搞懂 Vision Transformer 原理和代码系列(二十六):来自ViT的复仇策略DeiT III

极市导读
虽然视觉 Transformer 已经在多种视觉任务上取得了相当大的进步,但对其架构设计和训练过程优化的探索仍然十分有限。本文重新审视了 ViT 的有监督训练过程,为了把 ViT 的有监督训练做得更好,作者们提出了三点解决方法。 >>极市七夕粉丝福利活动:搞科研的日子是364天,但七夕只有一天!
本文目录
46 视觉 Transformer 的复仇:DeiT III
(来自 Meta AI,DeiT 一作团队)
46.1 论文解读
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
虽然视觉 Transformer 已经在多种视觉任务上取得了相当大的进步,但对其架构设计和训练过程优化的探索仍然十分有限。本文重新审视了 ViT 的有监督训练过程,为了把 ViT 的有监督训练做得更好,作者基于[1]提出了3点方法。
46 视觉 Transformer 的复仇:DeiT III

论文名称: DeiT III: Revenge of the ViT
论文地址:
https://arxiv.org/pdf/2204.07118.pdf
46.1 论文解读:
当前 ViT 的训练方法主要来自这两个工作:DeiT [2]和 How to Train Your ViT[3]。相反,许多工作着重于设计一些更加高效的 Attention,或者是在架构中加入卷积和金字塔式结构。这些新的设计,虽然对某些任务特别有效,但是却不太通用。
一个难以回答的问题是:性能的提高,究竟是由于特定的架构设计,还是仅仅因为某些特殊的架构设计更有助于优化?(就像[4]所证明的那样,早期卷积能帮助 ViT 的优化)。
因此,本文重新审视了 ViT 的有监督训练过程,为了把 ViT 的有监督训练做得更好,作者基于[1]提出了3点方法。
-
使用 Binary Cross Entropy Loss 做训练 (基于[1]提出),同时使用了 ViT 训练过程中的常用策略,比如:Stochastic Depth 和 Layer Scale。 -
一个新的简单的数据增强策略:只包含3个子策略。 -
ImageNet-21k 数据集做预训练时,Simple Random Cropping 的策略比 Random Resize Cropping 的策略更高效。 -
在训练时使用更低的分辨率:减少了训练-测试的差异,对于 224×224 的目标分辨率,以 126×126 (81个 tokens ) 的分辨率预训练的 ViT-H 在 ImageNet-1k 上比以 224×224 (256 个 tokens) 的分辨率预训练时实现了更好的性能,且对于预训练的要求也较低,因为 token 数量减少了 70%。
使用以上方法获得的实验结果有:
-
仅仅使用 ImageNet-1K 训练 ViT-H 模型,就获得了 85.2% 的 Top-1 精度,比之前在 224×224 分辨率训练出的模型精度提升了 5.1%。 -
所提出的训练策略使得可以训练数十亿参数的 ViT-H (52层) 模型,不需要任何额外的超参数调节,在 224×224 分辨率下的精度达到了 84.9%。 -
在不牺牲性能的情况下,将 ViT-H 所需的 GPU 数量和训练时间缩减一倍,使得在不减少资源量的情况下训练此类模型成为可能。这要归功于较低分辨率下的预训练,同时能够降低峰值内存。 -
改进的训练策略使得普通 ViT 缩小了与最新架构的性能差距,同时也可以提供更好的计算/性能权衡。
46.1.1 训练策略:正则化和损失函数
-
Stochastic depth:正则化策略。所有层都使用统一的 Dropout rate,并根据模型大小进行调整,如下图1所示。
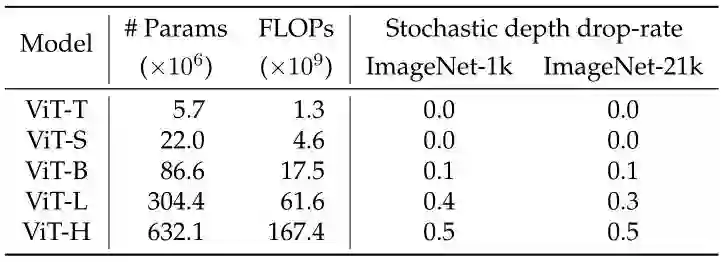
-
LayerScale:用于促进模型的收敛。作者观察到 LayerScale 允许对于最大的模型获得更高的精度,对所有模型使用相同的初始化 1e-4。
3. Binary Cross entropy:作为损失函数。对于在 ImageNet-1k 数据集上训练较大的 ViT 模型,BCE Loss 提供了显著的性能提升。但是对于在 ImageNet-1k 数据集上的实验,BCE Loss 没有取得令人信服的结果,因此在使用该数据集进行预训练以及后续微调时,作者保留了 CE Loss。
-
LAMB:作为优化器。
下图2所示为 LayerScale,BCE Loss 等等方法对于精度的影响。
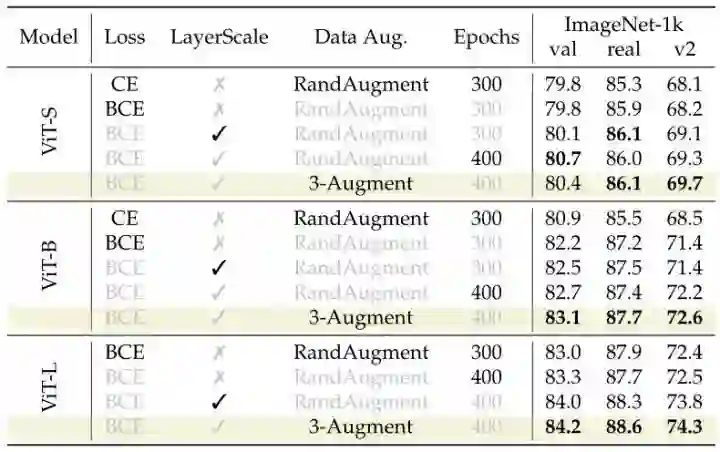
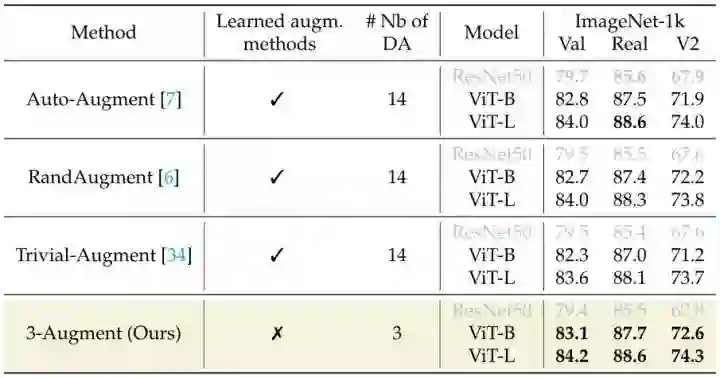
46.1.2 数据增强:只使用3种简单的数据增强策略
之前用于 ViT 的数据增强方式 (如 RandAugment) 是为卷积网络设计的,可能对于 ViT 不是最佳适配策略。作者在本文中给出了3种简单的数据增强策略,即:
-
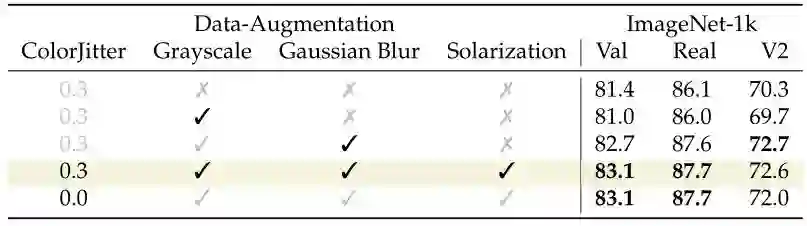
Grayscale (灰度化):有利于颜色不变性,并给予形状更多的关注。 -
Solarization (过曝):在颜色上增加了强烈的噪声,对颜色强度的变化更加鲁棒,因此更加关注形状。 -
Gaussian Blur (高斯模糊):为了稍微改变图像中的细节。
对于每幅图像,作者只均匀地随机选择以上3种中的一种数据增强策略。除了这三种选择,数据增强还包括了常见的颜色抖动 ColorJitter (亮度,对比度,饱和度和色调变换) 和水平翻转 Horizontal Flip。
下图3所示为不同数据增强方案的可视化结果,图4为不同数据增强方案的精度实验结果。

46.1.3 图像裁剪方案:使用简单的图像裁剪策略 Simple Random Crop (SRC)
Random Resized Crop (RRC) 是 GoogleNet 论文中引入的图像裁剪方法,也是防止模型过拟合的一种正则化技术。torchvision.transforms.RandomResizedCrop(size,scale=(0.08,1.0),ratio=(0.75,1.3333333333333333)) 将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为指定的大小 (先随机裁剪,然后对裁剪得到的图像缩放为固定的大小),默认有 scale=(0.08, 1.0)。各个参数含义是:
size:期望输出图像的尺寸。
scale:指定随机裁剪区域的上下界。
ratio:调整大小之前,裁剪的随机长宽比的下限和上限。
RRC 是一种比较粗糙的数据增强,作者认为这种裁剪策略在训练图像和测试图像之间引入一些差异,如纵横比和物体的外观尺寸。由于 ImageNet-21K 包含更多的图像,因此不太容易过拟合。因此作者提出了一种更简单的图像裁剪方法:Simple Random Crop (SRC):首先把输入图像的最短边 Resize 到目标大小,然后在每条边上 reflect padding 4个像素,最后,沿着图像的 X 轴要求的目标大小进行正方形的裁剪。

如上图5所示为 RRC 和 SRC 方法的采集恩结果,RRC 可以提供更多的尺寸。相比之下,SRC 覆盖了整个图像的大部分,并保持了宽高比,但提供的多样性较少。因此,在 ImageNet-1K 上训练时,使用常用的 RRC 性能会更好。
在 ImageNet-21K (比 ImageNet-1K 大10倍) 的情况下,过拟合的风险较小,RRC 提供的正则化和多样性就显得不太重要了。在这种情况下,SRC 减少了训练和测试之间尺寸的差距,同时使得裁剪后的图像与真值标签更加匹配,因为 RRC 在很多情况下得到的裁减之后的图片的 GT 对象甚至不包含在裁剪的图片中了。SRC 相对而言则更不可能发生这种情况,因为它覆盖了更大部分的图像像素。如下图6所示为 ImageNet-21K 上不同策略的消融实验,可以看到 SRC 相比 RRC 显著提升了性能。
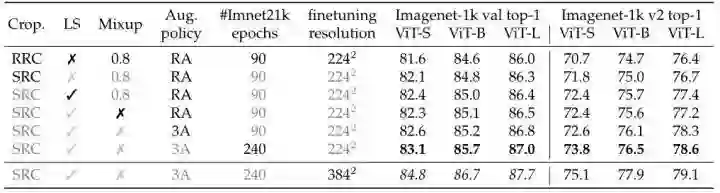
46.2 实验结果
46.2.1 基线模型和默认设置
当仅在 ImageNet-1K 上训练时,默认情况下,作者都是训练 400 Epoch,Batch size 大小为2048。除非另有说明,否则训练和测试都是以 224×224 的分辨率进行的。
当在 ImageNet-21K 上进行预训练时,默认在分辨率 224×224 上进行 90 Epoch 的预训练,然后在 ImageNet-1K 上进行 50 Epoch 的微调。在这种情况下,作者考虑两种微调分辨率:224×224 和 384×384。
46.2.2 训练 Epoch 数的影响
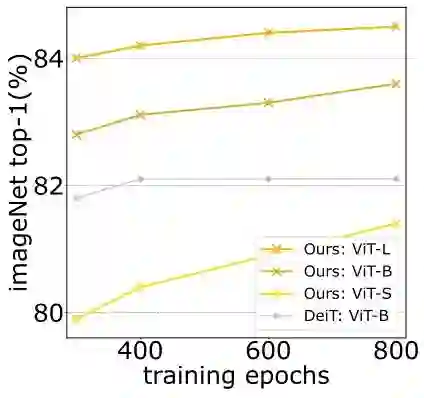
如下图7所示为训练 Epoch 数的消融实验结果。结果表明,当将训练的 Epoch 数增加到超过 400 时,ViT 模型不会像 DeiT 训练策略那样快速饱和,即训练 600 Epoch,800 Epoch 时精度会一直不断提升。
46.2.3 数据增强策略的影响
如下图8所示为数据增强策略的消融实验结果。当使用 ViT 架构进行实验时,本文所提出的 3-Augment 是最有效的,同时比其他方法更简单。因为之前的数据增强手段是为卷积模型而开发的,所以作者也提供了 ResNet-50 的结果:先前的增强策略 (RandAugment, Auto-Augment) 对于 ResNet-50 模型而言在验证集上具有相似的或更好的结果,但是对于 ViT 模型而言在验证集性能不如 3-Augment。
46.2.4 训练分辨率的影响
如下图9所示为使用不同训练分辨率的消融实验结果。FixRes 策略[5]是先在一个较小的分辨率下训练,然后在目标分辨率下进行微调。通过以192×192 (或 160×160) 的分辨率训练,然后在 224×224 大小下微调,这样的方式获得了比在 224×224 从头开始训练时更好的性能。而且可以减少显存消耗,提升训练速度。
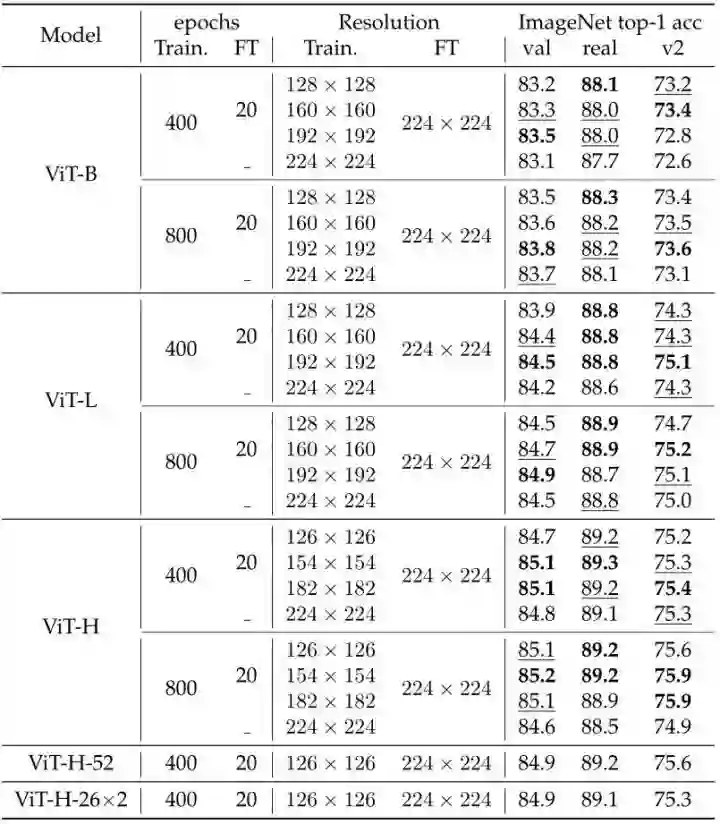
作者同时观察到小分辨率下的训练过程还具有正则化的效果,这对于较长 Epoch 的训练尤其重要,在这种情况下,没有更强的正则化模型极易出现过拟合。
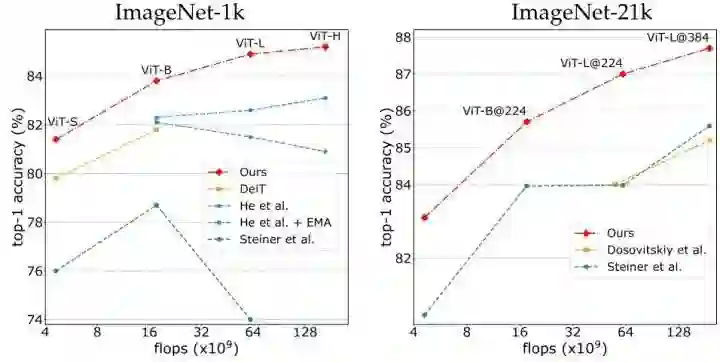
46.2.5 与 DeiT 训练策略结果的直观对比
如下图10所示为与 DeiT 训练策略结果的直观对比。使用 ImageNet-21K 预训练,本文的 ViT-L 模型获得了+3.0% 的性能提升。类似地,当在 ImageNet-1K 上从头开始训练时,与之前的最佳方法相比,本文的 ViT-H 的精确度提高了 2.1%,与不使用 EMA 的最佳方法相比,精确度提高了 4.3%。
46.2.6 ImageNet-1K 实验结果
如下图11和图12所示分别为 ImageNet-1K 上直接训练的实验结果和 ImageNet-21K 预训练,再在 ImageNet-1K 下微调的实验结果。
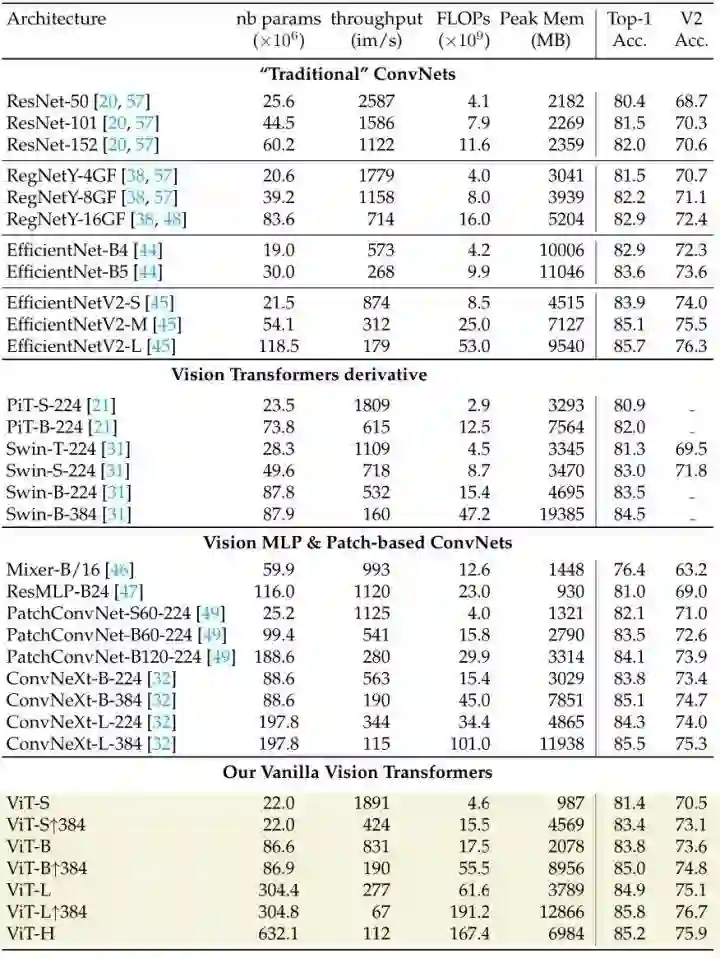
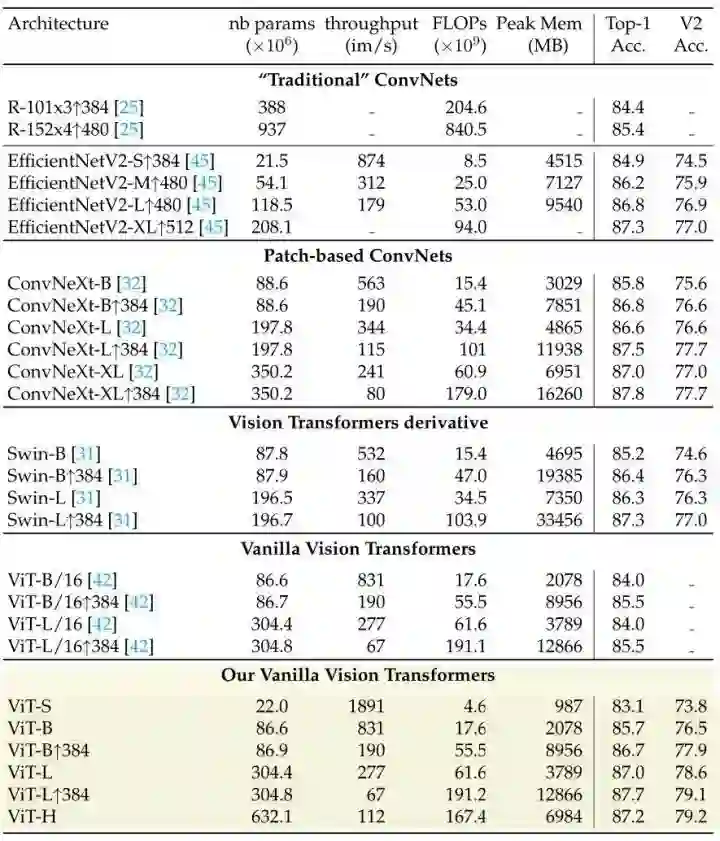
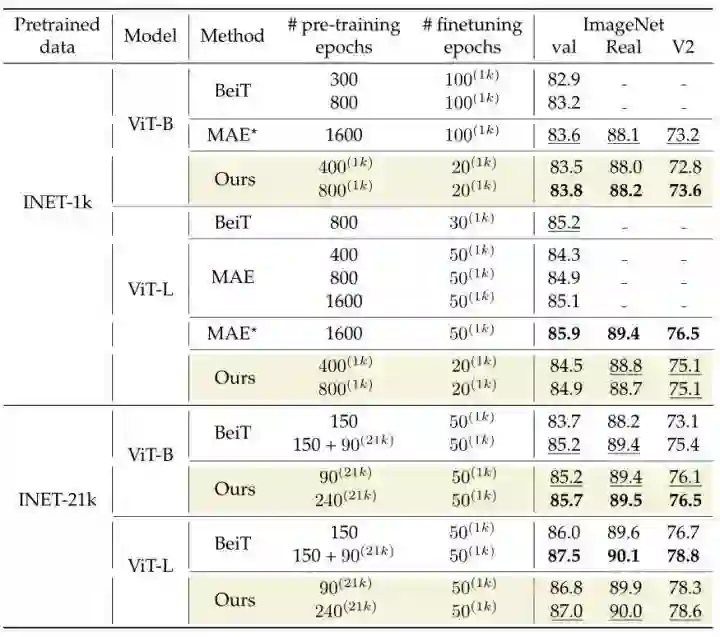
如下图13所示为用本文的训练方法训练的 ViT 模型和用不同的 BerT-like 方法训练的 ViT 的性能对比。本文的训练策略依然能够在相当的 Epoch 的情况下实现超过 BEiT,MAE 等经典方法的性能。
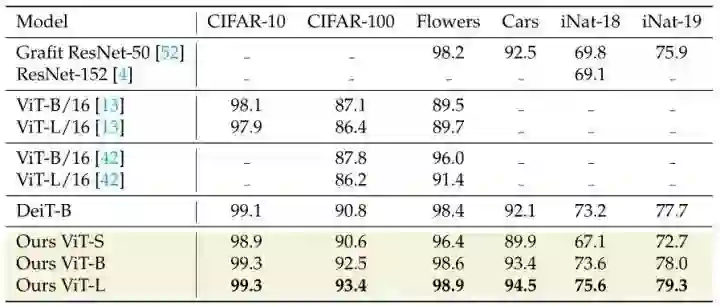
46.2.7 迁移学习实验结果
本部分实验只关注在 ImageNet-1K 上以 224×224 的分辨率进行400个 Epoch 预训练的 ViT 模型的性能,实验结果如图14所示。本文所提方法在多个模型上也有性能提升。
总结
本文重新审视了 ViT 的有监督训练过程,为了把 ViT 的有监督训练做得更好,作者提出了3点方法:使用 Binary Cross Entropy Loss 做训练,同时使用了 ViT 训练过程中的常用策略,比如:Stochastic Depth 和 Layer Scale。一个新的简单的数据增强策略:只包含3个子策略。ImageNet-21k 数据集做预训练时,Simple Random Cropping 的策略比 Random Resize Cropping 的策略更高效。在训练时使用更低的分辨率:减少了训练-测试的差异,对于 224×224 的目标分辨率,以 126×126 (81个 tokens ) 的分辨率预训练的 ViT-H 在 ImageNet-1k 上比以 224×224 (256 个 tokens) 的分辨率预训练时实现了更好的性能,且对于预训练的要求也较低,因为 token 数量减少了 70%。本文希望这一更强的基线训练策略能够帮助社区在基础视觉架构的设计方面作出更多贡献。
参考
-
^abc Resnet strikes back: An improved training procedure in timm -
^ Training data-efficient image transformers & distillation through attention -
^How to train your vit? data, augmentation, and regularization in vision transformers -
^Early convolutions help transformers see better -
^Fixing the train-test resolution discrepancy
公众号后台回复“数据集”获取100+深度学习数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选




