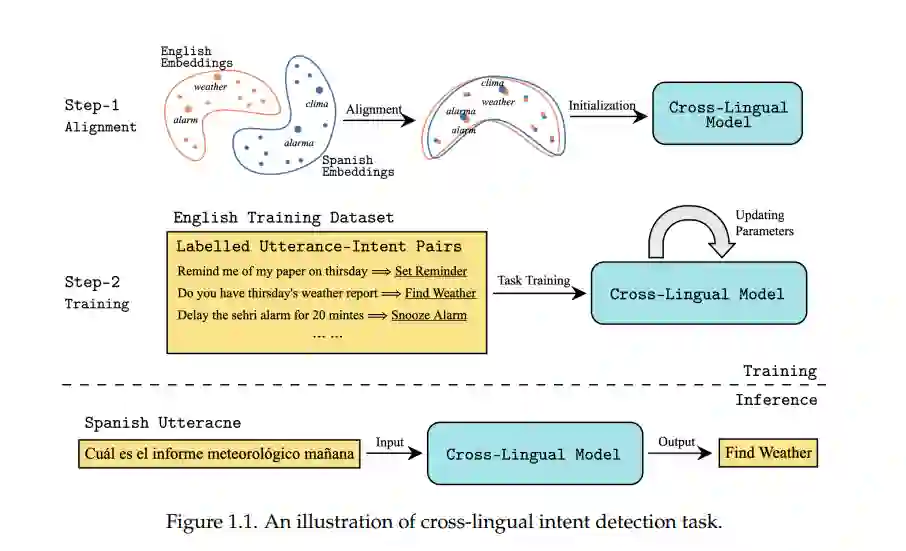
自然语言理解是机器对人类语言进行语义解码的任务。NLU允许用户使用自然句子与机器进行交互,是任何自然语言处理(NLP)系统的基础组件。尽管机器学习方法(尤其是深度学习)在NLU任务上取得了显著的成就,但它们仍然严重依赖于大量的训练数据来确保良好的性能,不能很好地泛化到训练数据很少的语言和领域。对于互联网上具有大量文本数据的高资源语言(如英语、中文),获取或收集海量数据样本相对容易。然而,许多其他语言的在线足迹很小(例如,互联网上不到0.1%的数据资源是泰米尔语或乌尔都语)。这使得收集这些低资源语言的数据集变得更加困难。同样,低资源领域(如罕见疾病)的数据集也比高资源领域(如新闻)的数据集更具有挑战性,因为这些领域的数据资源和领域专家很少。为了让机器更好地理解低资源语言和领域中的自然句子,有必要克服数据稀缺的挑战,因为只有很少甚至没有训练样本可用。
跨语言和跨领域迁移学习方法已经被提出,从高资源语言和领域的大型训练样本中学习任务知识,并将其迁移到低资源语言和领域。然而,以往的方法未能有效地解决开发跨语言和跨领域系统的两个主要挑战,即:1)难以从低资源的目标语言(域)中学习良好的表示;2)由于语言(领域)之间的差异,任务知识很难从高资源源语言(领域)转移到低资源目标语言(领域)。如何在深度学习框架下应对这些挑战,需要进行新的研究。
在这篇论文中,我们专注于在深度学习框架中解决上述挑战。首先,我们提出进一步细化跨语言的任务相关关键词的表示。我们发现,通过只关注关键词,低资源语言的表示可以很容易地得到很大的改进。其次,我们提出了一个用于跨语言自适应的Transformer ,发现建模部分语序而不是整个语序可以提高模型对语言语序差异和任务知识向低资源语言迁移的鲁棒性。第三,我们提出在训练前利用不同层次的领域相关语料库和额外的数据掩蔽来进行跨领域适应,并发现更具挑战性的训练前可以更好地解决任务知识转移中的领域差异问题。最后,我们引入了一个从粗到细的框架Coach,以及一个跨语言和跨领域的解析框架X2Parser。Coach将表示学习过程分解为粗粒度和细粒度特征学习,X2Parser将分层任务结构简化为扁平化。我们观察到,简化任务结构使表示学习对于低资源语言和领域更有效。
总之,我们通过改进低资源表示学习和增强任务知识迁移中拓扑距离较远的语言和领域的模型鲁棒性,解决了自然语言学习中的数据稀缺问题。实验表明,我们的模型能够有效地适应低资源的目标语言和领域,并显著优于之前的最先进的模型。