

我们介绍DeepNash,它是一个自主智能体,能以人类专家的水平执行不完全信息博弈Stratego。Stratego是人工智能(AI)尚未掌握的少数标志性棋盘游戏之一。这是一个具有双重挑战的游戏:它需要像国际象棋那样的长期战略思考,但它也需要像扑克那样处理不完美的信息。支撑DeepNash的技术使用了一种基于博弈论、无模型的深度强化学习方法,没有搜索,它通过自我游戏从头开始学习掌握战略。DeepNash在Stratego中击败了现有的最先进的人工智能方法,并在Gravon游戏平台上取得了年初至今(2022年)和历史排名前三的成绩,与人类专家玩家竞争。
引言
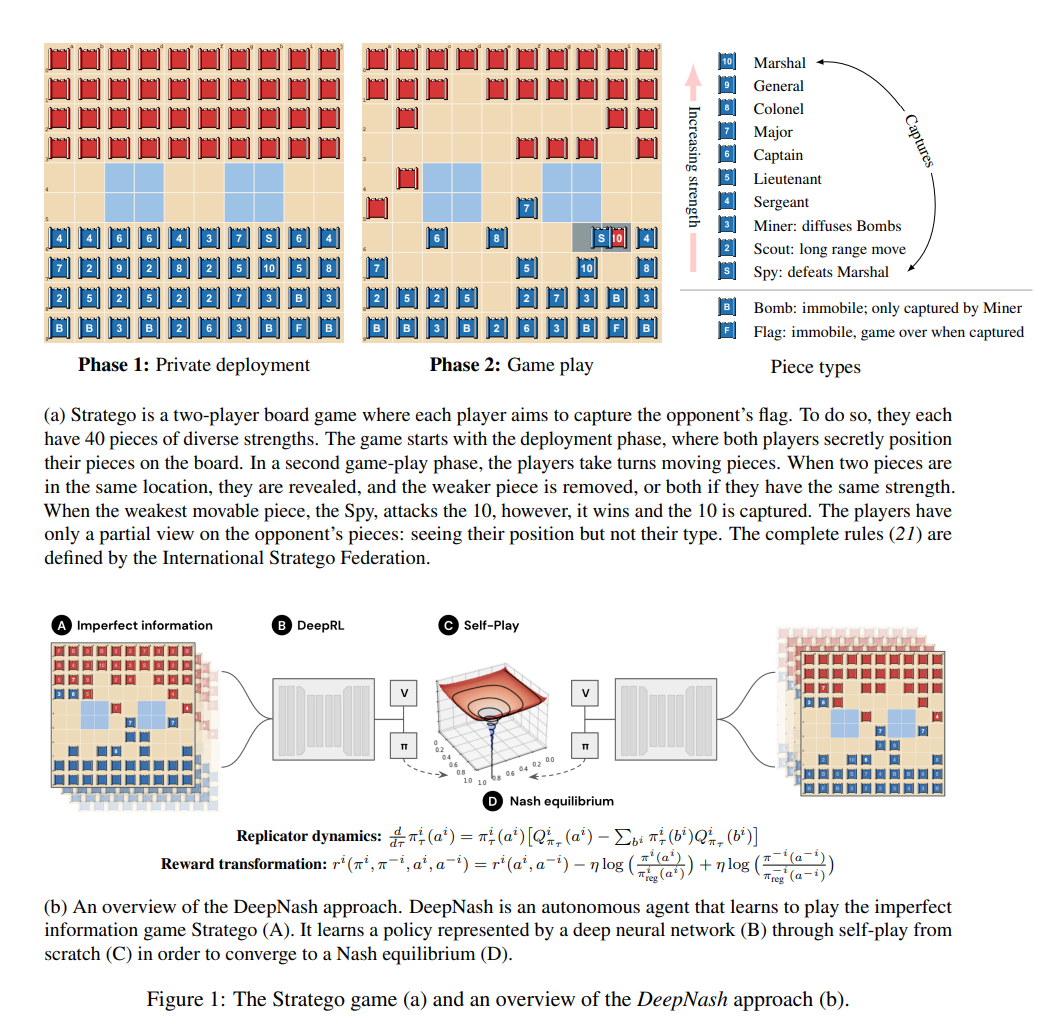
自人工智能(AI)领域成立以来,其进展一直是通过对棋盘游戏的掌握来衡量的。棋盘游戏使我们能够衡量和评估人类和机器如何在受控环境中制定和执行战略。几十年来,提前计划的能力一直是人工智能在完美信息游戏(如国际象棋、跳棋、象棋和围棋)以及不完美信息游戏(如扑克和苏格兰场)中取得成功的核心。多年来,Stratego棋盘游戏已经构成了人工智能研究的下一个前沿领域之一。关于游戏阶段和游戏机制的可视化,见图1a。该游戏带来了两个关键的挑战。首先,Stratego的游戏树有10^535个可能的状态,这比无下限的德州扑克(一种经过充分研究的不完全信息)还要大。
和有10^360个状态的围棋游戏。其次,在Stratego游戏中,每个玩家在游戏开始时需要对1066种可能的部署进行推理,而扑克只有103种可能的牌对。像围棋和国际象棋这样的完全信息游戏没有私人部署阶段,因此避免了这个挑战在Stratego中带来的复杂性。目前不可能使用最先进的基于模型的完美信息规划技术,也不可能使用最先进的不完美信息搜索技术,将游戏分解为独立的情况。
由于这些原因,Stratego提供了一个具有挑战性的基准,可以在一个无与伦比的规模上研究战略互动。就像大多数棋盘游戏一样,Stratego测试了我们依次做出相对缓慢、深思熟虑和合乎逻辑的能力。最近在大型不完全信息博弈中取得的成功是在实时Stratego中取得的,如《星际争霸》、《Dota》和《夺旗》,在这些游戏中,大多数决定必须快速和本能地做出,而且是连续时间的。Stratego由于其结构的许多复杂方面,人工智能研究界在该游戏中几乎没有取得任何进展。在该游戏中的成功是有限的,人工代理只能发挥出与人类业余爱好者相当的水平,见例如。在没有人类示范数据的情况下,从头开始开发智能代理,学习端到端,在Stratego中做出最佳决策,仍然是人工智能研究的巨大挑战之一。
在这项工作中,我们介绍了DeepNash,一个能够在没有人类演示的情况下,以无模型的方式学习玩Stratego的智能体,击败了以前最先进的AI智能体,并在最复杂的游戏变体Stratego Classic中实现了人类专家级的表现。DeepNash的核心是一种有原则的、无模型的强化学习算法,称为正则化纳什动力学(R-NaD)。DeepNash将R-NaD与深度神经网络架构相结合,并收敛到-纳什均衡,这意味着它学会了在高度竞争的水平上进行游戏,并对试图利用它的对手具有强大的抵抗力。所有不完全信息博弈都拥有混合策略的纳什均衡,为所有玩家分配一个混合(或随机)策略,其中只要没有其他玩家偏离他们的策略,就没有玩家能从中受益。虽然在轮流进行的双人零和博弈中,采取确定性决策使均衡策略的价值最大化就足够了,但在处理不完全信息博弈时,这种方法在理论上是不健全的。在这种游戏中,需要部署其他战术,这些战术能更好地反映现实世界的决策过程。正如冯-诺伊曼所描述的那样,"现实生活包括虚张声势,包括欺骗的小策略,包括问自己对方会认为我打算怎么做"。 图1b展示了DeepNash方法的高级概述。
我们提出了新的无模型强化学习方法DeepNash,并在Gravon游戏平台上针对各种最先进的战略机器人和人类专家玩家系统地评估了其性能。DeepNash以超过97%的胜率令人信服地击败了目前所有为玩Stratego而开发的最先进的机器人,并在Gravon上与人类Stratego玩家达到了高度竞争的水平,在年度(2022年)和所有时间的排行榜上,它都跻身前三名,胜率为84%。因此,这是人工智能算法第一次能够在复杂的棋盘游戏中学习到人类专家的水平,而没有在学习算法中部署任何搜索方法,也是人工智能第一次在Stratego中达到人类专家的水平。

