

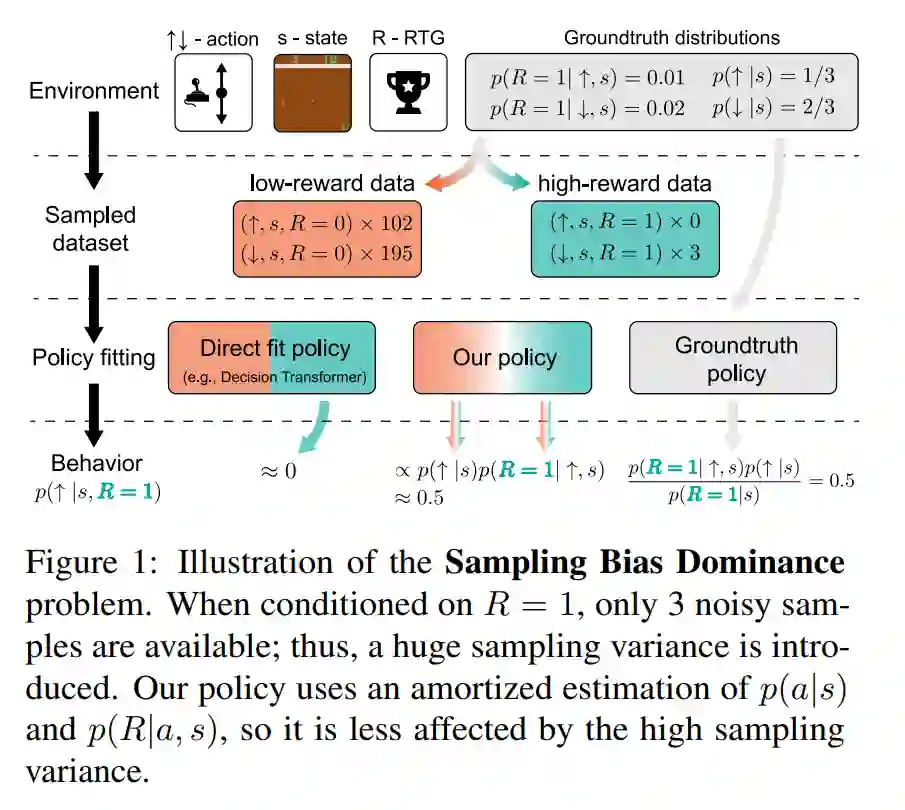
最近,基于奖励条件的强化学习(RCRL)因其简单性、灵活性和离策略的特性而受到欢迎。然而,我们将展示当前的RCRL方法在根本上存在局限性,并且未能解决RCRL的两个关键挑战——提高对高奖励目标(RTG)输入的泛化能力,并在测试时避免超出分布的RTG查询。为了解决这些挑战,在训练传统的RCRL架构时,我们提出了贝叶斯重参数化RCRL(BR-RCRL),这是一种受贝叶斯定理启发的RCRL归纳偏好的新方法。BR-RCRL消除了阻碍传统RCRL在高RTG输入上泛化的核心障碍——模型将不同的RTG输入视为独立值的倾向,我们将其称为“RTG独立性”。BR-RCRL还允许我们设计一种伴随的自适应推理方法,该方法在避免产生不可预测行为的超出分布查询的同时,最大化总回报。我们展示了BR-RCRL在Gym-Mujoco和Atari离线强化学习基准测试中达到了最先进的性能,相比传统RCRL提高了最多11%。
https://www.zhuanzhi.ai/paper/2b82e5bac3175c985ebe32e778d02808
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年7月7日
Arxiv
11+阅读 · 2019年10月30日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年7月7日
Arxiv
11+阅读 · 2019年10月30日