

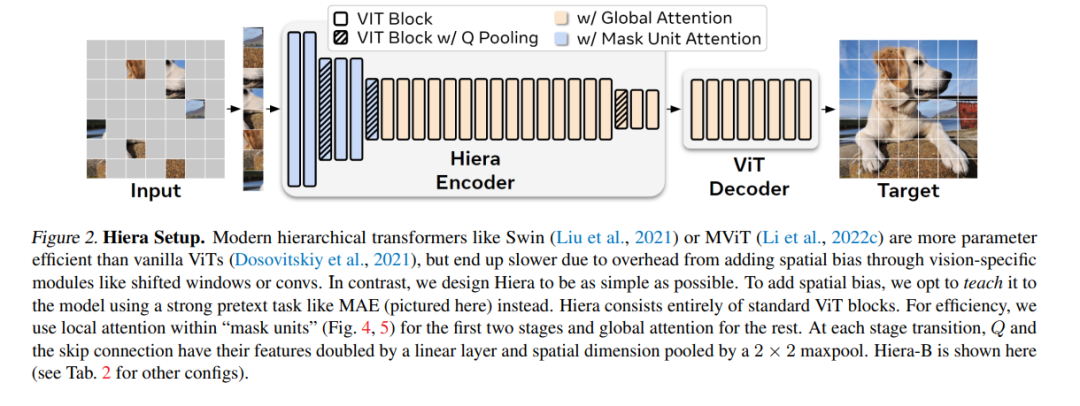
现代的分层视觉Transformer已经添加了几个专门针对视觉的组件,以追求监督分类的性能。虽然这些组件带来了有效的精确度和吸引人的FLOP计数,但增加的复杂性实际上使这些Transformer比其原生ViT(Vision Transformer)对应物更慢。在本文中,我们认为这种额外的复杂性是不必要的。通过使用强大的视觉前提任务(MAE)进行预训练,我们可以从最先进的多阶段视觉Transformer中去除所有的附加功能,而不会损失精确度。在此过程中,我们创建了Hiera,一种极其简单的分层视觉Transformer,比以前的模型更精确,同时在推断和训练过程中也更快。我们在图像和视频识别的各种任务上评估了Hiera。我们的代码和模型可以在https://github.com/facebookresearch/hiera 上找到。
成为VIP会员查看完整内容
相关内容

Arxiv
22+阅读 · 2022年9月14日
Arxiv
12+阅读 · 2021年12月30日
Arxiv
13+阅读 · 2020年12月14日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
22+阅读 · 2022年9月14日
Arxiv
12+阅读 · 2021年12月30日
Arxiv
13+阅读 · 2020年12月14日