

视觉语言任务,如回答关于图像的问题或生成描述图像的标题,对计算机来说是一项难以完成的任务。近期的一系列研究已将Vaswani等人在2017年引入的预训练Transformer架构适应于视觉语言建模。Transformer模型在性能和通用性上都大大优于以前的视觉语言模型。它们通过在大型通用数据集上预训练模型,并将学习成果转移到新任务上,而这只需要对架构和参数值进行微小的改变。这种转移学习已经成为自然语言处理和计算机视觉中的标准建模实践。视觉语言Transformer模型有望在需要视觉和语言的任务中产生类似的进步。在这篇论文中,我们提供了当前可用的视觉语言Transformer模型研究的广泛综述,并对它们的优势、局限性以及一些仍未解决的问题进行了一些分析。
视觉语言建模是计算机视觉和自然语言处理交汇的领域。视觉语言任务的一个例子是视觉问题回答:给定一张图片和一个关于图片的问题,视觉语言模型必须从多个选项中选择正确的答案。另一个例子,也是更具挑战性的任务,是图像标题生成,给定一张图片,模型必须产生描述该图片的文本序列。尽管对人类来说这些任务轻而易举,但历史上这种性质的任务对计算机来说极具挑战性。直到最近,用于视觉语言任务的深度学习模型往往在概念上复杂且仅限于狭窄的应用范围。
在过去的几年里,一种被称为视觉语言(VL)变换器的新型模型极大地扩展了视觉语言模型的准确性和多功能性。这些模型基于Vaswani等人在2017年引入的广受赞誉的变换器架构。视觉语言变换器通过在大型的图像-文本对数据集上预训练模型,然后将其转移到其他任务(通常需要对参数值和架构进行微小的改变)上,从而改进了之前的模式。在很短的时间里,这些模型在文献中出现的数量令人眼花缭乱。它们在预期的用途、架构、预训练过程以及用来预训练的数据上差异很大。在这篇论文中,我们提供了一份文献中各种视觉语言变换器模型的全面调查。这些模型被设计用于广泛的视觉语言任务。像CLIP(Radford等人,2021年)和ALIGN(Jia等人,2021年)这样的模型特别适合于视觉语言对齐任务,如图像检索。而像UNITER(Chen等人,2019年)、ViLBERT(Lu等人,2019年)和METER(Dou等人,2022年)这样的模型擅长于理解任务,例如在引言段落中描述的视觉问题回答(VQA)。有些具有适当架构的变换器,如LEMON(Hu等人,2022年)和GIT(Wang等人,2022a),被设计用来生成文本,如为图像输入生成标题。甚至还有一系列专门用于视觉定位任务的视觉语言变换器,其中模型必须将单词与它们描述的视觉对象匹配。Referring Transformer和mDETR就是两种可以在图像输入上执行对象检测并将这些对象与文本描述匹配的模型。
出于简洁考虑,我们将研究限制在使用英语作为主要语言的模型上。这不仅排除了使用其他语言文本的模型,也排除了多语言模型。我们还排除了专门为视频语言任务设计的模型。但需要注意的是,我们审查的一些模型处理的输入既包括视频也包括图像。而且,有一个多语言模型PaLI(Chen等人,2022年)由于在英语语言视觉语言基准测试中的出色性能而被包含进来。上述令人印象深刻的任务范围反映出同样令人印象深刻的嵌入策略、模型架构、预训练任务和训练数据集的多样性。我们将详细讨论这些话题以及这些特征可以如何适应视觉语言领域的各种方式。在此过程中,我们希望能提供对这些模型的各种设计选择的一些理解,以及当存在足够数据时,这些选择对模型性能的相应影响。本文审查的所有模型都列在表1中,表中还提供了每个模型的引用文献以及关于它们设计的一些基本信息。
本文的其余部分按如下方式组织:在第2部分,我们简要解释了构成我们所审查的模型基础的变换器模型,以及预训练的变换器如何被适应用于自然语言处理(NLP)和计算机视觉(CV)任务。在第3部分,我们讨论了视觉语言模型如何将视觉和语言数据嵌入到其特征空间中,特别关注它们是如何创建视觉特征的。第4部分讨论了审查模型的架构以及这些设计选择是如何影响视觉和语言特征的交互的。这些模型使用的各种预训练任务和策略以及它们如何影响下游性能在第5部分中进行了总结。第6部分描述了模型的下游能力,第7部分描述了用于预训练的数据。在最后一部分,我们对讨论的模型的优点和局限性进行了简要分析,并探讨了研究的未来方向,并指出了仍存在的未解决问题。
**2 背景:**Transformers 在这一部分,我们将描述构成我们以下讨论的视觉语言模型的架构基础的Transformers风格的深度神经模型。Transformers首次在Vaswani等人(2017年)的开创性论文《Attention Is All You Need》中被引入,该论文讨论的是在机器翻译任务中使用注意力机制的情境。自那时起,Transformers已经取代了递归神经网络(RNN)成为大多数自然语言处理任务的标准模型。自然语言处理的Transformers通过在大型未标注的文本集上预训练网络,然后将预训练的网络通过微小的架构改变和最小的参数更新转移到其他任务,从而实现了显著的结果。像RoBERTa(Liu等人,2019年)和GPT-3(Brown等人,2020年)这样的预训练Transformers模型,现在几乎在每个类别的自然语言处理任务中都是最先进的。卷积神经网络(CNN)在本文撰写时仍被广泛用于计算机视觉任务。然而,近期的研究表明,Transformers架构可以用相对较少的修改适应计算机视觉任务(Dosovitskiy等人,2020年;Touvron等人,2021年)。当使用足够大的数据集预训练时,视觉Transformers可以与为计算机视觉设计的最先进的CNNs竞争。鉴于它们在两个领域都能达到或接近最先进的水平,Transformers自然成为预训练视觉语言模型的基础。在我们讨论如何调整Transformers以适应视觉语言任务的设计选择之前,我们将简要概述Transformers模型和驱动其显著结果的注意力机制。熟悉Transformers和它们在自然语言处理和计算机视觉应用的工作原理的读者可以直接跳到下一部分。
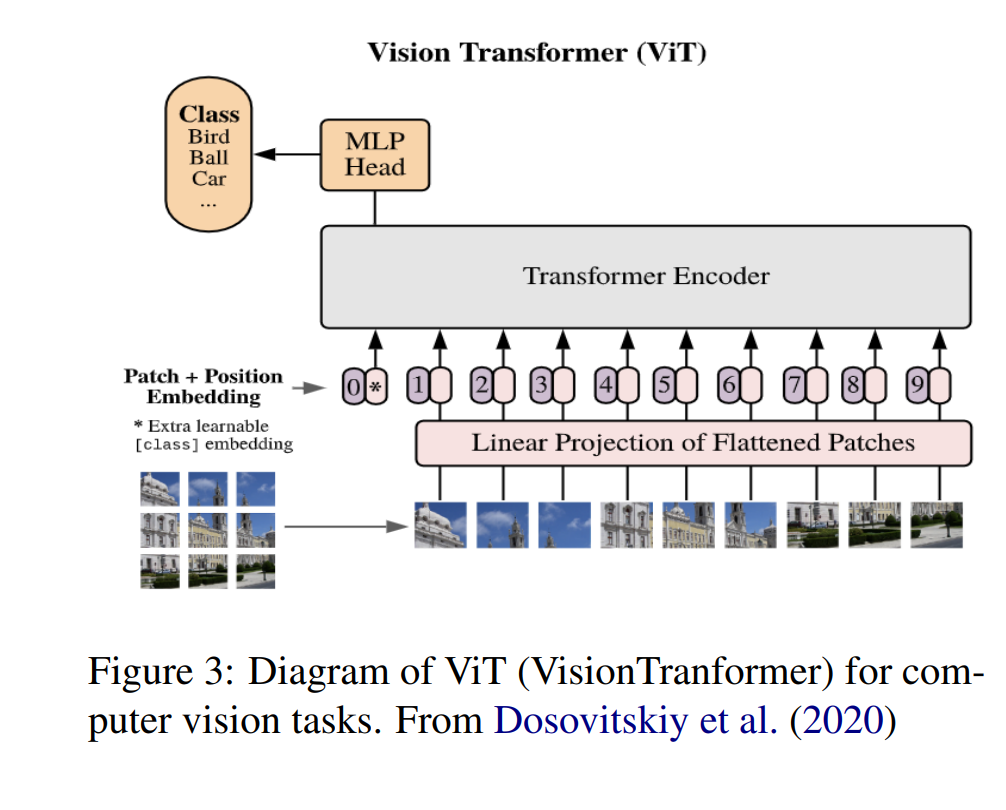
**3 嵌入策略 **在这一部分,我们讨论视觉语言Transformer模型如何将其文本和视觉嵌入编码到模型的特征空间中。形式上,文本和视觉输入必须被编码成一系列的文本标记 {t1, ....tT }和一系列的视觉特征 {v1, ..., vV },其中每个序列元素都是一个数值向量。几乎所有我们为本文审查的模型都采用相同的文本表示嵌入策略,这一策略将在下面的子部分中详细描述。然而,表示图像的策略有很大的差异,这也是预训练视觉语言模型的关键差异之一,我们将在以下部分详细讨论这个主题。
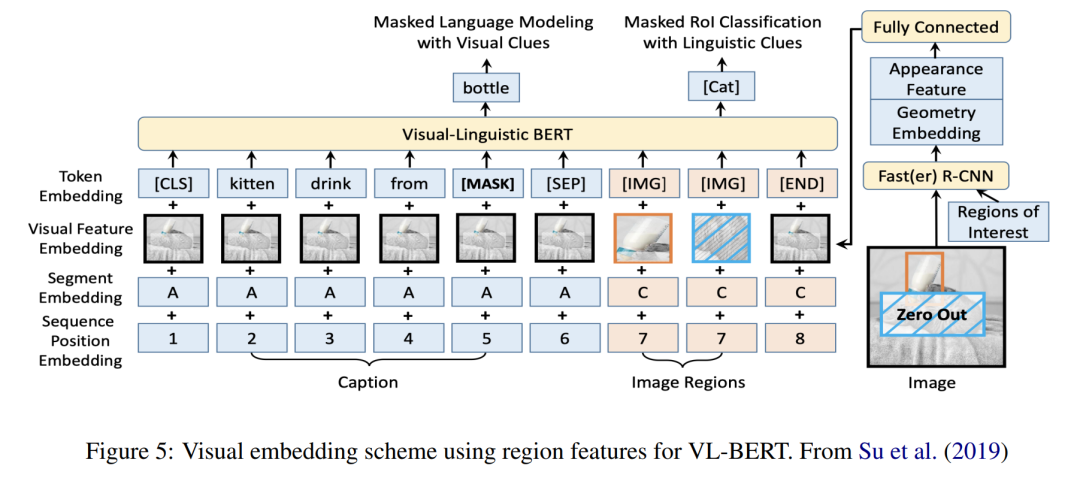
**4 模型架构 **无论采用何种嵌入策略,视觉语言模型的模型架构必须允许与文本和视觉模式相关的特征以某种方式交互。在这一部分,我们将描述预训练视觉语言Transformer模型用于联合表示视觉和语言的不同模型设计。从最广义的角度来看,预训练视觉语言模型可以根据这种交互是通过浅层交互(如点积)实现的,还是在深度学习模型本身中发生的来进行分类。在使用深度交互的模型中,架构采用单塔编码器、双塔编码器或编码器-解码器设计。按照 Bao 等人(2022)的说法,我们将使用浅层交互的模型称为双编码器。这些架构将在下面的子部分中详细描述,并提供可用的视觉语言模型的显著示例。
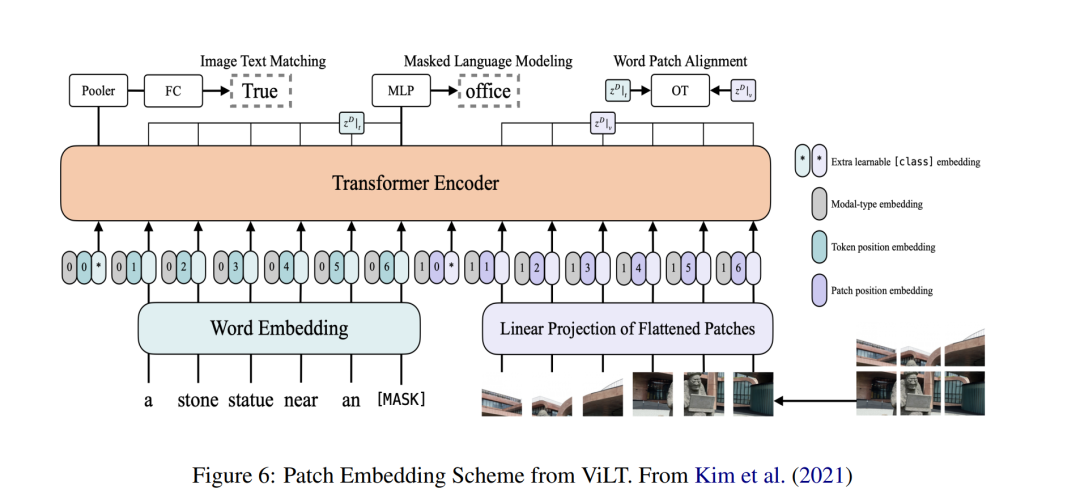
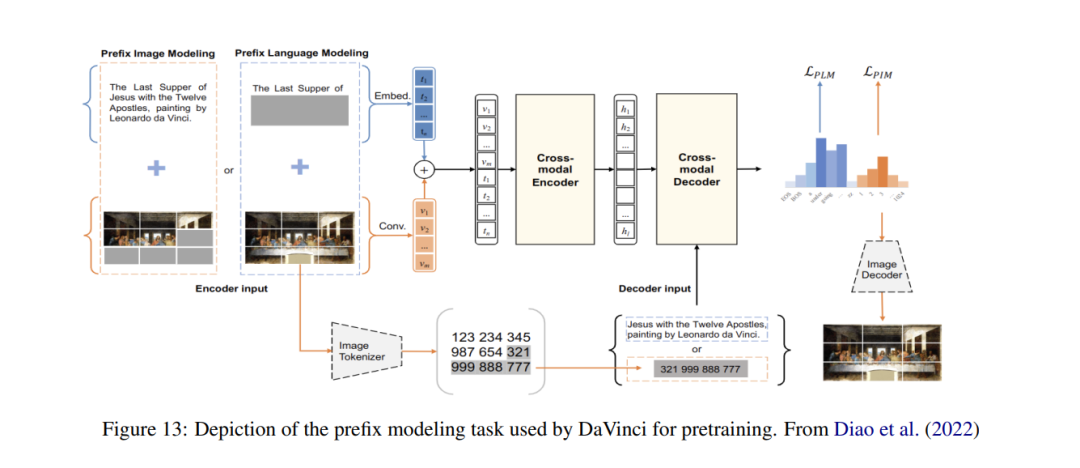
**5 预训练任务 **本节专门讨论各种视觉语言Transformer使用的预训练任务。预训练是这些模型成功的关键元素,我们将花费大量的空间来描述这些方法。几乎所有的融合和组合编码器模型都使用了掩蔽语言模型和图像文本匹配,这两种都是BERT自然语言处理模型(Devlin等人,2018)中使用的预训练目标的扩展。在下文中,我们将详细描述这些任务,以及相关文献中找到的几个额外目标。
**6 下游能力 **原则上,我们讨论的大多数模型都可以通过对模型架构进行适当的调整和微调来适应几乎任何给定的视觉语言任务。然而,许多模型明确地为某些视觉语言能力而设计和测试。例如,双编码器非常适合对齐任务,如文本到图像的检索。地面变压器,例如mDETR或Referring Transformer,接受了大量的视觉接地任务的训练和评估。在本节中,我们将简要介绍模型创造者在预训练、零镜头评估或微调其模型时涵盖的视觉语言任务的范围。在此过程中,我们将有机会参考每种类型任务的一些主要基准。

