随着在线视频平台的迅猛增长和视频内容量的激增,对于精通视频理解工具的需求显著增强。大型语言模型(LLMs)在关键语言任务中展现出惊人的能力,这项综述为利用大型语言模型的视频理解的最新进展(Vid-LLMs)提供了详细概览。Vid-LLMs的新兴能力令人惊讶地先进,特别是它们结合常识知识的开放式空间-时间推理能力,为未来的视频理解展示了一条有希望的路径。我们检查了 Vid-LLMs 的独特特征和能力,将方法分为四大类:基于LLM的视频智能体,Vid-LLMs预训练,Vid-LLMs指令微调,以及混合方法。此外,这项综述还全面研究了 Vid-LLMs 的任务和数据集,以及用于评估的方法。此外,综述还探讨了 Vid-LLMs 在各个领域的广泛应用,从而展示了它们在应对现实世界视频理解挑战方面的显著可扩展性和多功能性。最后,综述总结了现有 Vid-LLMs 的局限性和未来研究的方向。欲了解更多信息,我们建议读者访问 https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding 存储库。
https://www.zhuanzhi.ai/paper/c42b526b0e901d003d2dd0d6d677fac5
我们生活在一个多模态的世界中,视频已成为最常见的媒体形式,这在一定程度上得益于互联网技术,特别是移动互联网技术的发展。随着在线视频平台的快速扩张和监控、娱乐、自动驾驶中相机的日益普及,视频内容已成为一种关键且吸引人的媒介,其丰富性和吸引力超越了传统的文本和图文结合形式。这一进步促使视频制作呈指数级增长,每天都有数以百万计的视频被创作出来。然而,手动处理如此庞大的视频内容既费时又费力。因此,对于能够有效管理、分析和处理这些大量视频内容的工具的需求日益增长。为了满足这一需求,视频理解和分析技术应运而生,利用智能分析技术。该技术旨在自动识别和解释视频内容,从而减轻人类操作者的负担。
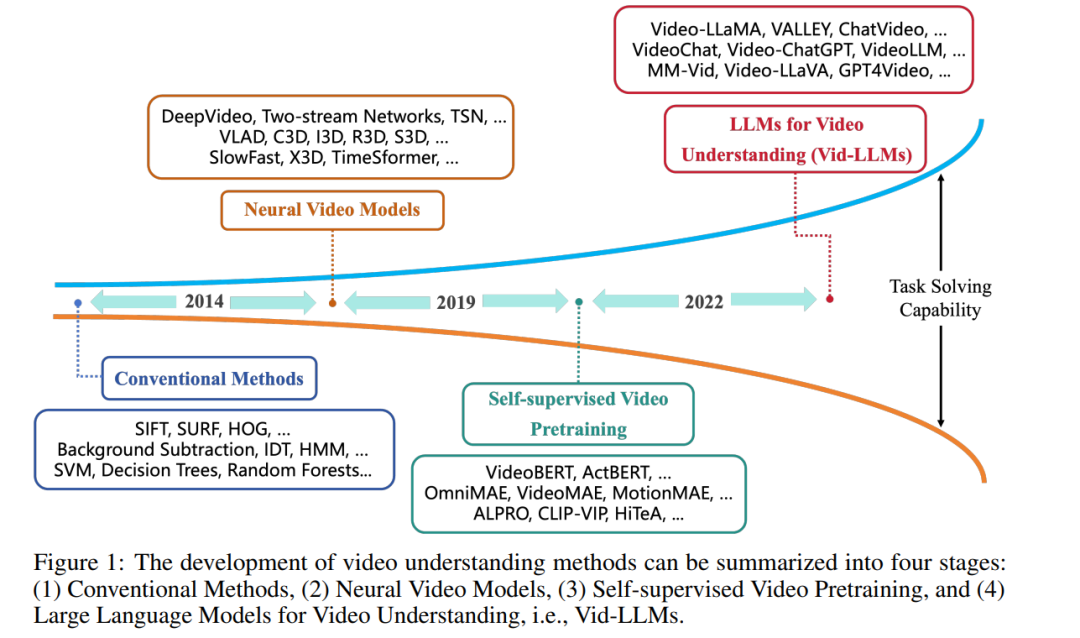
正如图1所示,视频理解方法的演变可分为四个阶段: 传统方法。在视频理解的早期阶段,使用了手工特征提取技术,如尺度不变特征变换(SIFT)[1]、加速稳健特征(SURF)[2]和定向梯度直方图(HOG)[3]来捕捉视频中的关键信息。背景减除[4]、光流方法[5]和改进的密集轨迹(IDT)[6, 7]用于跟踪建模运动信息。由于视频可以被视为时间序列数据,因此也使用了隐藏马尔可夫模型(HMM)[8]等时间序列分析技术来理解视频内容。在深度学习普及之前,也使用了基本的机器学习算法,如支持向量机(SVM)[9]、决策树和随机森林,用于视频分类和识别任务。集群分析[10]用于分类视频段落,或主成分分析(PCA)[11, 12]用于数据降维,也是视频分析中常用的方法。
神经视频模型。与经典方法相比,用于视频理解的深度学习方法具有更优越的任务解决能力。DeepVideo[13]是最早将深度神经网络引入视频理解的方法,具体是卷积神经网络(CNN)。然而,由于对运动信息的使用不足,其性能并未超过最佳手工特征方法。双流网络[14]结合了CNN和IDT来捕获运动信息以提高性能,验证了深度神经网络在视频理解方面的能力。为了处理长视频理解,采用了长短时记忆(LSTM)[15]。时间段网络(TSN)[16]也为长视频理解而设计,通过单独分析视频段然后聚合它们。基于TSN,引入了Fisher向量(FV)编码[17]、双线性编码[18]和局部聚合描述符(VLAD)[19]编码[20]。这些方法在UCF-101[21]和HMDB51[22]数据集上提高了性能。与双流网络不同,3D网络通过引入3D CNN到视频理解(C3D)[23]开启了另一分支。膨胀的3D ConvNets(I3D)[24]利用了2D CNN,即Inception[25]的初始化和架构,在UCF-101和HMDB51数据集上取得了巨大的进步。随后,人们开始使用动力学-400(K-400)[26]和某些事物(Something-Something)[27]数据集来评估模型在更具挑战性的场景中的性能。ResNet[28]、ResNeXt[29]和SENet[30]也从2D转向3D,导致了R3D[31]、MFNet[32]和STC[33]的出现。为了提高效率,3D网络在各种研究中被分解为2D和1D网络(例如,S3D[34]、ECO[35]、P3D[36])。LTC[37]、T3D[38]、Non-local[39]和V4D[40]专注于长期时间建模,而CSN[41]、SlowFast[42]和X3D[43]则致力于高效率。引入视觉变压器(ViT)[44]促进了一系列杰出模型的出现(例如,TimeSformer[45]、VidTr[46]、ViViT[47]、MViT[48])。
自监督视频预训练。自监着学习预训练模型[51]在视频理解方面的可转移性[49, 50]使它们能够在最小额外标注的情况下跨多种任务泛化,克服了早期深度学习模型对大量特定任务数据的需求。VideoBERT [52] 是进行视频预训练的早期尝试。它基于双向语言模型BERT [53],为自监着学习设计了与视频-文本数据相关的任务。它使用层次性k-means对视频特征进行标记化。预训练模型可以微调以处理多个下游任务,包括动作分类和视频字幕。遵循“预训练”和“微调”范式,出现了大量针对视频理解的预训练模型研究,特别是视频-语言模型。它们要么使用不同的架构(ActBERT [54]、掩蔽自动编码器作为空时学习者 [55]、OmniMAE [56]、VideoMAE [57]、MotionMAE [58]),要么采用预训练和微调策略(MaskFeat [59]、VLM:任务不可知[60]、ALPRO [61]、全能变压器 [62]、maskViT [63]、CLIP-ViP [64]、揭示视频-语言学习的单帧偏见 [65]、LF-VILA [66]、EMCL [67]、HiTeA [68]、CHAMPAGNE [69])。
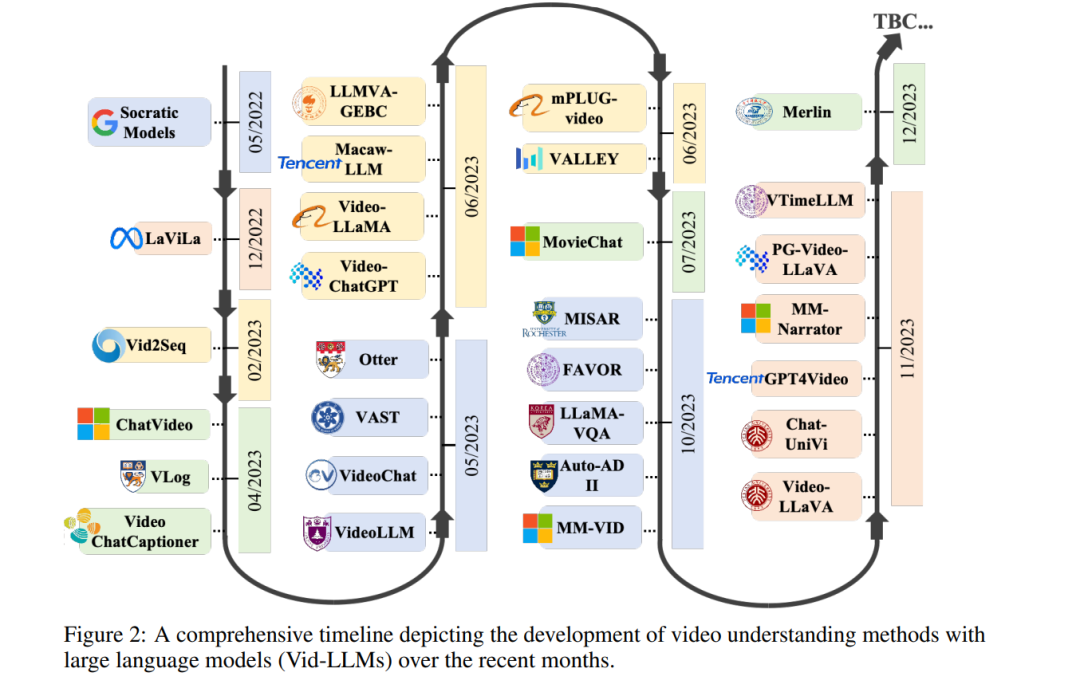
大型语言模型用于视频理解。最近,大型语言模型(LLMs)迅速进步[70]。在大量数据集上预训练的大型语言模型的出现引入了新的情境学习能力[71]。这使它们能够使用提示来处理多种任务,而不需要微调。ChatGPT [72] 是基于这一基础的第一个开创性应用。这包括生成代码和调用其他模型的工具或API的能力等。许多研究正在探索使用像ChatGPT这样的LLMs来调用视觉模型API,解决计算机视觉领域的问题,包括Visual-ChatGPT [73]。指令调整的出现进一步增强了这些模型有效响应用户请求和执行特定任务的能力。集成视频理解能力的LLMs提供了更复杂的多模态理解优势,使它们能够处理和解释视觉和文本数据之间的复杂交互。类似于它们在自然语言处理(NLP)[74]中的影响,这些模型作为更通用的任务解决器,擅长处理更广泛的任务范围,利用它们从大量多模态数据中获得的广泛知识库和情境理解。这使它们不仅能理解视觉内容,还能以更符合人类理解的方式推理。许多工作也在探索使用LLMs进行视频理解任务,即Vid-LLMs。 以前的综述论文要么研究视频理解领域的特定子任务,要么关注视频理解之外的方法。例如,[75]综述了通用视觉-语言任务的多模态基础模型,包括图像和视频应用。[76]和[77]分别专注于视频字幕和视频动作识别任务的综述。其他视频理解任务,如视频问答和定位未被考虑。此外,[78]和[79]分别调研了视频相关方法
——视频扩散模型和LLMs,缺乏对视频理解的专注。尽管对社区有重要价值,但以前的综述论文在基于大型语言模型调研一般视频理解任务方面留下了差距。本文通过对使用大型语言模型的视频理解任务进行全面综述来填补这一差距。
本综述结构如下:第2节提供了全面概述,强调利用LLMs能力的方法,并详细介绍这些方法解决的具体任务和数据集。第3节深入探讨了利用LLMs进行视频理解的最新研究,介绍了它们在该领域的独特方法和影响。第4节提供了各种任务、相关数据集和评估指标的详细总结和分析。第5节探索了Video-LLMs在多个重要领域的应用。综述在第6节总结关键发现,并识别未解决的挑战和未来研究的潜在领域。
除了这篇综述外,我们还建立了一个GitHub存储库,汇集了用于大型语言模型(Vid-LLMs)视频理解的各种支持资源。这个专注于通过Vid-LLMs增强视频理解的存储库可以在Awesome-LLMs-for-Video-Understanding中访问。

基础
视频理解是一个充满挑战的任务,它激发了众多创新任务的创造,目的是增强模型解释视频内容的能力。从视频分类和动作识别的基础任务出发,该领域已经演化为包括更复杂的任务。这些任务范围从带有详细描述的视频字幕,到视频问答。后者不仅需要理解视频内容,还需要运用逻辑和常识知识进行推理以制定回答。随着我们在这一领域的进步,任务变得越来越复杂和具有挑战性,需要模型能够像人类一样直观地解释视频。我们将视频理解的主要任务总结如下:
识别与预测。这些任务在视频理解中形成了一对紧密结合的双胞胎,强调视频中的时间连续性和进展。 字幕和总结。专注于更细致的细节,这些任务涉及提供每个时刻的准确和具体的文本描述,并提炼视频的精髓,捕捉主要主题和关键叙述。这些任务提供了对视频内容的微观和宏观理解,结合了以细节为导向的洞察力和更广阔的视角。
定位和检索。无缝地将视觉内容与文本上下文联系起来,这类任务要求模型识别出与提供的文本描述准确对应的特定视频或片段。
问答。这些任务强调模型不仅要理解视频的视觉和听觉组成部分,还要整合外部知识和推理能力,提供与上下文相关的答案。
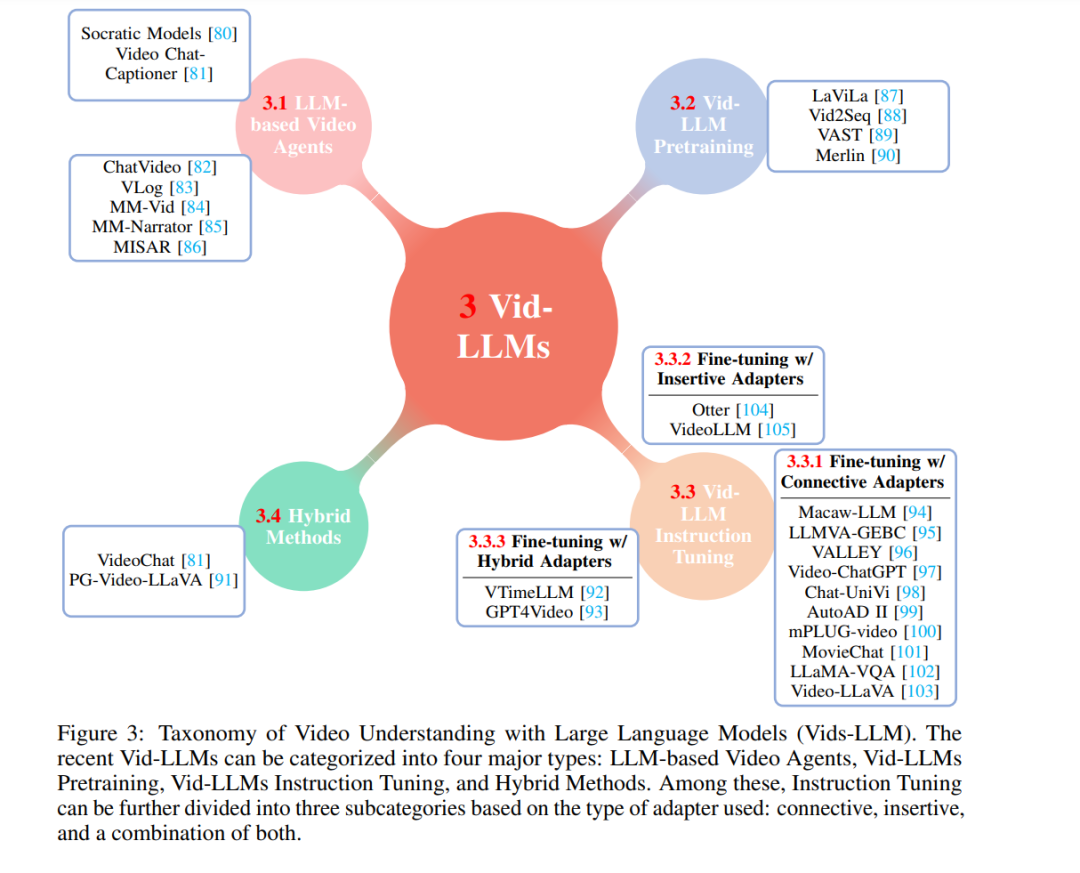
随着具有挑战性的任务的发展,模型的进展反映了它们设计用来解决的任务的日益复杂化。从处理有限数量帧以将视频分类为预定义标签的经典方法(反映了理解的狭窄范围)到更复杂模型的出现,视频分类的视野发生了巨大扩张。现代大型模型现在能够处理数百帧,使它们不仅能生成详细的文本描述,还能回答有关视频内容的复杂问题。这种能力的飞跃标志着从经常难以泛化的任务特定、经典方法向更多功能和综合方法的重大转变。将LLMs整合到视频理解中目前由四个主要策略引领:
基于LLM的视频智能体。在这种方法中,LLMs充当中心控制器。它们指导视觉模型有效地将视频中的视觉信息翻译到语言领域。这包括提供详细的文本描述和转录音频元素。 Vid-LLM预训练。该方法重点使用监督或对比训练技术从头开始开发基础视频模型。在这个框架中,LLMs作为编码器和解码器,提供全面的视频理解方法。 Vid-LLM指令调整。这种策略涉及构建专门的调整数据集,以微调视觉模型与LLMs的整合,特别是为视频领域量身定制。 混合方法。这些策略利用视觉模型在微调过程中提供额外的反馈。这种协作方法使模型能够获得超越文本生成的技能,如对象分割和其他复杂的视频分析任务。 接下来,我们将分解LLMs的关键组成部分,并仔细研究它们如何与基础模型一起工作以改进视频理解。