兴军亮Science评述:多人德州扑克博弈新突破

解锁更多智能之美
Science 评述:
多人扑克博弈新突破
评述论文:Superhuman AI for multiplayer poker (N. Brown and T. Sandholm, Science 10.1126/science.aay2400 (2019).)
【摘要】人工智能算法能在多人扑克比赛中战胜人类专业选手吗?自动化所兴军亮研究员对在六人无限注德州扑克中战胜13名人类专业选手的最新算法进行了评述。
在过去十多年间,人工智能技术得到了飞速发展,在语音转文本、图像识别、机器翻译等很多特定任务中,智能算法都达到或超过了人类的感知能力(即判断是什么的能力)。随着计算机感知能力的不断提升,研究者开始更多关注于如何提升机器的认知能力(即推理为什么的能力)。
作为衡量机器认知水平的重要途径,游戏博弈能力被广泛地用来作为机器智能发展水平的测评基准和里程碑。从早期的西洋双陆棋、国际象棋,到最近的围棋、德州扑克、星际争霸、Dota 2等,每一次技术上的突破都产生了强烈反响。
相对于国际象棋、围棋等棋类游戏以及星际争霸、Dota 2等实时策略游戏,以德州扑克为代表的扑克游戏由于同时具备不完全信息动态决策、对手误导欺诈行为识别、以及多回合筹码和风险管理等特点,而备受人工智能研究者关注。在2015年,加拿大阿尔伯塔大学的迈克尔·鲍林(Michael Bowling)教授带领团队提出了一种称之为CFR+的算法[1],解决了两人有限注德州扑克问题,2017年,迈克尔·鲍林教授团队和卡内基梅隆大学的图奥马斯·桑德赫尔(Tuomas Sandholm)教授团队相继提出的DeepStack算法[2]和Libratus算法[3],同时解决了两人无限注德州扑克博弈问题。
这里的解决是指不仅在博弈水平上击败了人类顶尖选手,而且在理论上证明了能够战胜或战平任意对手。然而,对于多人无限注德州扑克而言,之前还没有算法能够战胜人类专业选手,更没有理论结果保证不会输给任意对手。

本期的《科学》杂志在线发表了图奥马斯·桑德赫尔教授团队的最新研究成果:在多人无限注德州扑克中战胜了人类专业选手。图奥马斯·桑德赫尔教授团队以六人无限注德州扑克这一最为常见的多人无限注德州扑克形式作为示例,提出了一种称之为Pluribus的多人无限注德州扑克博弈算法。
与之前谷歌DeepMind团队提出的AlphaGo Zero算法类似,Pluribus算法的核心同样是不使用人类数据或者经验,仅仅通过算法的自我博弈来不断学习和提升策略的胜率。
与AlphaGo Zero不同的是,Pluribus需要同时和5个“自己”进行博弈,另外,在自我博弈的过程中,由于德州扑克的特点,还需要在不完全信息条件下进行策略学习和决策。Pluribus算法通过离线自我博弈得到的策略被称之为蓝图策略(Blueprint Strategy),在在线博弈阶段,Pluribus还会实时分析自身所处的局势,并通过实时搜索来改进蓝图策略,从而提高策略的适应性和博弈水平。
在实验中,Pluribus程序与11名人类专业选手轮流进行1机+5人的比赛,共打了10,000盘,结果Pluribus战胜了所有人类选手,赢了最多的筹码。同时,Pluribus自身复制了五份,与两名人类选手分别进行5机+1人的比赛,总共也打了10,000盘,Pluribus同样战胜了两名人类选手,赢得了更多筹码。
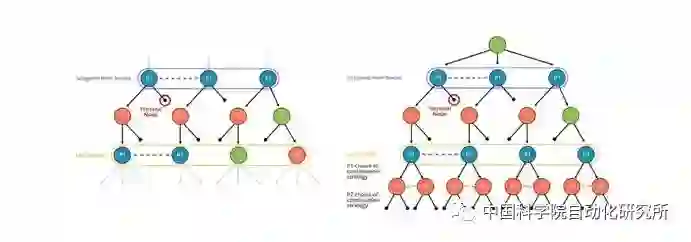
Pluribus算法主要包括三个过程:非完美信息博弈过程的抽象压缩、博弈策略的离线自博弈学习、以及博弈策略的在线实时搜索改进。其中博弈过程的抽象压缩是为了减少博弈决策空间的大小,博弈策略的离线子博弈学习是为了学习得到博弈的蓝图策略,而博弈策略的在线实时搜索改进则是为了针对特定的博弈形势,通过精准搜索改进蓝图策略,提升在线博弈水平。
这三个过程与团队之前针对两人无限注德州扑克博弈设计的智能程序Libratus算法过程类似,Pluribus在技术上的创新点主要是针对多人无限注德州扑克的特点,对博弈策略的离线自博弈学习过程和在线搜索过程进行了相应改进。
由于多人无限注德州扑克的博弈树分支数量巨大,无法穷举搜索,因此Pluribus在离线自博弈过程中使用了一种改进的蒙特卡洛反事实后悔值(Monte Carlo CounterFactual Regret,MCCFR)最小化方法,该方法在博弈树的每个节点只进行采样搜索,提高了搜索的效率,通过多次迭代优化,不断减少当前策略价值与可能的最优策略价值之间差值(后悔值),从而使得当前策略的期望胜率不断提升。
在在线实时搜索改进过程中,离线学习得到的蓝图策略只用于德州扑克第一次下注过程的搜索,在后面三次下注过程都使用了实时的在线搜索算法。为了防止搜索得到的策略过于单一而被对手利用,Pluribus使用了一种改进型的在线搜索算法(图1)。在每次搜索过程中,Pluribus没有假设对手都使用一种固定策略,而是假设对手可以随机使用k种不同的策略,这样在策略搜索和评估过程中都会同时考虑k种不同的可能,大大增强了搜索策略的灵活性,使得对手无法轻易获取Pluribus策略的弱点,进而提升了策略的最终胜率。
Pluribus算法的研究结果表明,即使在理论上还没有证明多人无限注德州扑克最优策略如何获取的情况下,通过精心设计的机器学习算法能够在最常见的六人无限注德州扑克中击败人类专业选手,从而再一次展现了机器智能算法在计算、搜索、评估和学习方面的强大能力。至于如何在理论上证明多人无限注德州扑克的最优策略是否存在、如果存在怎样去计算、以及与博弈的均衡策略之间的关系等问题,还需要研究者继续进行不断的探索。

http://science.sciencemag.org/cgi/doi/10.1126/science.aay2400
参考文献:
1. Michael Bowling, Neil Burch, Michael Johanson, and Oskari Tammelin. Heads-up limit Hold'em poker is solved. Science, vol. 347, no. 6218, pp. 145-149, 2015.
2. Matej Moravk, Martin Schmid, Neil Burch and, Viliam Lis, Dustin Morrill, Nolan Bard, Trevor Davis, Kevin Waugh, Michael Johanson, and Michael Bowling. DeepStack: Expert-level artificial intelligence in heads-up no-limit poker. Science, vol. 359, pp. 418-424, 2017.
3. Noam Brown and Tuomas Sandholm. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science, vol. 359, pp. 418-424, 2017.

作者简介


更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
作者:兴军亮
编辑:鲁宁
排版:刘琪






