e-CARE: 可解释的因果推理评测
0. 摘要
传统因果推理数据集往往只提供标记候选原因与结果之间是否存在因果关系的0-1标签。但是,在这种因果标签之外,对于因果关系为什么能够成立的解释可能对更深入理解因果关系具有重要意义。因此,我们发表在ACL2022上的文章《e-CARE: a New Dataset for Exploring Explainable Causal Reasoning》提供了一个人工标注的可解释因果推理数据集(explainable CAusal REasoning dataset, e-CARE),eCARE数据集包含超过2万条因果推理问题,并且对于每个因果推理问题,提供了一个自然语言描述的,有关于因果关系为何能够成立的解释。为了推动可解释因果推理方向的发展,我们在e-CARE数据集的基础上进一步搭建了可解释因果推理评测平台,平台地址:https://scir-sp.github.io/,原始文章可以在以下地址下载:https://arxiv.org/abs/2205.05849。欢迎大家踊跃参与评测,共同推动可解释因果推理领域的发展!
1. 简介
因果推理是人类的一项核心认知能力。借助因果推理能力,人类得以理解已观测到的各种现象,并预测将来可能发生的事件。然而,尽管当下的各类因果推理模型已经在现有的因果推理数据集上取得了令人印象深刻的性能,然而,这些模型与人类的因果推理能力相比仍存在显著差距。
造成这种差距的原因之一在于,当下的因果推理模型往往仅能够从数据中捕获到经验性的因果模式,但是人类则能够进一步追求于对于因果关系的相对抽象的深入理解。如图1中例子所示,当观察到原因事件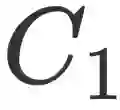
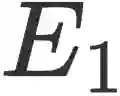
虽然这种概念性解释在因果推理过程中具有相当的重要性,迄今的因果推理数据集中尚未具备这一信息以支撑训练更强的、更接近人类表现的因果推理模型。为此,我们发表于ACL2022的文章e-CARE: a New Dataset for Exploring Explainable Causal Reasoning提供了一个人工标注的可解释因果推理数据集(explainable CAusal REasoning dataset, e-CARE)。e-CARE数据集包含超过2万个因果推理问题,这使得e-CARE成为目前最大的因果推理数据集。并且对于每个因果推理问题,提供了一个自然语言描述的,有关于因果关系为何能够成立的解释。下表提供了一个e-CARE数据集的例子。
Key |
Value |
Premise |
Tomholdsacopperblockbyhandandheatsitonfre. |
Ask-for |
Effect |
Hypothesis1 |
Hisfngersfeelburntimmediately.(✔) |
Hypothesis2 |
Thecopperblockkeepsthesame.(✖) |
ConceptualExplanation |
Copperisagoodthermalconductor. |
2. 基于e-CARE的因果推理相关任务
基于e-CARE数据集,我们提出了两个任务以评价模型因果推理能力:
1. 因果推理任务
2. 解释生成任务
2.1 因果推理:
这一任务要求模型从给定的两个候选hypothesis中选出一个,使得其与给定的premise构成一个合理的因果事实。例如,如下例所示,给定premise "Tom holds a copper block by hand and heats it on fire.", hypothesis 1 "His fingers feel burnt immediately."能够与给定premise构成合理的因果事件对。
{"index": "train-0","premise": "Tom holds a copper block by hand and heats it on fire.","ask-for": "effect","hypothesis1": "His fingers feel burnt immediately.","hypothesis2": "The copper block keeps the same.","label": 1}
2.2 解释生成:
这一任务要求模型为给定的由<原因,结果>构成的因果事件对生成一个合理解释,以解释为何该因果事件对能够存在。例如,给定因果事件对<原因: Tom holds a copper block by hand and heats it on fire. 结果: His fingers feel burnt immediately.>, 模型需要生成一个合理的解释,如"Copper is a good thermal conductor."。
{"index": "train-0","cause": "Tom holds a copper block by hand and heats it on fire.","effect": "His fingers feel burnt immediately.","conceptual_explanation": "Copper is a good thermal conductor."}
3. 数据集统计信息
问题类型分布
Ask-for |
Train |
Test |
Dev |
Total |
Cause |
7,617 |
2,176 |
1,088 |
10881 |
Effect |
7,311 |
2,088 |
1,044 |
10443 |
Total |
14,928 |
4,264 |
2,132 |
21324 |
解释信息数量
Overall |
Train |
Test |
Dev |
13048 |
10491 |
3814 |
2012 |
4. 数据集下载与模型性能评价
4.1 数据集下载
e-CARE的训练与开发集可以在以下链接下载:
https://github.com/Waste-Wood/e-CARE/files/8242580/e-CARE.zip
4.2 模型性能评测
我们在e-CARE数据集的基础上搭建了可解释因果推理评测榜单,榜单地址:https://scir-sp.github.io/。该可解释因果推理评测榜单包含了2个子榜单:因果推理榜单和因果解释生成榜单。
4.2.1 因果推理榜单
该榜单展示的是各模型在因果推理任务上的准确率(Accuracy),榜单当前的排名如下:
排名 |
模型 |
准确率(%) |
- |
HumanPerformance |
92.00 |
1 |
BERT-base-caed(Devinetal.,2019) |
75.38 |
2 |
ALBERT(Lanetal.,2019) |
74.60 |
3 |
XLNet-base-cased(Yangetal.,2019) |
74.58 |
4 |
BART-base(Lewisetal.,2020) |
71.65 |
5 |
RoBERTa-base(Liuetal.,2019) |
70.73 |
6 |
GPT-2(Radfordetal.,2019) |
69.51 |
7 |
GPT(Radfordetal.,2018) |
68.15 |
4.2.2 因果解释生成榜单
该榜单展示的是各模型在因果解释生成任务上的性能(平均BLEU值和Rouge-l值),榜单当前排名如下:
排名 |
模型 |
avg-BLEU(%) |
Rouge-l(%) |
- |
HumanPerformance |
35.51 |
33.46 |
1 |
GPT-2(Radfordetal.,2019) |
32.05 |
31.47 |
2 |
RNN(HochreiterandSchmidhuber,1997) |
18.09 |
20.85 |
目前在因果推理和因果解释生成的性能上,各模型的表现和人类的表现相比还存在较大差距。如何深入理解因果机制,依旧是一个非常值得探索与研究的问题。
4.3 评测提交流程
e-CARE数据集中的训练集和开发集是公开的,测试集是非公开的,模型的提交需要通过CodaLab的Worksheets进行,提交的流程大致分为一下几个步骤:
(1)封装自己的代码运行环境至docker,并把镜像上传至docker hub;
(2)上传代码及相关数据至CodaLab的Worksheets;
(3)使用模型在开发集上按照官方的输出要求跑出预测结果,并使用官方的评估指标计算脚本进行指标计算;
(4)提交测试集结果在Worksheet中的uuid至邮箱kxiong@ir.hit.edu.cn。
ldu@ir.hit.edu.cn
或者
详细的提交流程以及预测结果的输出格式要求可以参考:
https://github.com/Waste-Wood/e-CARE/blob/main/Submission%20Tutorial.md
官方评估指标计算脚本下载地址:
https://github.com/Waste-Wood/e-CARE/releases/tag/Scripts
欢迎大家踊跃参与评测,共同推动可解释因果推理领域的发展!
参考文献
[Devin et al., 2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
[Lan et al., 2019] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
[Yang et al., 2019] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237.
[Lewis et al., 2020] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequenceto-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880.
[Liu et al., 2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.
[Radford et al., 2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
[Radford et al., 2018] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[Hochreiter and Schmidhuber, 1997] Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):17351780.
本期责任编辑:冯骁骋
本期编辑:牟虹霖
哈尔滨工业大学社会计算与信息检索研究中心
理解语言,认知社会
以中文技术,助民族复兴

