【导读】MIT科学家Dimitri P. Bertsekas在ASU开设了2023《强化学习》课程,讲述了强化学习一系列主题。Dimitri 的专著《强化学习与最优控制》,是一本探讨人工智能与最优控制的共同边界的著作。
**强化学习课程的教科书**
A TEXTBOOK FOR A REINFORCEMENT LEARNING COURSE

这是我在亚利桑那州立大学(ASU)课程使用的教材。它包括一整套课堂笔记,自2019-2023年间经过课堂使用而开发。可自由下载和用于教学目的。其印刷版将于2023年夏季推出。
这本教材大约有400页,包括章节末的练习题和解答。它与我在这个网站列出的动态规划(DP)和强化学习(RL)书籍和研究专著保持一致的符号和术语。它还依赖于这些书籍和专著进行理论发展和分析。
这本教材的一个重要结构特点是,它以模块化的方式组织,以实现灵活性,从而适应课程内容的变化和差异。具体来说,它分为两部分:
(1)基础平台,由第1章组成。它包含了近似DP/RL领域的选择性概述,并为课堂上更详细地发展其他RL主题提供了一个起点,这些主题的选择可以由讲师自行决定。
(2)第2章中对确定性和随机展开方法的深入介绍,以及第3章中与策略迭代/自学习和Q学习结合的离线训练神经网络和其他近似架构。
在其他课程中,可以使用相同的基础平台进行其他选择以进行深入覆盖。例如,可以基于第1章的平台构建一个最优控制/MPC/自适应控制课程。同样,可以在这个平台上构建更多或更少的数学导向课程。
目录内容:
-
Exact and Approximate Dynamic Programming . . . . .
-
Approximation in Value Space - Rollout Algorithms
-
Learning Values and Policies . . . . . . . . . . . . . .
强化学习课程,2023年春季:课堂笔记、视频讲座和幻灯片
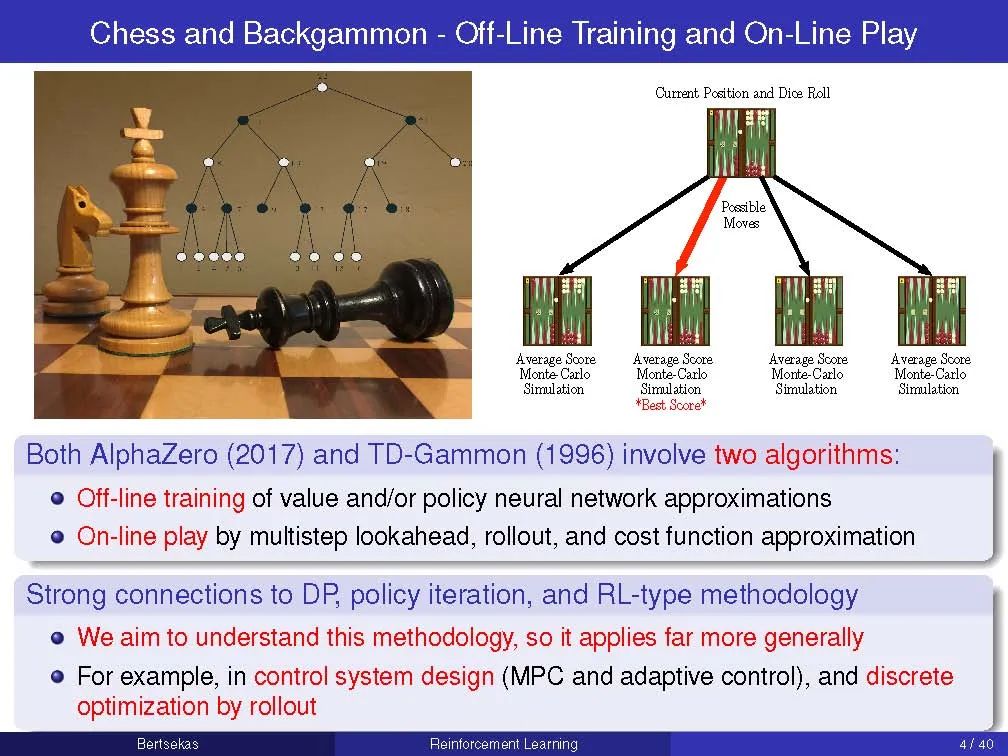
本课程将聚焦于强化学习(RL),这是人工智能目前非常活跃的一个分支领域,并将有选择性地讨论一些基于近似动态规划(DP)方法的算法主题: 逼近值和策略空间,近似策略迭代,推出(策略迭代的一种一次性形式),模型预测控制,多智能体方法,挑战组合优化问题的应用,使用模拟和神经网络架构的实现,策略梯度方法,聚合,以及工程和人工智能应用,比如AlphaZero和TD-Gammon程序的高调成功,这两个程序分别会下国际象棋和西洋双陆棋。
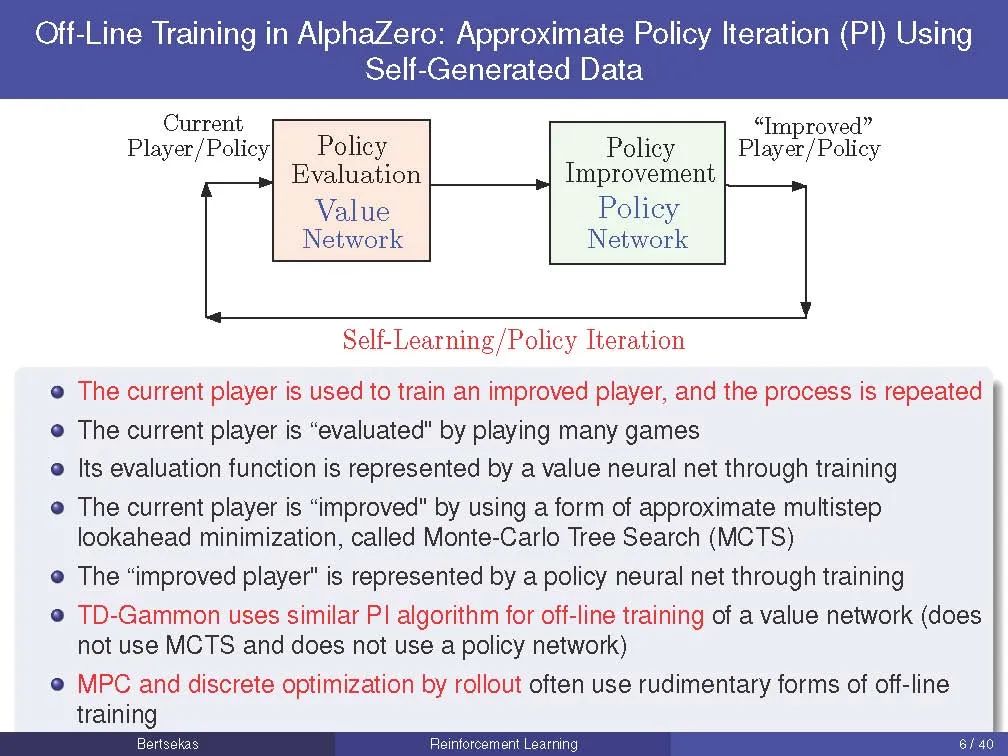
我们的主要目标之一是为RL和近似DP提出和开发一个新的概念框架。这个框架围绕着两种算法,它们在很大程度上独立设计,并通过牛顿方法的强大机制协同运行。我们称之为离线训练和在线游戏算法; 这些名字是借用了一些RL的主要成功游戏,如AlphaZero和TD-Gammon。在这些程序的背景下,离线训练算法是用来教程序如何评估位置和在任何给定的位置产生好的移动的方法,而在线比赛算法是用来实时对抗人或计算机对手的方法。我们的主要目标之一是,通过牛顿方法的算法思想和抽象DP的统一原则,表明AlphaZero和TD-Gammon方法的值空间逼近和铺展非常广泛地应用于确定性和随机最优控制问题,包括离散和连续搜索空间,以及有限和无限视界。此外,我们将展示我们的概念框架可以有效地与其他重要的方法集成,如模型预测和自适应控制、多智能体系统和分散控制、离散和贝叶斯优化,以及离散优化的启发式算法。本课程的主要重点是鼓励研究生通过定向阅读和与教师的互动来加强学习。
地址:
http://web.mit.edu/dimitrib/www/RLbook.html

作者Dimitri P. Bertsekas教授,1942年出生于希腊雅典,美国工程院院士,麻省理工大学电子工程及计算机科学教授。Bertsekas教授因其在算法优化与控制方面以及应用概率论方面编写了多达16本专著而闻名于世。他也是CiteSeer搜索引擎学术数据库中被引用率最高的100位计算机科学作者之一。Bertsekas教授还是Athena Scientific出版社的联合创始人。
讲义稿:

《强化学习与最优控制》书籍
**

本书的目的是考虑大型和具有挑战性的多阶段决策问题,这些问题可以通过动态规划和最优控制从原则上解决,但它们的精确解在计算上是难以解决的。我们讨论了依靠近似来产生性能良好的次优策略(suboptimal policies)的求解方法。这些方法统称为强化学习(reinforcement learning),也包括近似动态规划(approximate dynamic programming)和神经动态规划( neuro-dynamic programming)等替代名称。
我们的学科从最优控制和人工智能的思想相互作用中获益良多。本专著的目的之一是探索这两个领域之间的共同边界,并形成一个可以在任一领域具有背景的人员都可以访问的桥梁。
这本书的数学风格与作者的动态规划书和神经动态规划专著略有不同。我们更多地依赖于直观的解释,而不是基于证据的洞察力。在附录中,我们还对有限和无限视野动态规划理论和一些基本的近似方法作了严格的简要介绍。为此,我们需要一个适度的数学背景:微积分、初等概率和矩阵向量代数等。
实践证明这本书中的方法是有效的,最近在国际象棋和围棋中取得的惊人成就就是一个很好的证明。然而,在广泛的问题中,它们的性能可能不太可靠。这反映了该领域的技术现状:没有任何方法能够保证对所有甚至大多数问题都有效,但有足够的方法来尝试某个具有挑战性的问题,并有合理的机会使其中一个或多个问题最终获得成功。因此,我们的目标是提供一系列基于合理原则的方法,并为其属性提供直觉,即使这些属性不包括可靠的性能保证。希望通过对这些方法及其变体的充分探索,读者将能够充分解决他/她自己的问题。

课程讲义课件