博弈论视角下的多智能体强化学习综述,129页pdf与76页Slides

继AlphaGO系列的巨大成功之后,2019年是一个蓬勃发展的一年,见证了多智能体强化学习(MARL)技术的重大进展。MARL对应于多智能体系统中多个智能体同时学习的学习问题。这是一个具有悠久历史的跨学科领域,包括博弈论、机器学习、随机控制、心理学和优化。尽管MARL在解决现实世界的游戏方面取得了相当大的经验上的成功,但文献中缺乏一个完整的概述来阐述现代MARL方法的博弈理论基础,并总结最近的进展。事实上,现有的大多数综述都是过时的,没有完全涵盖2010年以来的最新发展。在这项工作中,我们提供了一个关于MARL的专著,包括基本原理和研究前沿的最新发展。本综述分为两部分。从§1到§4,我们介绍了MARL的完备的基础知识,包括问题公式、基本解决方案和现有的挑战。具体地说,我们通过两个具有代表性的框架,即随机博弈和广义博弈,以及可以处理的不同博弈变体,来呈现MARL公式。这一部分的目的是使读者,即使是那些相关背景很少的人,掌握MARL研究的关键思想。从§5到§9,我们概述了MARL算法的最新发展。从MARL方法的新分类开始,我们对以前的研究论文进行了调研。在后面的章节中,我们将重点介绍MARL研究中的几个现代主题,包括Q函数分解、多智能体软学习、网络化多智能体MDP、随机潜在博弈、零和连续博弈、在线MDP、回合制随机博弈、策略空间响应oracle、一般和博弈中的近似方法、以及具有无限个体的游戏中的平均场类型学习。在每个主题中,我们都选择了最基础和最先进的算法。我们调研的目的是从博弈理论的角度对当前最先进的MARL技术提供一个完备的评估。我们希望这项工作能够为即将进入这个快速发展的领域的新研究人员和现有的领域专家提供一个跳板,他们希望获得一个全景视图,并根据最近的进展确定新的方向。
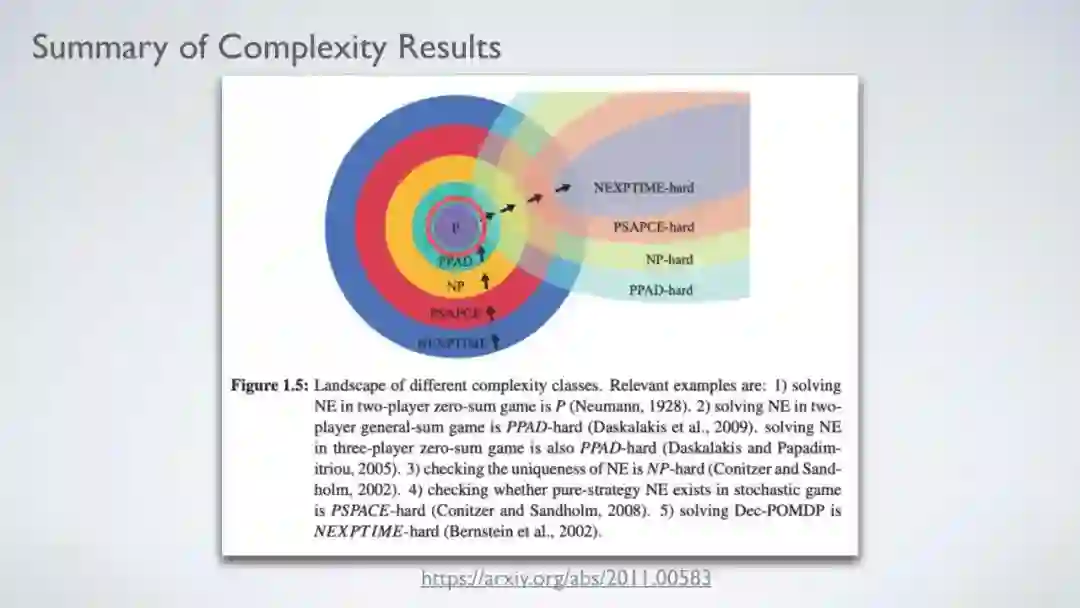





https://arxiv.org/abs/2011.00583
引言
机器学习可以看作是将数据转换为知识的过程(Shalev-Shwartz & Ben-David, 2014)。学习算法的输入是训练数据(例如,含有猫的图像),输出是一些知识(例如,关于如何在图像中检测猫的规则)。这些知识通常表示为能够执行某些任务的计算机(例如,自动猫探测器)。在过去的十年中,一种特殊的机器学习技术——深度学习(LeCun et al., 2015)取得了长足的进步。深度学习的一个重要体现的是不同种类的深层神经网络(DNNs)(Schmidhuber, 2015),可以找到分离表示(Bengio, 2009)在高维数据, 这使得软件训练本身执行新任务而不是仅仅依赖于程序员手工设计规则。通过使用DNNs,计算机视觉(Krizhevsky et al., 2012)和自然语言处理(Brown et al., 2020; Devlin et al., 2018)是取得了显著的进展。
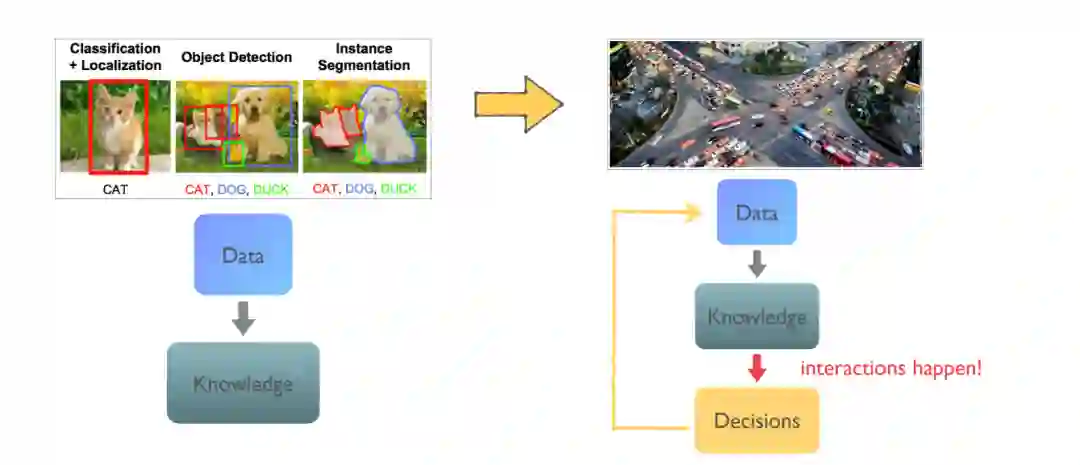
现代人工智能应用正在从纯粹的特征识别(例如,在图像中检测一只猫)转变为决策(安全通过交通十字路口),其中不可避免地会发生多个智能体之间的交互。因此,每个智能体都必须采取战略性的行为。此外,这个问题变得更具挑战性,因为当前的决定会影响未来的结果。
除了从现有数据进行特征识别,现代人工智能应用通常需要计算机程序根据所获得的知识做出决策(见图1)。为了说明决策的关键组成部分,让我们考虑现实世界中控制汽车安全通过十字路口的例子。在每一个时间步,机器人汽车都可以通过转向、加速和制动来移动。目标是安全驶出十字路口并到达目的地(可以选择直走或左转/右转入另一条车道)。因此,除了能够检测对象,如交通信号灯、车道标记,和其他汽车(通过将数据转化为知识),我们的目标是找到一个能控制汽车的方向盘政策做出一系列演习达到目标(决策基于获得的知识)。在这样的决策环境中,还会出现两个额外的挑战:
历史上,RL机制最初是在研究猫在谜盒中的行为的基础上发展起来的(Thorndike, 1898)。Minsky(1954)在他的博士论文中首次提出了RL的计算模型,并将他得到的模拟机器命名为随机神经模拟强化计算器。几年后,他首先提出了动态规划(Bellman, 1952)和RL (Minsky, 1961)之间的联系。在1972年,Klopf(1972)将试错学习过程与心理学中发现的时间差异(TD)学习结合起来。在为更大的系统扩展RL时,TD学习很快成为不可或缺的。Watkins & Dayan(1992)在动态规划和TD学习的基础上,使用马尔可夫决策过程(MDP)为今天的RL奠定了基础,并提出了著名的Q-learning方法作为求解器。作为一种动态规划方法,原来的Q-learning过程继承了Bellman (Bellman, 1952)的“维数灾难”(curse of dimensional维数灾难),当状态变量数量较大时,极大地限制了它的应用。为了克服这一瓶颈,Bertsekas & Tsitsiklis(1996)提出了基于神经网络的近似动态规划方法。最近,来自DeepMind的Mnih等人(2015)通过引入深度q -学习(DQN)架构取得了重大突破,该架构利用了DNN对近似动态规划方法的表示能力。DQN已经在49款Atari游戏中展示了人类水平的表现。从那时起,深度RL技术在机器学习/人工智能中变得普遍,并引起了研究社区的大量关注。
RL源于对动物行为的理解,动物使用试错法来强化有益的行为,然后更频繁地执行这些行为。在其发展过程中,计算RL整合了诸如最佳控制理论和其他心理学发现等思想,这些思想有助于模仿人类做出决策的方式,从而使决策任务的长期收益最大化。因此,RL方法自然可以用来训练计算机程序(代理),使其在某些任务上达到与人类相当的性能水平。RL方法对人类玩家的最早成功可以追溯到西洋双陆棋(Tesauro, 1995)。最近,应用RL解决顺序决策问题的进展标志着AlphaGo系列的显著成功(Silver et al., 2016;2017;2018年),一名自学的RL智能体,击败了围棋游戏的顶级专业玩家,这款游戏的搜索空间(10761种可能的游戏)甚至比宇宙中的原子数量还要多。

AlphaGo系列的成功标志着单agent决策过程的成熟。2019年是MARL技术蓬勃发展的一年;在解决极具挑战性的多人实战策略电子游戏和多人不完全信息扑克游戏方面取得了显著进展。
事实上,大多数成功的RL应用,如游戏GO2、机器人控制(Kober et al., 2013)和自动驾驶(Shalev-Shwartz et al., 2016),自然涉及多个人工智能智能体的参与,这探索了MARL领域。正如我们所预期的,单agent RL方法取得的重大进展——以2016年GO的成功为标志——预示着未来几年多agent RL技术的突破。
强化学习多智能体兴盛
2019年是MARL发展的繁荣之年,在过去人们认为不可能通过人工智能解决的极具挑战性的多智能体任务上取得了一系列突破。尽管如此,MARL领域取得的进展,尽管令人瞩目,但在某种程度上已经被AlphaGo之前的成功所掩盖(Chalmers, 2020)。AlphaGo系列有可能(Silver et al., 2016;2017;2018年)已经在很大程度上满足了人们对RL方法有效性的期望,因此对该领域的进一步发展缺乏兴趣。MARL的进展在学术界引起的反响相对温和。在本节中,我们将重点介绍几项工作,我们认为这些工作非常重要,并且可能深刻影响MARL技术的未来发展。
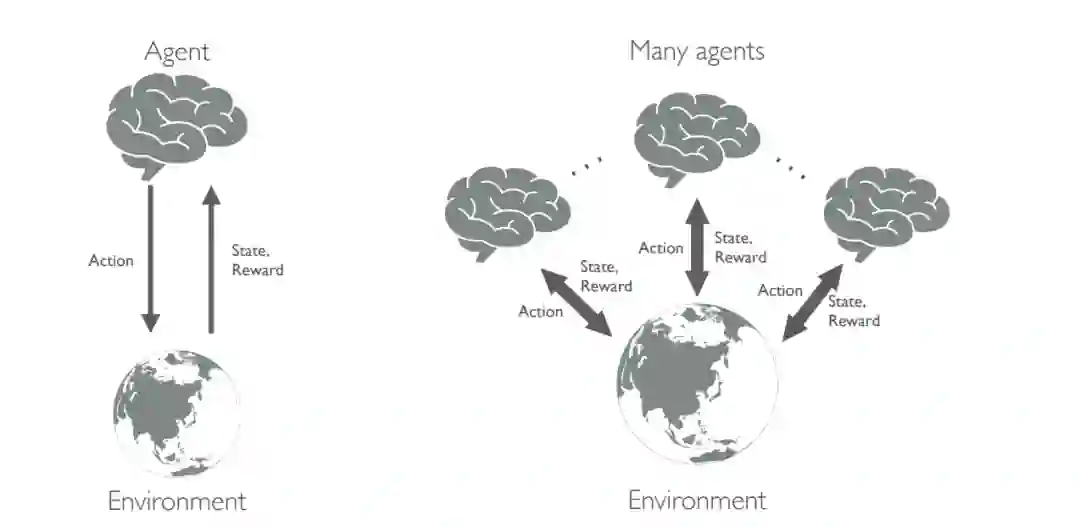
单代理MDP(左)和多代理MDP(右)示意图
MARL的一个热门测试平台是星际争霸2 (Vinyals等人,2017年),这是一款拥有自己职业联赛的多人即时策略电脑游戏。在这个博弈中,每个参与人关于博弈状态的信息都是有限的,而且搜索空间的维度比围棋大了几个数量级(每一步有1026种可能的选择)。《星际争霸2》中有效的RL方法的设计曾一度被认为是人工智能的一个长期挑战(Vinyals等人,2017)。然而,AlphaStar在2019年实现了突破(Vinyals et al., 2019b),它已经展示了特级大师水平的技能,排名超过人类玩家的99.8%。
MARL的另一个著名的基于视频游戏的测试平台是Dota2,这是一个由两支队伍玩的零和游戏,每支队伍由5名玩家组成。从每个agent的角度来看,除了不完全信息的难度(类似于星际争霸2),Dota2更具挑战性,在这个意义上,团队成员之间的合作和与对手的竞争都必须考虑。OpenAI Five人工智能系统(Pachocki et al., 2018)在一场公开的电子竞技比赛中击败了世界冠军,在Dota2中展现了超人的表现。除了星际争霸2和Dota2, Jaderberg等人(2019)和Baker等人(2019a)分别在抓旗和捉迷藏游戏中表现出了人类水平的表现。虽然游戏本身不如星际争霸2或Dota2复杂,但对于人工智能agent来说,掌握战术仍然不是一件容易的事情,所以agent令人印象深刻的表现再次证明了MARL的有效性。有趣的是,两位作者都报告了由他们提出的MARL方法引发的紧急行为,人类可以理解,并以物理理论为基础。
MARL最后一个值得一提的成就是它在扑克游戏《Texas hold ' em》中的应用,这是一种多玩家广泛形式的游戏,玩家可以获得不完整的信息。Heads-up(即两个玩家)无限持有的游戏中有超过6 × 10161种信息状态。直到最近,游戏中才出现了突破性的成就,这多亏了MARL。两个独立的程序,DeepStack (Moravčík等人,2017)和Libratus (Brown & Sandholm, 2018),能够击败专业的人类玩家。最近,Libratus被升级为Pluribus (Brown & Sandholm, 2019年),并表现出非凡的表现,在无限制设置中赢得了5名精英人类专业人士的100多万美元。为了更深入地理解RL和MARL,需要对概念进行数学表示法和解构。在下一节中,我们将提供这些概念的数学公式,从单代理RL开始,逐步发展到多代理RL方法。
单智能体强化学习
多智能体强化学习
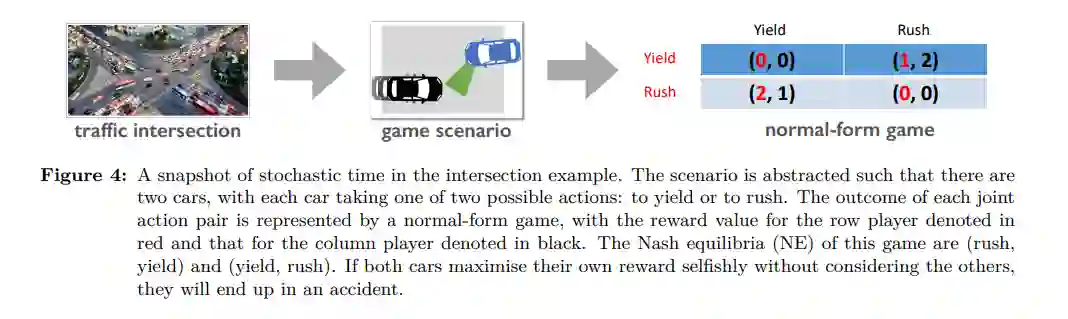
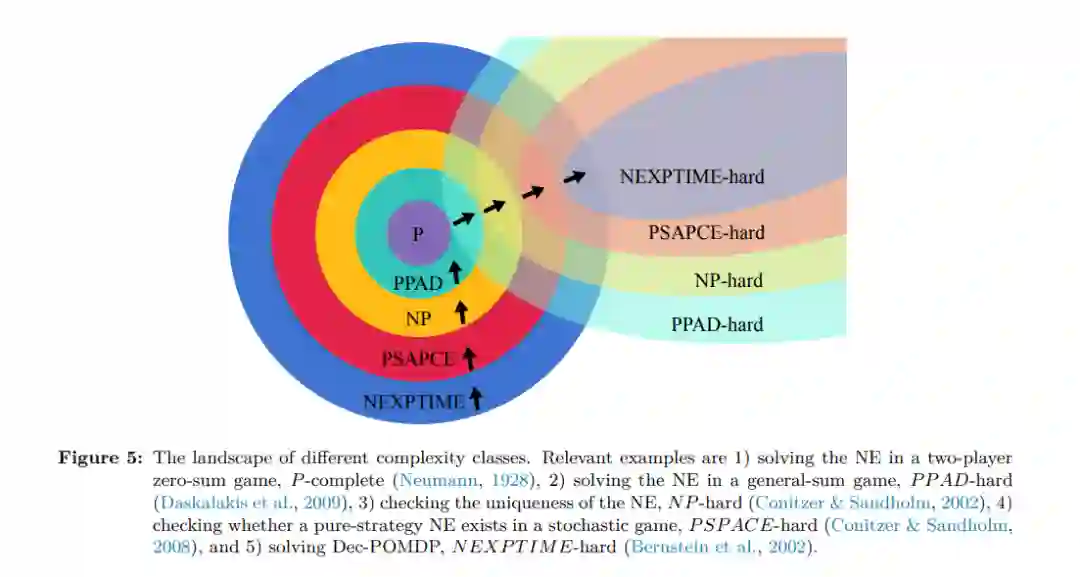
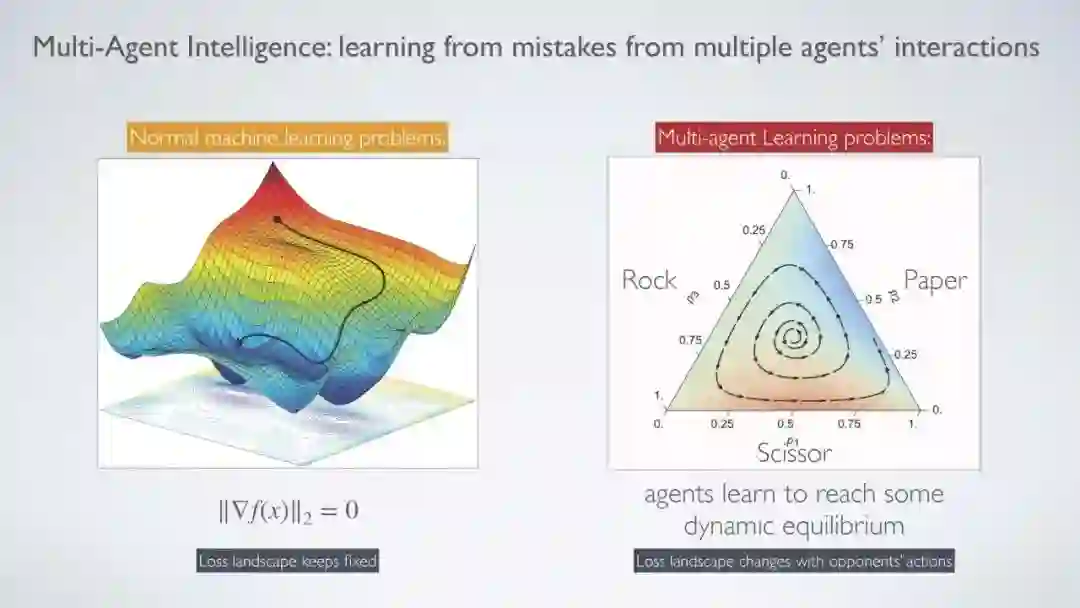
与单agent RL相比,多agent RL是一个更适合现实世界AI应用的通用框架。然而,由于多个agent同时学习的存在,除了单agent RL中已经存在的方法外,MARL方法提出了更多的理论挑战。与通常有两个代理的经典MARL设置相比,解决多代理RL问题更具挑战性。事实上,1 组合复杂性,2 多维学习目标和3 非平稳性问题都导致大多数MARL算法能够解决只有4个参与者的博弈,特别是两方零和博弈。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GMAR” 就可以获取《博弈论视角下的多智能体强化学习综述,129页pdf与76页Slides》专知下载链接




