
© 作者|董梓灿 机构|中国人民大学研究方向|大语言模型、长文本处理
基于Transformer的大语言模型天然具有固定的上下文窗口。虽然已有一些方法用于拓展上下文窗口,但对于其背后的原理仍缺乏深入解释。本文通过从模型隐状态中解耦出位置向量,对位置信息的形成和作用进行了系统分析,并进一步从位置向量的角度统一了长度外推和上下文窗口扩展的研究。最终,我们提出了两种全新的上下文窗口扩展方法。该论文已被NeurIPS 2024接收为Spotlight。

论文题目:Exploring Context Window of Large Language Models via Decomposed Positional Vectors 论文链接: https://arxiv.org/abs/2405.18009
1 引言
尽管基于 Transformer 的大模型通过位置编码捕捉了序列中的位置信息,但通常受限于最大输入长度(即上下文窗口)。当输入超过上下文窗口时,模型的位置编码往往会出现分布外的位置序号,导致模型性能下降。虽然已有不少工作致力于扩展上下文窗口,但这些研究大多过于关注位置编码和注意力机制的调整,忽略了模型的隐状态如何变化以适应更长的上下文。 在本工作中,我们通过分析模型隐状态中的隐式位置信息,揭示了大模型在上下文窗口内外的工作机制。我们使用基于均值的分解方法,从模型的隐状态中提取表示位置信息的位置向量,并对其形成过程及影响进行深入分析。同时,我们统一了超过上下文窗口后长度外推和上下文窗口扩展的机制。我们的发现如下:
-
通过第一层的注意力,最前面的位置上形成了独特的位置信息,并作为锚点随着层的加深塑造了后续的位置信息。
-
位置向量起到了注意力机制中注意力汇和长期衰减的重要作用。
-
在超过上下文窗口之后,位置向量的稳定性是模型长度外推的关键因素。而分布外的位置向量则是导致模型性能下降的主因之一。
-
上下文窗口拓展方法本质上实现了位置向量的内插。
基于这些发现,我们提出了两种无需训练的上下文窗口扩展方法,即位置向量替换和注意力窗口扩展。
2 位置向量
先前的研究指出,Transformer 的隐藏状态中蕴含着位置信息。对于任意给定的隐藏状态 (可以是层的输出、查询、键或值等),我们可以将其分解为与上下文语义相关的语义向量 和与位置信息相关的位置向量 。其中,位置向量进一步分解为均值向量 和位置偏置 ,表达式如下: 在此,我们采用了一种基于均值的分解方法,利用从语料库中抽取的大量样本按位置进行平均,来获得对应的位置向量。通过该方法提取出的位置向量,可以进一步分析模型中的位置信息,并借助相似度分析和主成分分析(PCA)等工具,比较不同位置之间的差异。
3 分析
3.1 位置向量的形成和作用
在Transformer解码器模型中,无论是否存在位置信息,模型都会隐式的捕捉到位置信息。在这里,我们探讨了完整注意力和窗口注意力中位置信息的形成和作用。
**3.1.1 完整注意力的位置向量形成
对于使用完整注意力机制的模型,我们首先从各层的隐状态中提取位置向量,并通过PCA进行可视化。下图展示了基于RoPE和NoPE模型的第一层和第七层的PCA结果。可以看出,在经过第一层后,初始词元的位置信息已经开始展现出独特的特征,而后续词元的位置区分并不明显。然而,经过多层处理后,不同位置的词元逐渐呈现出各自独特的位置信息。
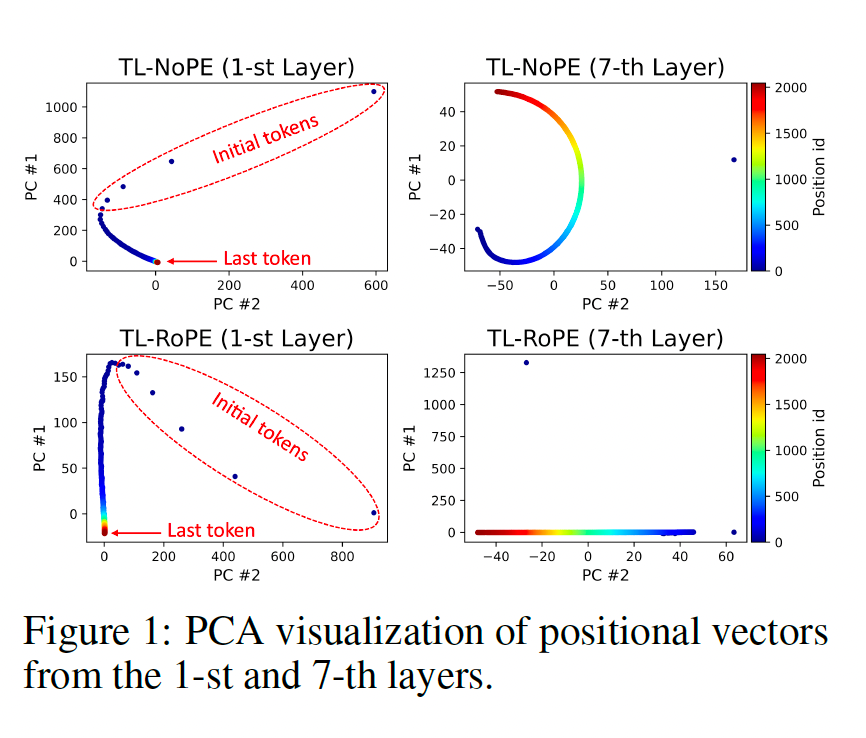
进一步,我们探讨了多层网络中后续位置上位置信息形成的来源。我们首先选取了前序(0-4)和中间(4-256)词元,分别对第一层之后所有注意力模块中这些词元的不同成分进行了删除操作(包括整个值、位置向量、位置偏置和语义向量)。通过这种方式,我们阻断了信息流动,从而观察不同成分对位置信息向量以及模型整体性能的影响。实验结果如下表所示:
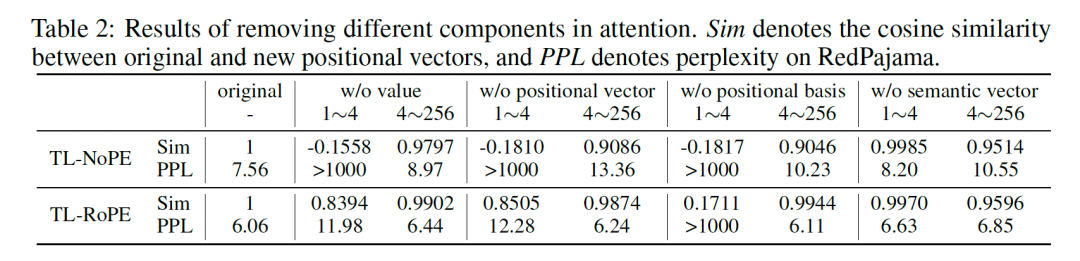
可以发现,当删除中间词元的语义向量时,模型的位置信息向量和困惑度几乎没有变化。然而,当删除最初几个词元的位置信息向量和位置偏置时,模型性能显著下降。这表明最初词元的位置信息向量作为锚点,其信息流动促进了后续词元位置信息的形成。
**3.1.2 窗口注意力的位置向量形成
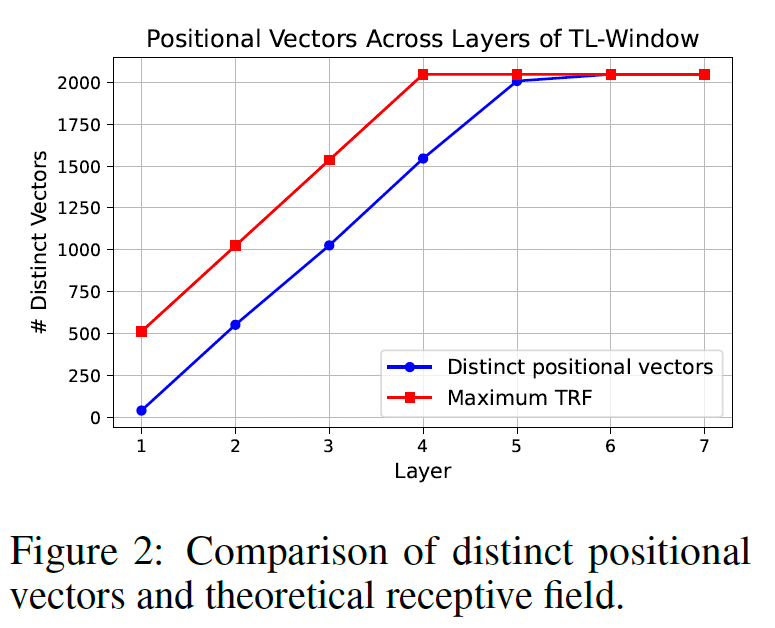
对于基于窗口注意力的模型,具有相同最大感受野(窗口大小层数)的位置共享相同的位置向量。因此,我们提出了“独特位置向量”的概念,讨论上下文窗口内究竟有多少个独特的位置向量。在此,我们选择 0.99 作为阈值,将所有与后续位置的位置向量的余弦相似度大于该阈值的设定为独特位置向量。如下图所示,我们统计了不同层中独特位置向量的数量。与完整注意力机制类似,第一层仅有前几个词元拥有独特的位置向量。然而,随着层数的增加,越来越多的位置从前到后表现出独特的位置信息,且增加速度大致与窗口大小一致。这表明类似的位置信息流动在窗口注意力机制中同样发生,且随着层数和窗口的传递表现得愈加明显。
**3.1.3 位置向量对注意力机制的影响
在讨论完位置向量的形成之后,我们接下来讨论位置向量在注意力模块中的作用。我们首先提取出不同头的查询和键,并在下述四种情况下计算注意力值: * original:直接计算 * w/o semantic vector:删除查询和键中的语义向量 * w/o positional vector:删除查询和键中的位置向量 * w/o positional basis:删除查询和键中的位置偏置
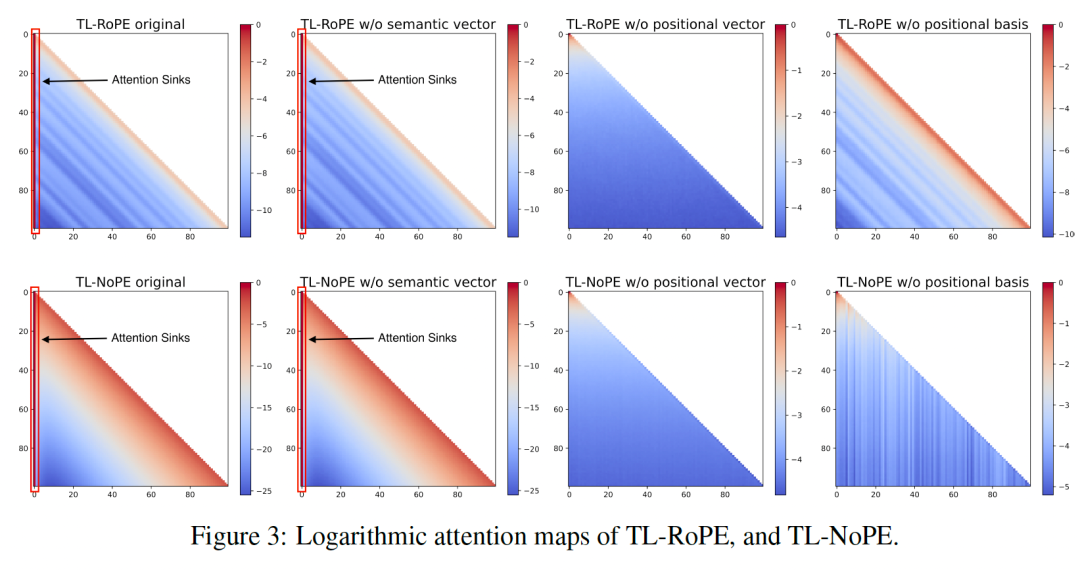
我们对选定注意力头的前100个位置进行了多次采样,并对其注意力值取平均,生成的注意力热力图如上所示。可以看到,删除位置信息后,主要出现了以下变化: * 模型失去了注意力汇(attention sinks)的特点,即前几个词元不再占据大部分注意力。 * 注意力的长期衰减特性消失了,即随相对距离增加,注意力值逐渐减小的趋势不再存在。
3.2 超过上下文窗口的位置向量
当超过模型的上下文窗口之后,我们测试了直接外推和上下文窗口拓展两个场景下位置向量的变化和影响。
**3.2.1 直接外推
我们首先测试了不同模型在直接外推情况下的表现,重点分析了长度外推(即困惑度保持稳定)与位置向量的关系。我们测量了模型在更长文本下的困惑度变化,并比较了窗口内外位置向量的相似度。结果表明,无论采用何种位置编码或注意力机制,只要保持位置向量的稳定性,就可以实现长度外推。
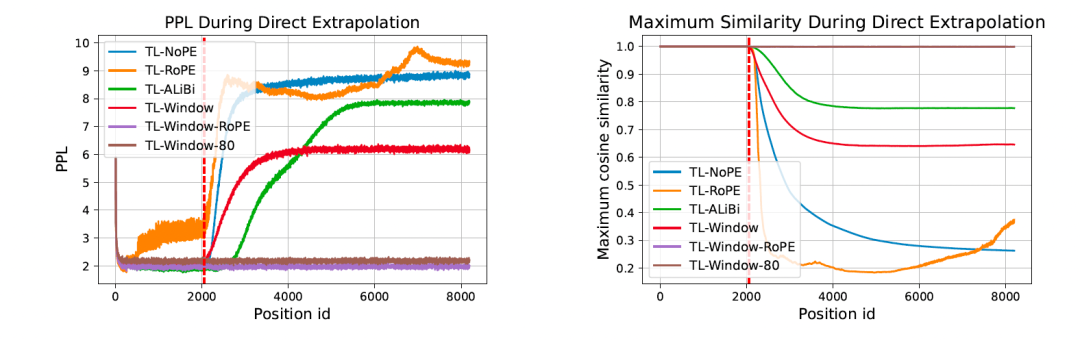
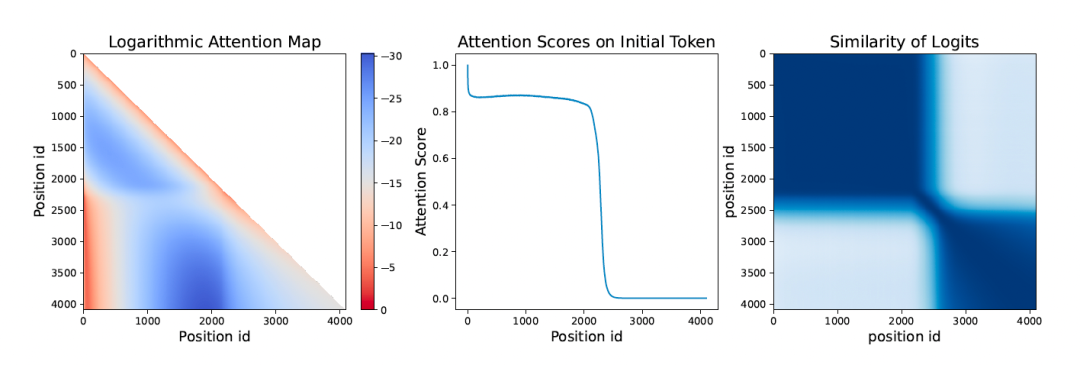
进一步,我们针对无法实现长度外推的模型,考察了分布外位置信息向量的影响。我们测试了模型的注意力值和最后一层输出的 Logits 所对应的位置信息向量。结果表明:(1)当文本长度超过上下文窗口后,位置信息的长期衰减特性和注意力集中的特性难以维持;(2)最后一层输出的 Logits 的位置信息向量与窗口内的位置信息存在较大差异,直接影响了模型的输出结果。
**3.2.2 上下文窗口拓展
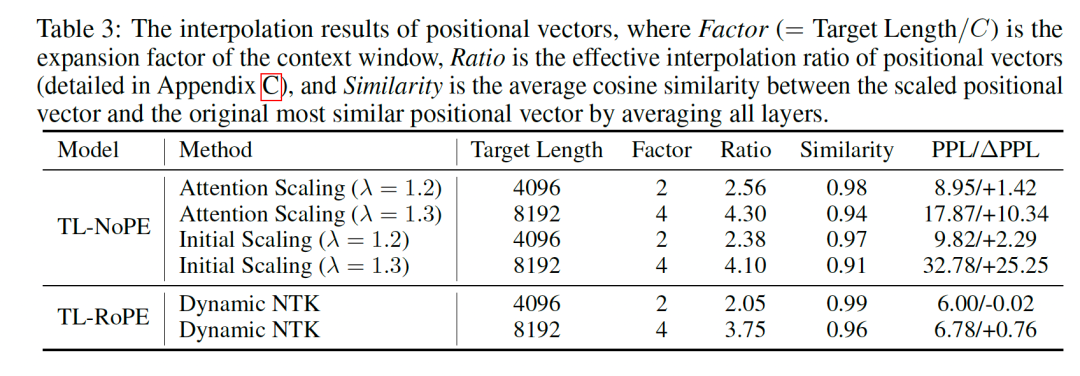
为探究上下文窗口拓展为何能够免训练地避免性能下降,我们深入分析了位置向量的变化情况,对比了拓展前后计算出的位置信息。正如下表所示,上下文窗口拓展后,位置向量出现了显著的内插现象,且内插比例与模型的上下文窗口扩展比例基本一致。 进一步研究发现,基于初始位置的信息流动促进位置信息形成的原理,以及注意力放缩方法,我们仅对首词元的注意力值进行了控制(Initial scaling)。结果表明,仅对首位置进行放缩就能实现与全词元放缩相近的效果。这表明位置向量的放缩主要通过调整首词元的信息流动来实现。
4 方法
4.1.1 位置向量替换
对于未使用位置编码(NoPE)的模型,模型通过对位置向量进行插值来实现上下文窗口的扩展。因此,我们提出了一种位置向量替换的方法,针对特定层的位置向量,使用插值后的新位置向量(插值比例为 )进行替换。同时,通过对位置向量进行缩放(),可以进一步提升模型的性能。修改后的位置向量如下所示:
4.1.2 注意力窗口拓展
基于窗口注意力的模型中,最前面词元的位置信息会随着层和窗口的推进而逐渐影响后续词元位置信息的形成。为此,我们提出了窗口注意力扩展方法,通过将注意力窗口的大小按比例 进行扩展,以控制位置信息的传递。同时,借鉴注意力缩放的方法,我们同样引入温度系数 以避免处理到OOD(超出训练分布)的位置信息向量。经过调整后的注意力值 如下所示:
5 实验
为了验证我们方法的有效性,我们利用训练好的模型在 PG-19 数据集上测试了语言建模任务的表现。具体而言,我们采用了滑动窗口的测试方式,并使用困惑度(PPL)作为评价指标。结果如下表所示:
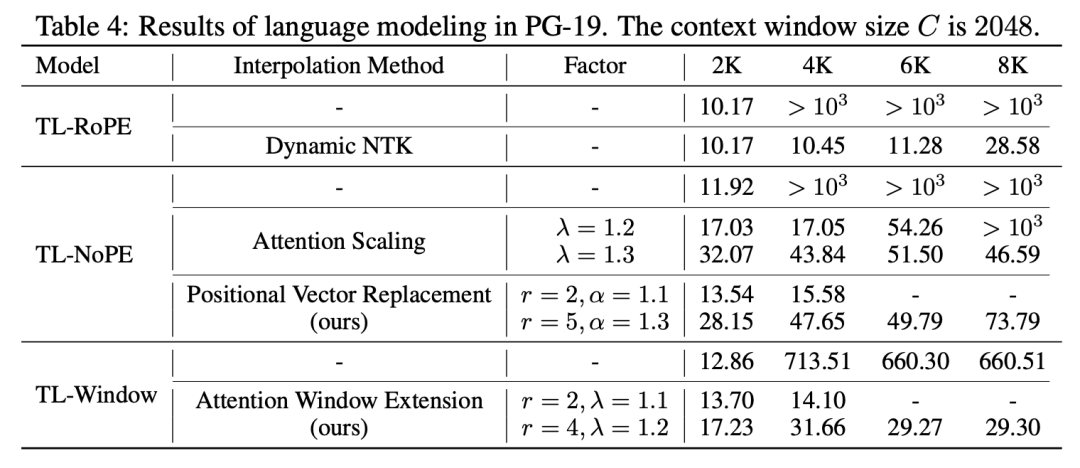
从结果中可以看出,无论是针对 NoPE 模型的位置信息向量替换,还是针对使用窗口注意力的注意力窗口扩展方法,都能有效扩展模型的上下文窗口,避免了直接外推导致的严重性能损失。同时,我们的方法在效果上与之前的一些方法相媲美。
6 结论
在这项工作中,我们通过对位置向量的分解,探讨了大语言模型在上下文窗口内外的内部工作机制。研究发现,初始的词元展示了不同的位置信息,并作为后续词元位置向量的锚点。此外,当文本超出上下文窗口时,长度外推方法能够保持位置向量的稳定性,而上下文窗口扩展方法则实现了位置向量的插值。基于这些观察,我们提出了两种方法:位置向量替换和注意力窗口扩展,这两种方法能够在特定大语言模型中实现免训练的上下文窗口扩展。我们认为,位置向量将成为分析大语言模型上下文窗口的重要工具,并将推动更优秀算法的设计,以进一步扩展大语言模型的上下文窗口。
