CVPR 2022 | 一键解锁微软亚洲研究院计算机视觉领域前沿进展!

(本文阅读时间:17分钟)

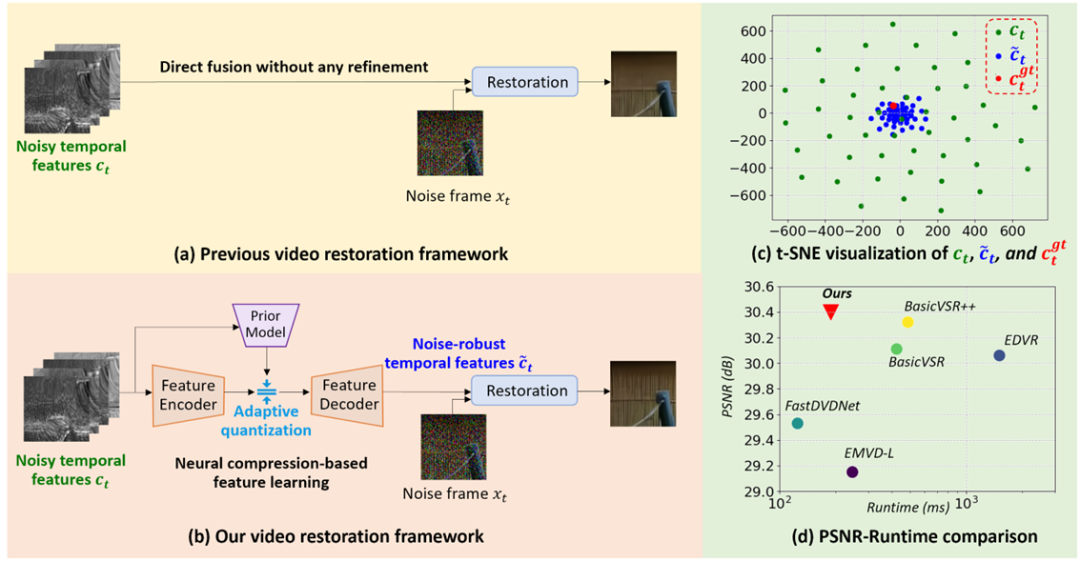



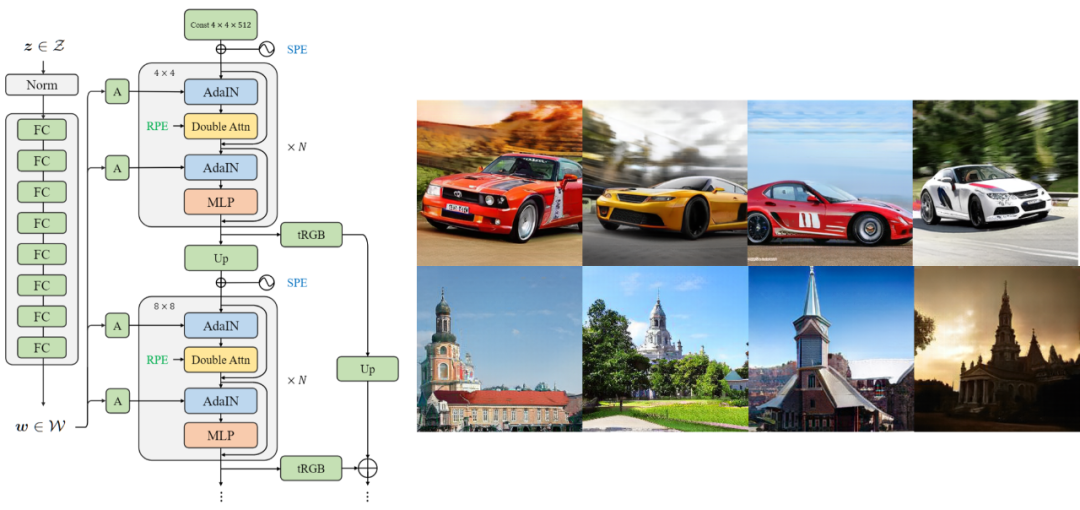

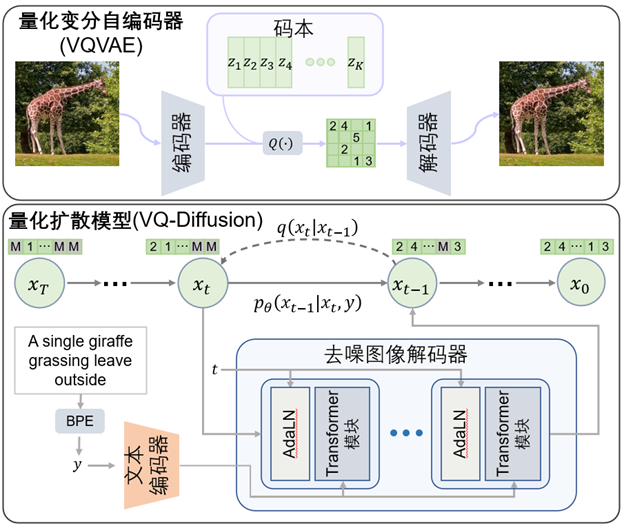

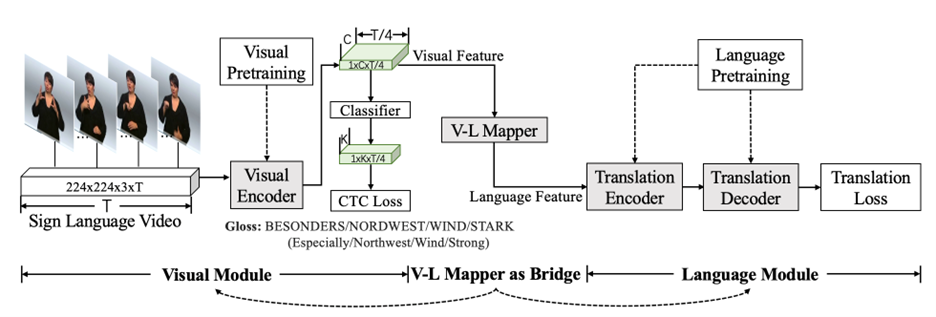



你也许还想看:





登录查看更多
相关内容
专知会员服务
27+阅读 · 2022年3月3日



相关VIP内容
专知会员服务
27+阅读 · 2022年3月3日
相关资讯
相关论文