:https://arxiv.org/pdf/1809.03664.pdf
短文本分类 (Short Text Classification)
短文本因为其内容简短、易于阅读和传播的特性作为信息交互的载体广泛存在,例如新闻标题、社交媒体的信息、短信等等,因此如何让机器自动而高效地理解短文本一直是自然语言处理的重要任务,而文本分类作为文本理解的基础任务、能够服务于大量的下游应用(例如文本摘要、情感分析、推荐系统等等),更是长期以来学术界与工业界关注的焦点。然而,短文本分类任务本身又十分困难,这其中的原因主要来自文本的内容简短而引起数据稀疏性问题,从而导致了模型分类的时候没有足够的特征进行类别的判断。为了理解短文本分类的挑战,表 1 展示了一个 Twitter(推特)上的一个短文本分类例子。

表 1:Twitter 上文本分类的例子。
R1 和 R2 都是训练样本分别属于 Super Bowl (超级碗) 以及 New Music Live(新音乐盛典)类别,S 是测试样本属于 New Music Live 类别,但是仅仅从给定的 11 个单词,很难判断出 S 与新音乐盛典的关系。但是 R2 中 wristband(手环)与 Bieber(比伯)的共现极大地丰富了 wristband 的语义,将 wristban\d 与 New Music Live 关联起来,因为当时 Twitter 上支持 Bieber 送手环的活动使得训练语料中 wristband 和 Bieber 在 New Music Live 类别的 tweets 中大量共现。如果模型能够定位到 wristband 是一个关键的词,就更容易判断出测试样本 S 应该被分类为 New Music Live,否则的话,S 很有可能被错误分类为 Super Bowl,因为其与 R1 大部分的词都是重合的。
主题记忆网络 (Topic Memory Networks)
Topic Model(主题模型)的要旨是基于词在文章中的共现关系,从大量的词汇中找出主题词(例如 S 中的 wristbands),这部分主题词在一部分的文章中经常出现,但并不似常用词一般在大部分文章中都频繁出现。因为主题词的这种特性,相较于低频词或常用词,往往能更好地指明文本的类别。因此,过去的工作已经证明,用主题模型学出的主题表示,能够有效地提高文本分类的性能。然而,目前的大多数文本分类任务在用到主题表示的时候,往往采用两步走的方法,先训练好主题模型,然后将主题模型输出的主题表示去初始化文本分类的特征空间。近期,Neural Topic Model(神经主题模型:https://arxiv.org/pdf/1706.00359.pdf)的提出,使得主题模型与大量的深度学习任务能够在多任务学习 (multi-task learning) 的框架下被联合训练,本文以深度学习最基础的任务——文本分类作为这种新的训练模式的一个初期的探索,提出了一种新的网络模型 Topic Memory Networks(主题记忆网络),网络结构如图 1 所示。
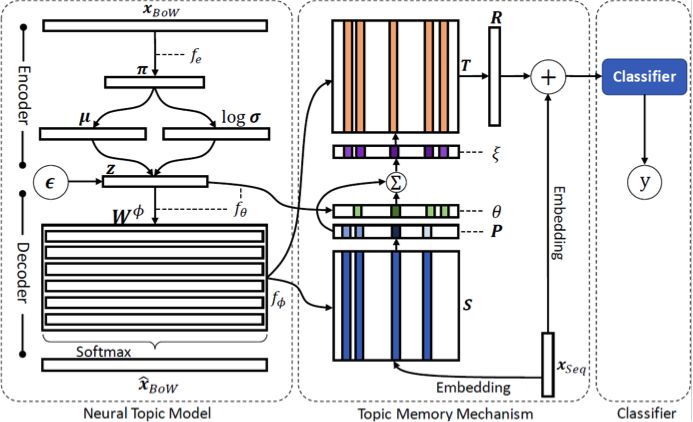
图 1:主题记忆网络的框架图。从左到右分别是神经主题模型、主题记忆机制与文本分类器。
主题记忆网络一共可以分为三部分,从左到右分别是 Neural Topic Model (神经主题模型)、Topic Memory Mechanism(主题记忆机制)、以及 Classifier(文本分类器)。其中,神经主题模型主要用于学习主题表示;主题记忆机制主要用于将学到的主题表示映射到对文本分类有用的特征空间当中;文本分类器主要用于输出文本分类标签,可以适配多种分类器(例如卷积神经网络(CNN)或循环神经网络(RNN)),因为 CNN 在之前的的工作中被证明对文本分类更有效,因此在本文对于主题记忆网络的实验探索(将于下文重点讨论)中,我们选择 CNN 作为文本分类器。
为了实现主题模型与文本分类的联合训练,主题记忆网络的损失函数为主题模型的训练目标 variational lower-bound 以及文本分类器的训练目标 cross-entropy 的加权和。
实验分析
为了探索主题记忆网络对短文本分类的性能,本文选择了四个基准数据集,分别为:TagMyNews 新闻标题、Snippets 搜索片段、Twitter 和 Weibo(新浪微博),四个数据集的统计信息如表 2 所示。
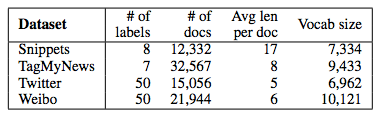
表 2:实验数据集详细信息。
本文选择了当下最好的短文本分类模型与主题记忆网络的性能进行了比较,在四个实验数据集的实验结果如表 3 所示,从实验结果中可以看出,主题记忆网络在四个数据集上都显著提升了 state-of-the-art 的性能。
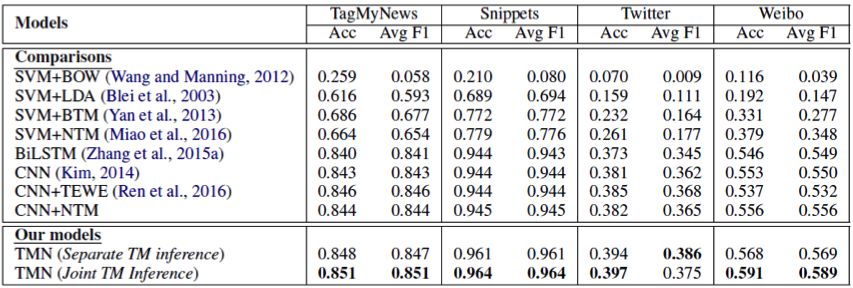
表 3:主题记忆网络与比较模型的实验结果。TMN 表示主题记忆网络:TMN (Separate TM inference) 表示先预训练好神经主题模型,之后把其输出的主题表示初始化主题记忆机制来进行文本分类。TMN (Joint TM inference) 表示神经主题模型与文本分类联合训练。两个版本的主题记忆网络的结果显著高于所有的比较模型(p<0.05 paired t-test)。
考虑到主题记忆网络能够对主题模型与文本分类进行联合训练,那么主题模型是否能够获益于这种多任务训练,以学到更有意义的表示呢?本文对主题模型的输出进行了定量与定性的分析。在定量分析中,被广泛使用的 CV coherence 分数 (https://github.com/dice-group/Palmetto) 作为评测指标,比较模型包括经典的主题模型 LDA、短文本主题模型中的 state-of-the-art 模型 BTM、以及神经主题模型 NTM,越高的分数说明学到的 topic 表示越有意义,实验结果如表 3 所示,定量实验结果说明,通过与文本分类联合训练,主题模型也能够学到更有意义的主题表示。
为了探索为什么主题记忆网络能取得更好的性能,本文讨论了主题记忆网络对表 1 的测试样例 S 学到了什么表示,结果如图 2 所示。由结果读者可以观察到,与 S 最相关的三个主题分别与 Bieber、追星以及音乐相关。虽然三个主题的相关主题词大多都不被包含于 S 当中,但是通过挖掘词与词的共现关系,主题模型成功扩展了 S 中主题词 wristband 的语义,从而使得 S 得以被正确分类到 New Music Live。
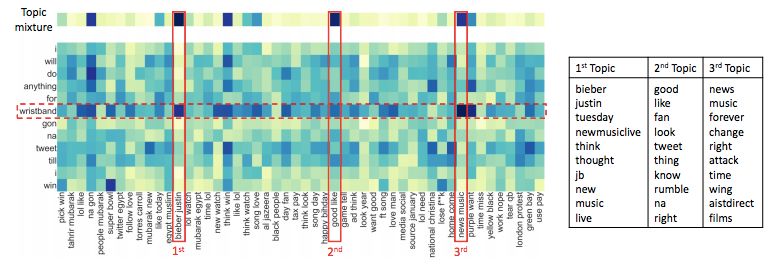
图 2:主题记忆网络学到的对于 S 的表示。左图是主题记忆机制中存储的 S 中每个词与各主题之间的关系热度图,右图是关系最大的三个主题的相关词。
结语
本文是主题模型与文本分类在神经网络框架下的一次结合,也是主题表示与其他深度学习任务联合训练的一个尝试,希望能够对启发后续对于主题表示与深度学习的研究与应用。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com