AI来搞财富分配比人更公平?来自DeepMind的多人博弈游戏研究
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
DeepMind这次不下棋,也不搞电子游戏,而是研究了一把多人博弈游戏。
最新开发的“Democratic AI”——通过训练学习人类价值观,进而能根据每个人的贡献公平地分配资源。
为了论证这一概念,DeepMind设计了一个简单的投资游戏,由AI和人类分别担任裁判,让玩家们票选出更喜欢的分配规则,Democratic AI甚至获得了比人类裁判更高的支持率。
AI裁判比人类更受欢迎
当一群人决定集中资金进行投资时,收益应该如何分配是一个必须面对的大问题。
一个简单的策略是在投资者之间平均分配回报,但这很可能是不公平的,因为有些人的贡献比其他人多。
第二个方案是,我们可以根据每个人的初始投资多少进行分配,这听起来很公平,但如果人们一开始的资产水平各不相同呢?
如果两个人贡献了相同的金额,但一个是他们可用资金的一小部分,另一个则贡献了他的全部资产,他们应该获得相同的收益份额吗?
为了应对这一挑战,DeepMind创建了一个简单的多人投资游戏。
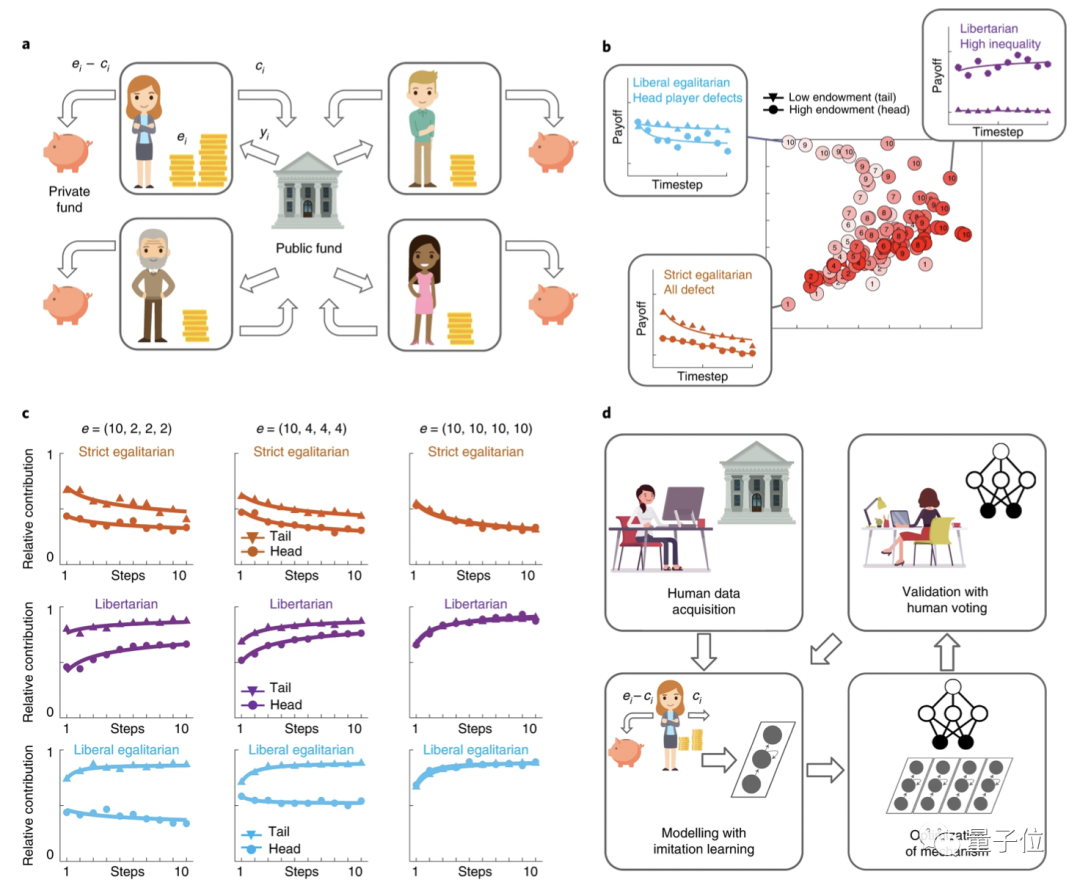
游戏涉及4名玩家,共分成10轮。
每个玩家都会被分配初始资金,在每一轮中,玩家可以按自己的意愿做出选择:自己保留,或者将其投资于一个共同的池中。
投资肯定会有回报,但存在一个风险——玩家不知道最终收益将如何分配。
除此之外,他们被告知,前10轮有一名裁判(A)做出分配决策,而后10轮,由不同的裁判(B)接手。
比赛结束时,他们将投票给A或B,来决定自己还想与哪位裁判再来一场游戏。
而这最后一次游戏的收益可以由玩家们自己保留,这将使玩家们更主动地选出自己心中最公正的裁判。
事实上,其中一位裁判是按照预先设定的分配规则执行,另一边是由Democratic AI自行设计。
当我们研究这些玩家的投票时,我们发现AI设计的规则比标准分配规则更受欢迎。
与此同时,DeepMind还请来了一位人类裁判,并给他介绍规则、让他尽量做到公平分配以拉选票,但最终投票结果显示,他还是输给了Democratic AI。
Democratic AI为什么能赢?
在DeepMind最新发表于Nature子刊Nature Human Behaviour的论文中,记录了研究人员对Democratic AI的训练过程。

首先,他们让4000多名人类玩家在不同的分配规则下多次参加游戏,并投票选择更喜欢哪种分配方法。
这些数据用于训练AI来模仿游戏中的人类行为,包括玩家投票的方式。
其次,研究人员让这些AI玩家在数千场比赛中相互竞争,而另一个AI系统根据AI玩家的投票方式继续调整再分配规则。
于是,在这个过程结束时,AI已经确定了非常接近公平的再分配规则:
首先,AI选择根据相对贡献而不是绝对贡献的比例进行分配。这意味着,在重新分配资金时,AI会考虑每个玩家的初始金额以及他们投资的意愿。
其次,AI系统特别奖励了相对贡献更慷慨的玩家,以此鼓励其他人也这样做。重要的是,人工智能只有通过最大化学习人类投票率才能发现这些规则。
这个方法能推广到现实吗?
虽然DeepMind的游戏测试取得了亮眼的成绩,但要想将这种方法从简单的四人游戏转换为大规模经济体系,仍具有巨大的挑战性,目前还不能确定它在现实世界中会如何发展。

其次,研究人员自己发现了几个潜在的问题。
Democratic的一个问题是可能会发展为“多数人的暴政”,这将导致对少数群体的现有歧视或不公平模式持续存在。
AI需要做更多的工作来了解如何通过设计允许所有人的声音都能被听到。
另外,研究人员还提出了人们对AI的信任问题:
人们是否会信任由AI设计的机制来代替人类?如果人们知道裁判的身份,会不会影响最终的投票结果?
如果要将Democratic AI设计的解决方案应用于解决现实世界的困境,这一点至关重要。
参考链接:
[1]https://www.deepmind.com/publications/human-centred-mechanism-design-with-democratic-ai
[2]https://www.nature.com/articles/s41562-022-01383-x
[3]https://singularityhub.com/2022/07/04/deepminds-new-ai-may-be-better-at-distributing-societys-resources-than-humans-are/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



