

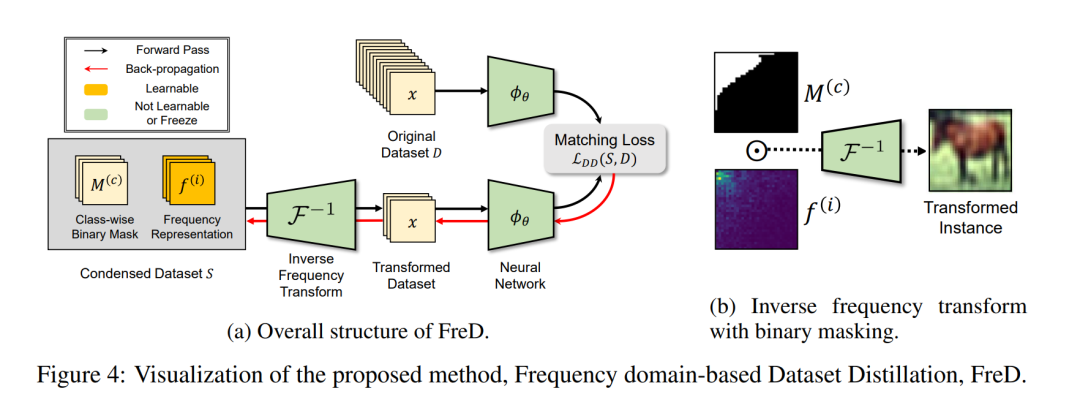
这篇论文介绍了 FreD,一种新型的数据集提炼参数化方法,该方法利用频率域从大型原始数据集中提炼出小型合成数据集。不同于传统聚焦于空间域的方法,FreD 采用基于频率的变换来优化每个数据实例的频率表示。通过利用空间域信息在特定频率分量上的集中,FreD 聪明地选择一部分频率维度进行优化,从而显著减少了合成实例所需的预算。通过基于解释方差的频率维度选择,FreD 展示了其在有限预算内高效操作的理论和实证证据,与传统的参数化方法相比,更好地保留了原始数据集的信息。此外,基于 FreD 与现有方法的正交兼容性,我们确认 FreD 在不同基准数据集的评估场景中,始终提高了现有提炼方法的性能。我们在 https://github.com/sdh0818/FreD 上发布了代码。
成为VIP会员查看完整内容


相关内容
Arxiv
0+阅读 · 2024年1月5日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年1月5日