

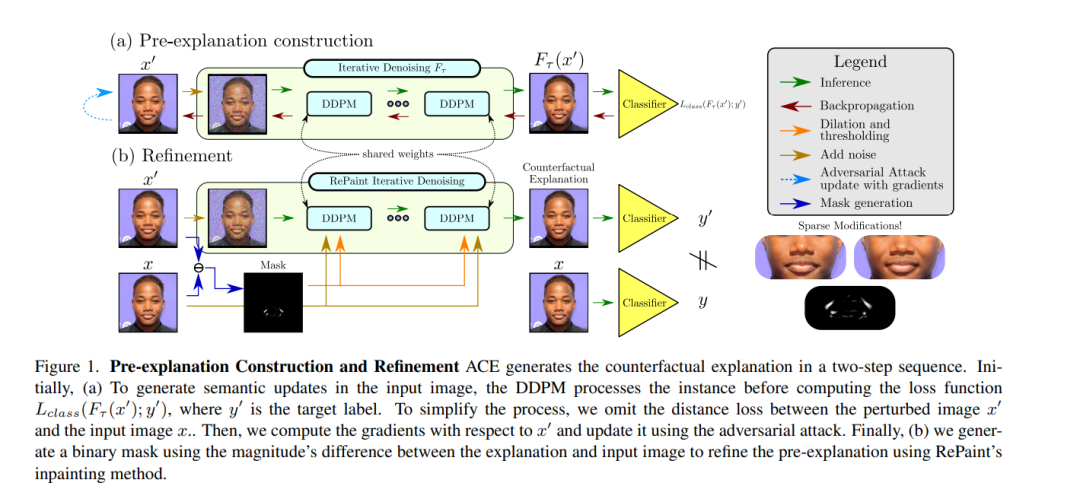
反事实解释和对抗性攻击有一个相关的目标:不管输出标签的特征如何,用最小的扰动翻转输出标签。然而,对抗性攻击不能直接用于反事实解释的角度,因为这种扰动被视为噪声,而不是可操作和可理解的图像修改。**在鲁棒学习文献的基础上,提出了一种优雅的方法,将对抗性攻击转化为有语义意义的扰动,而不需要修改分类器来解释。**所提出的方法假设,去噪扩散概率模型是优秀的正则化方法,可以在生成对抗攻击时避免高频和分布外的扰动。这篇论文的核心思想是通过扩散模型来构建攻击来完善它们。这允许研究目标模型,而不管其鲁棒性水平。广泛的实验表明,所提出的反事实解释方法在多个测试平台上比当前最先进的方法具有优势。
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
27+阅读 · 2021年1月21日
相关VIP内容
相关资讯
相关论文
Arxiv
27+阅读 · 2021年1月21日