

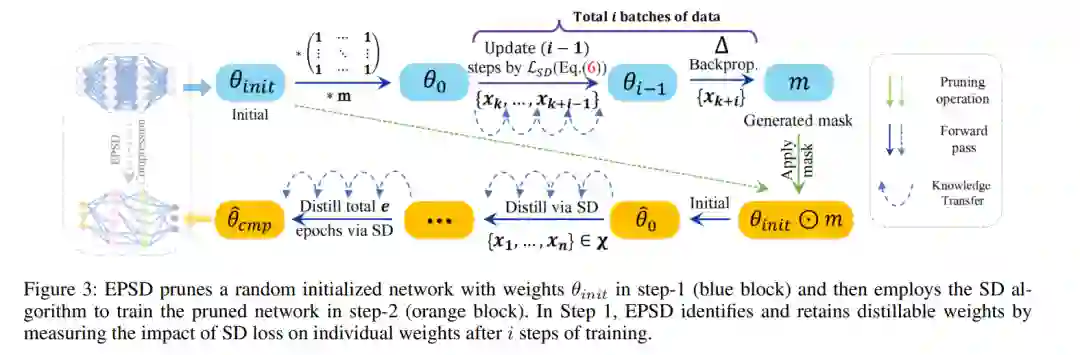
神经网络压缩技术,如知识蒸馏(KD)和网络剪枝,已日益受到关注。最近的工作“先剪枝,再蒸馏”揭示了一个被剪枝过的对学生友好的教师网络可以提高KD的性能。然而,传统的教师-学生流程,需要对教师进行繁琐的预训练和复杂的压缩步骤,使得结合KD的剪枝效率较低。除了压缩模型,最近的压缩技术也强调效率方面。早期剪枝与传统剪枝方法相比,需要的计算成本显著较低,因为它不需要一个大的预训练模型。同样,KD的一个特殊情况,称为自蒸馏(SD),更为高效,因为它不需要预训练或学生-教师对的选择。这激发了我们将早期剪枝与SD结合起来进行高效模型压缩的想法。在这项工作中,我们提出了一个名为早期剪枝与自我蒸馏(EPSD)的框架,该框架在给定的SD任务中识别并保留早期剪枝的可蒸馏权重。EPSD有效地将早期剪枝和自我蒸馏结合在一个两步过程中,保持了剪枝网络的可训练性以进行压缩。EPSD不是简单地组合剪枝和SD,而是通过在训练前保留更多可蒸馏的权重使剪枝网络更倾向于SD,以确保更好的剪枝网络蒸馏。我们证明EPSD改进了剪枝网络的训练,通过视觉和定量分析得到支持。我们的评估涵盖了多样的基准(CIFAR-10/100, Tiny-ImageNet, 全尺寸ImageNet, CUB-200-2011和Pascal VOC),EPSD的表现超过了先进的剪枝和SD技术。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日