
© 作者|都一凡 机构|中国人民大学研究方向|多模态大模型 视频多模态大语言模型(MLLMs)在各种下游任务中展现了卓越的视频语义理解能力。尽管取得了很大进展,但视觉上下文表示对模型效果的影响仍然缺乏系统性的研究。不同于图像模型,视频中所有的帧以及每一帧的视觉token共同构成了视觉上下文窗口,本文探索了视觉上下文表示的设计空间,发现了视觉窗口长度的scaling law,并利用它找到更有效的视频表示策略来提升视频大模型的性能。
文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

论文题目:Exploring the Design Space of Visual Context Representation in Video MLLMs 论文链接: https://arxiv.org/pdf/2410.13694
1 引言
视频多模态大语言模型(MLLMs)在各种下游任务中展现了卓越的视频语义理解能力。尽管取得了很大进展,但在视觉上下文表示方面仍缺乏系统性的研究。这里的视觉上下文表示,指的是视频中的帧和每一帧的视觉向量(视觉token)共同构成了视频大模型的视觉窗口,即窗口长度大于等于帧数与视觉 token 数的乘积。在这篇论文中,我们探索了视觉上下文表示的设计空间,旨在通过找到更有效的表示方案来提升视频 MLLMs 的性能。 首先,我们将视觉上下文表示任务形式化为一个约束优化问题,在给定最大视觉上下文窗口大小的前提下,把语言模型的损失建模为帧数和每帧的token数的函数。接着,我们分别研究了帧数和视觉token数的scaling law,并通过大量的实验拟合出相应的函数曲线。 此外,我们还研究了帧数和token数二者的联合效应,并推导出二者的最优解。实验结果表明理论的最优解为模型训练提供了一个较好的初始点。
2 视觉窗口的scaling law
目前的视频MLLM通常采用与图像MLLM同样的架构,即把视频转化成多个帧,每一帧独立的用图像编码器编码成若干个视觉向量。把所有帧的视觉向量拼接起来,就构成了本文所说的视觉上下文。为了研究视觉上下文对模型的影响,在固定架构的前提下,首先需要研究两个子问题: * Q1. 改变帧数对模型效果有什么影响? * Q2. 改变视觉token的数量对模型效果有什么影响?
2.1 视觉token的scaling law
我们固定帧数,变动每帧的视觉token数,从而研究视觉token的scaling law。具体而言,我们使用两种方法改变单帧的token数:基于采样的方法和基于压缩的方法,如下图所示。
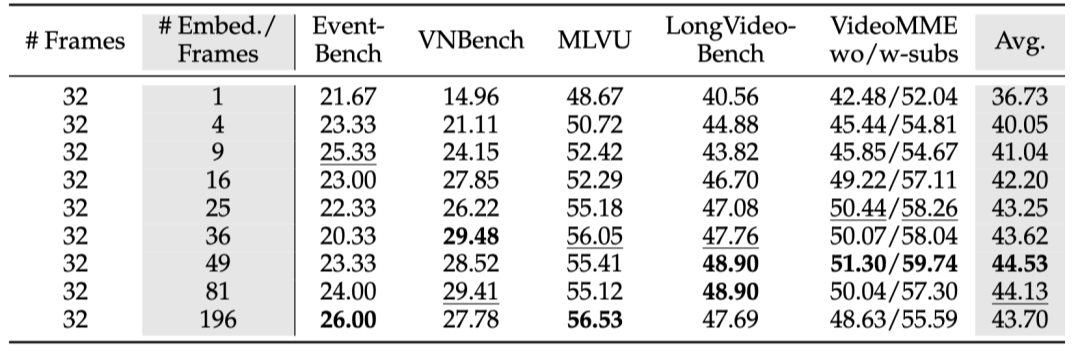
在这一部分中,我们首先通过图像编码器将每张图片转换为大小为 27×27 的向量矩阵,然后通过采样或者压缩的方式从中得到以下几种数量的向量矩阵:1²、2²、3²、4²、5²、6²、7²、9² 和 14²。同时,我们将帧数 T=32 固定不变,从每个视频中均匀采样帧,每种方法共训练了 9 个视频 MLLMs。 我们提出了以下函数来拟合视觉token的scaling law: 得到的结果如下图所示:
**2.1.1 基于采样的方法
拟合的参数为:,表明拟合结果较好:当视觉token数量增加时,损失值 呈现出类似幂律的下降趋势。 下表展示了在长视频理解的benchmark上改变视觉token数量的对模型效果的影响。总体来看,随着视觉token数量的增加,模型性能有所提升,特别是在token数量从 1 增加到 4 时提升最为明显。然而,有趣的是,当token数量超过某个阈值后,性能反而开始下降。例如,使用 196 个token的效果比使用 49 个token还要差,尽管使用 196 个token时的语言模型损失明显小于使用 49 个token时的损失,这表明模型loss并不总是能直接反映其在下游任务中的真实表现。 表1. 采样视觉token对模型效果的影响
**2.1.2 基于压缩的方法
我们采用了 MeanPooling 策略来压缩视觉token,这种方法被目前的许多MLLM广泛采用,其优点是不引入额外的参数,避免了其他因素对实验结果的影响。我们在编码后的视觉token上使用不同的kernel size进行 MeanPooling,从而得到图像的压缩表示。具体来说,每张图像会被编码为 27×27 的视觉token矩阵,然后我们对其应用 的 MeanPooling,步长也为 ,其中 。这会将每张图像压缩成 1²、2²、3²、4²、5²、6²、7²、9² 和 14² 个token表示。为了保证能和基于采样的方法进行公平比较,其他实验条件保持不变。 拟合得到的参数为:, 表明拟合结果较好。相比于上面提到的基于采样方法的参数,压缩方法的 明显更大。这意味着使用压缩方法增加token数量时,损失会下降得更快,在上面的曲线图中也能明显的看出。此外,压缩方法在相同的视觉token数量下,总是比采样方法得到的loss更低。这是因为压缩方法聚合了所有token中的信息,但是采样的方法直接丢弃部分视觉token,前者更有利于模型学习视觉特征,加速收敛速度。 下表展示了长视频理解的benchmark上的测试结果,可以发现,随着视觉token数量的增加,模型能力持续提升。这与基于采样的方法明显不同,进一步突出了压缩方法的优势。Benchmark上的结果和根据loss得到的结论一致,表明压缩方法在性能上具有更明显的优势。 表2. 压缩视觉token对模型效果的影响

💡Take-away Findings``` - 增加视觉token的数量可以显著提升性能。基于采样的方法在 49 个token时达到峰值,而基于压缩的方法即使使用 196 个token也没有出现性能饱和。
- 当视觉上下文窗口大小受限时,基于压缩方法能够用更少的token有效保留更多的视觉信息,得到更好的表现。
### 2.2 帧数的scaling law
接下来,我们固定每帧的token数量,改变来探索帧数的scaling law。仍然是考虑基于采样和基于压缩的方法,如下图所示:
由于内存限制下的最大上下文长度为 8K,即 128 帧,每帧 49 个视觉 token。因此,我们先使用压缩的方法(MeanPooling)将每一帧的token数量降低到49并固定不变,然后通过调整帧数进行实验。类似地,我们使用以下函数来拟合基于采样的方法下,帧数和loss之间的关系:
我们使用以下线性函数来拟合基于压缩的方法下,帧数和loss之间的关系:
得到的结果如下图所示:
#### **2.2.1 基于采样的方法
在现有研究中,为了适应大型语言模型(LLM)的上下文长度,从原始视频中均匀采样帧已成为常见做法。在此基础上,我们通过采样不同数量的帧,将 设置为 {1, 8, 16, 32, 48, 64, 96, 128},来探索scaling效果。
我们将损失与帧数 进行拟合,得到以下参数:, 表明拟合效果较好。如上图所示,拟合曲线显示随着帧数的增加而减少,并呈现出幂律趋势。
下表展示了在长视频理解benchmark上的结果,可以看到,随着帧数增加,模型在所有基准测试中的表现都不断提升,即使在 128 帧时也没有出现明显的性能饱和,而这已超过大多数视频 MLLM 的最大帧数。
表3. 采样帧对模型效果的影响
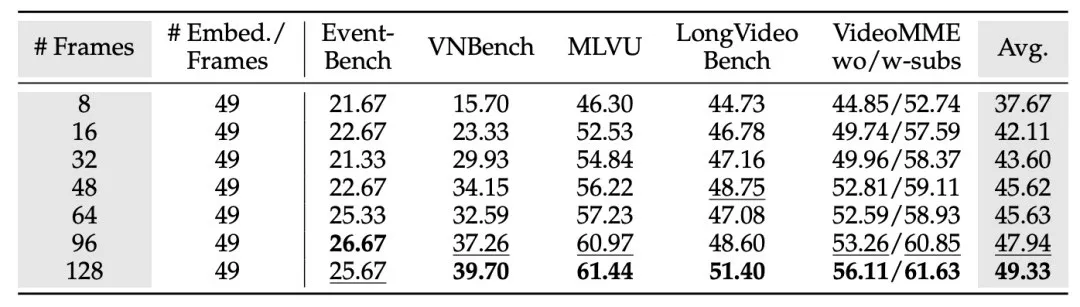
在所有的benchmark中,VNBench的提升最为显著(从 15.70 提升到 39.70),表明“大海捞针”(NIAH)任务最受益于更长的视觉上下文。然而,Event-Bench在超过 64 帧后并没有明显的提升。深入分析发现,Event-Bench 的所有问题都集中于**情节推理**,而这类任务无法仅通过增加帧数有效解决。总体来看,与增加每帧的视觉token数相比,**增加帧数**对模型性能的提升更加显著。
另一个有趣的发现是,增加帧数可以弥补压缩视觉token所导致的性能下降。具体而言,表2显示,将每帧的视觉token从 196 减少到 49 会导致所有基准测试的性能下降。然而,如果同时将帧数增加到 128,模型的准确率不仅恢复,还超越了使用 196 个token的模型(对比表2和表3的最后一行:这两种设置的视觉窗口长度都是6272,但一个是32帧,每帧196个token;另一个是128帧,每帧49个token)。
这些结果表明,当视觉上下文长度受到限制时,可以通过**增加帧数、减少每帧的token数量**来获得更好的性能。这个权衡将在下面得到进一步的验证。
#### **2.2.2 基于压缩的方法
在视频表示学习领域中,沿时间维度压缩帧数已被广泛讨论,但在视频多模态大模型(MLLMs)中仍未得到充分探索。与2.1.2节中的压缩策略类似,我们在这里使用均值池化(MeanPooling来减少输入到大语言模型(LLM)的帧数。具体来说,我们首先从视频中均匀采样出 帧,编码之后沿时间维度进行均值池化,将视频压缩为 帧。时间池化的核大小 取决于 和 的比例:。
由于计算内存的限制,我们将 设为 128,并选择 来探索帧数的扩展规律。为了与基于采样的方法进行公平比较,我们也将每帧的视觉token数量减少到 49。在实际操作中,我们使用**三维均值池化**,而不是先进行空间均值池化后再进行时间池化,以避免feature map的过度平滑。
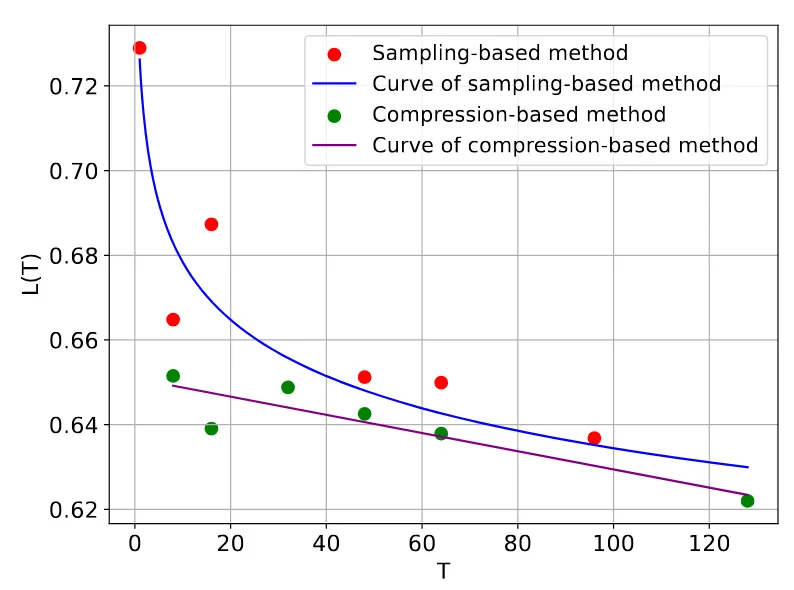
与之前的实验不同,这部分数据无法用幂律函数很好地拟合,我们发现**线性函数**可以更好地描述其关系。我们根据帧数 拟合模型损失,得到 ,表明拟合较好。同时,对比**基于采样**与**基于压缩**的方法曲线,压缩方法始终表现出更低的损失。这一现象揭示了视频数据中的**时间冗余**,即便将时间信息压缩到更少的帧中,仍能有效保留其关键内容。
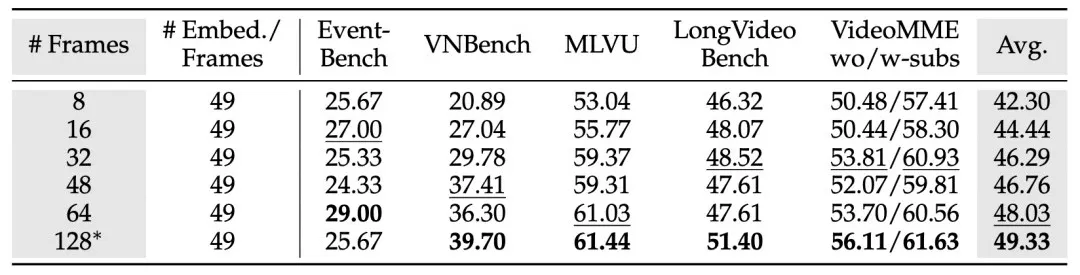
下表展示了基准测试的评估结果。总体来看,增加帧数总是能提升模型性能。相比于采样方法,压缩方法在相同帧数下表现出更高的准确率,这与其训练损失更低的现象一致。
表4. 压缩帧对模型效果的影响
💡Take-away Findings```
- 增加帧数能持续提升模型性能,甚至能弥补每帧视觉token压缩导致的性能下降。
- 在有限的视觉上下文窗口中,基于压缩的方法比基于采样的方法在更少帧数的情况下保留更多时间信息。
3 帧数和token数的权衡
前面章节分别讨论了视觉token和帧数对模型性能的影响。在这一部分,我们进一步研究两者的联合效果,由于模型的上下文长度有限,所以,在帧数和每帧token数量之间需要进行权衡——选的帧越多,每帧可选的视觉token数量就越少;反之亦然。 为了研究二者对模型效果的影响,我们将语言模型的损失 建模为帧数 和每帧token数量 的函数。在给定最大视觉上下文窗口大小 的情况下, 和 必须满足以下约束条件:。由于我们希望在LLM的最大输入长度或部署资源受限的情况下,同时确定视觉token数量和帧数的最佳组合,这等价于找到损失 的极小值点: 其中, 和 分别表示在输入限制 下,帧数和token数量的最优分配策略。 基于理论与实验分析,我们提出了一个名为 Opt-Visor 的模型,即“Optimal Visual Context representation”,它能处理最多162帧的视频。
3.1 两个因素的拟合函数
参考Chinchilla scaling law,我们使用以下函数拟合视觉token(M)和帧数(T)对损失的影响: 我们设置视觉token数量为25和81,帧数为48、64、80和96,总共训练了8个模型。结合之前的实验数据,共获得25个模型。最终拟合得到的参数为:,,,,,且表明拟合结果较好。如下图所示:
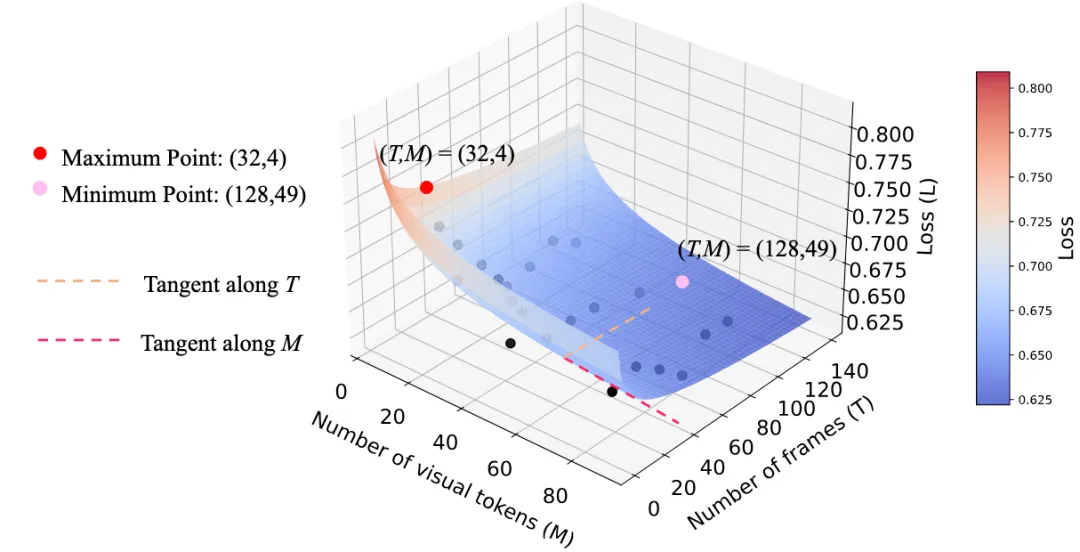
实验表明,随着视觉token和帧数的增加,损失逐渐减少,并在时达到最低。相反,在时损失最高。
3.2 寻找最优配置
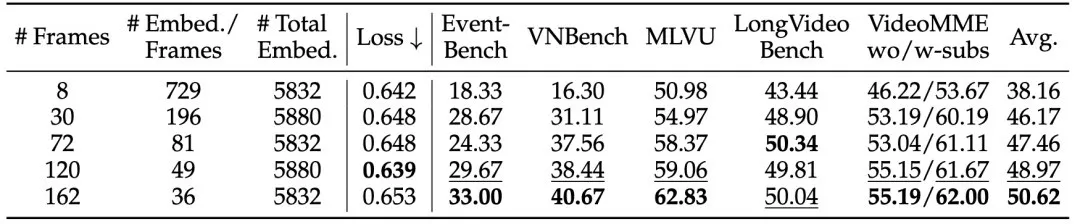
实际应用中,我们希望回答如下问题:“在给定的视觉上下文窗口下,如何选择M和T才能获得最低损失?”为此,我们使用拉格朗日乘子法求解在约束下,的极小值点: 在实验中,我们将设置为6000,计算得出和。我们在固定的上下文长度下进行了实验,使用了以下五种组合:。如下表所示,结果表明,时损失最低,与理论计算结果非常接近。从benchmark上的结果来看,即使在162帧和每帧36个token的情况下,模型性能仍然持续提升,没有出现饱和。这是因为预测下一个词的损失与下游任务的最终性能之间仍有一定差距,但理论最小点为模型的训练提供了一个较好的初始超参设置。 表5. 在固定窗口下同时改变帧数和token数对模型效果的影响
3.3 与现有MLLMs的比较
我们将Opt-Visor与一系列主流MLLM进行了对比,包括以下闭源模型:GPT-4o、Gemini-1.5-Pro、GPT-4V、Qwen-VL-Max,以及以下开源模型:Video-CCAM、Video-LLaVA、LLaMA-VID-long、MovieChat、VideoChat2、ST-LLM、VideoLLaMA2、LongVA和LongViLA。 为了提升模型性能,我们在训练过程中采用了以下技术:
- 使用AnyRes编码方案,将每张图像划分为多个小块,模拟短视频。
- 在每一帧前添加时间提示,使视频表示为类似“1 <frame 1> 2 <frame 2> ... n ”的格式。
- 增大batch size,从64增加到128,并训练2个epoch。
在这些设置下,我们重新训练了的模型,并将其命名为Opt-Visor。在benchmark上的评测结果如下表所示: 表6.与现有MLLM的比较
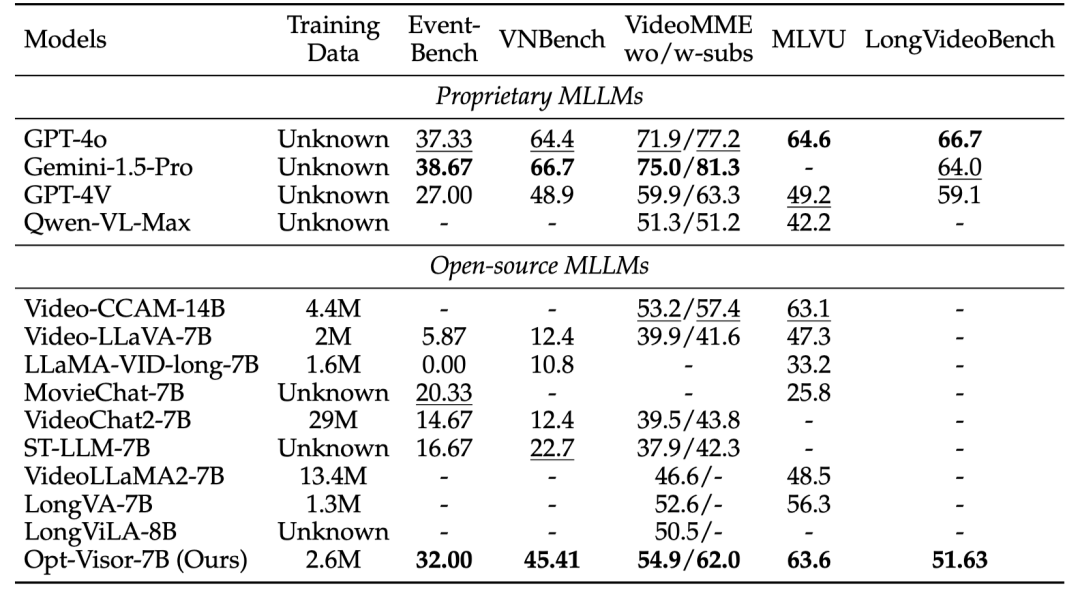
在长视频理解的评测中,Opt-Visor在所有开源模型中表现最佳,尽管仅使用了2.6M条训练样本。值得注意的是,Opt-Visor在某些基准测试(如Event-Bench和MLVU)上甚至超过了GPT-4V,证明了我们提出的最佳视觉上下文表示方案的有效性。



