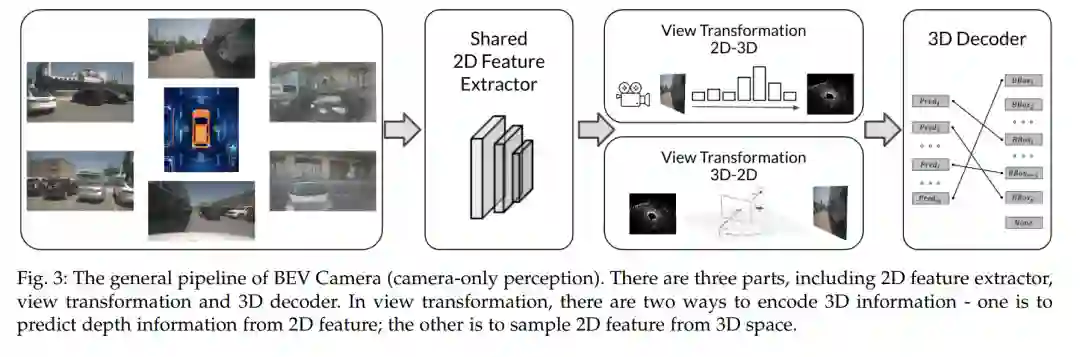
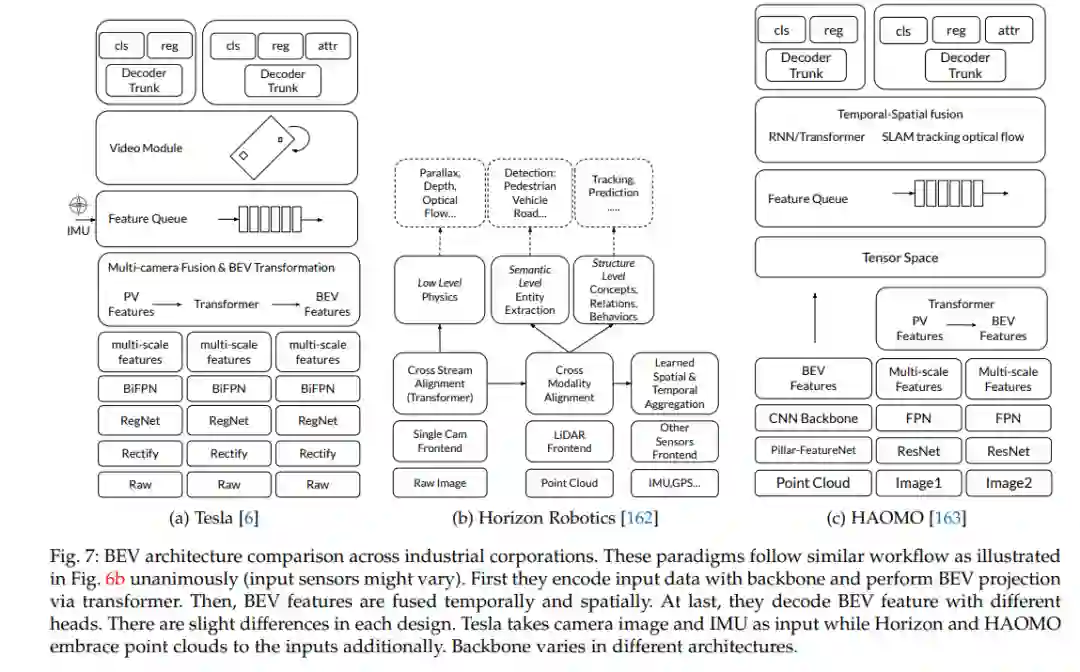
从鸟瞰视角学习感知任务中的强表示是当前业界和学术界广泛关注的一个趋势。大多数自动驾驶算法的传统方法都是在正面或透视视图中执行检测、分割、跟踪等。随着传感器配置越来越复杂,集成来自不同传感器的多源信息并在统一视图中表示特征变得至关重要。BEV感知继承了几个优点,因为在BEV中表示周围的场景是直观的和友好的融合;和在BEV中表示对象是最可取的后续模块,如规划和/或控制。BEV感知的核心问题在于: (a) 如何通过透视视图到BEV的视图转换重建丢失的三维信息; (b)如何获取BEV网格中的真实注释; (c)如何制定整合不同来源和不同观点特色的途径;以及(d)当传感器配置在不同场景中不同时,如何适应和推广算法。本综述回顾了关于BEV感知的最新工作,并对不同的解决方案进行了深入分析。此外,还描述了业界对BEV方法的几种系统设计。此外,我们还介绍了一整套实用指南来提高BEV感知任务的性能,包括相机、激光雷达和融合输入。最后,指出了该领域未来的研究方向。我们希望这份报告能对社区有所启发,并鼓励对BEV感知进行更多的研究。我们有一个活跃的存储库来收集最新的工作,并在 https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe上提供了一个工具箱。
导论
自动驾驶中的感知识别任务本质上是对物理世界的三维几何重建。随着自动驾驶汽车(SDV)装备传感器的多样性和数量越来越复杂,以统一的视角表示不同视角的特征变得至关重要。著名的鸟瞰视图(BEV)是一种自然而直接的候选视图,可以作为统一的表示。与二维视觉领域中被广泛研究的前视图或透视视图相比,BEV表示具有一些内在的优点。首先,它不存在二维任务中普遍存在的遮挡和尺度问题。识别有遮挡或交叉交通的车辆可以得到更好的解决。此外,以这种形式表示物体或道路元素将有利于后续模块(如规划、控制)的开发和部署。
在本研究中,我们将BEV Perception一词用于自动驾驶车辆的BEV视图表示的所有视觉算法。请注意,我们并不打算夸大BEV的概念作为一个新的研究概念;相反,如何在BEV视图下制定新的管道或框架,更好地融合来自多个传感器输入的特征,值得社会各界更多的关注。
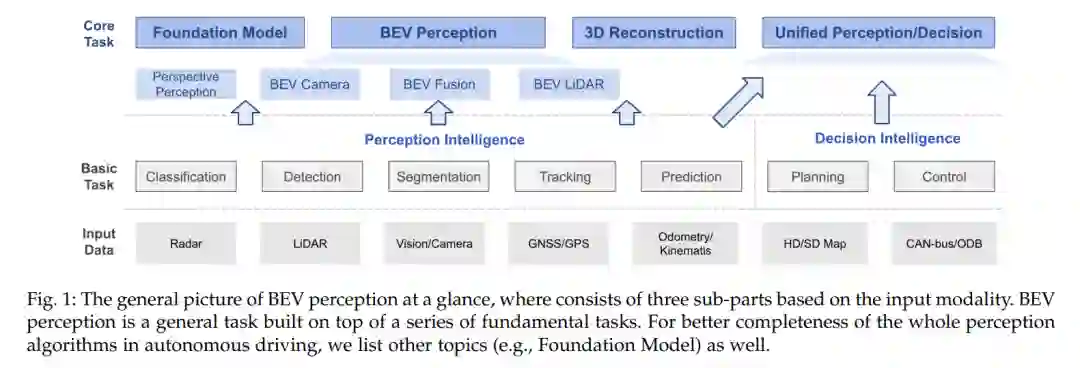
说到BEV感知研究的动机,有三个重要方面需要考察。
**意义。**BEV感知会对学术界和/或社会产生真正有意义的影响吗?众所周知,基于相机或视觉的解决方案与基于激光雷达或融合的解决方案之间存在巨大的性能差距。例如,截至2022年8月提交,就nuScenes数据集[7]上的NDS而言,排名第一的方法在仅视觉和LiDAR之间的差距超过20%。在Waymo基准[8]上,差距甚至超过了30%。这自然促使我们去研究视觉解决方案是否能够打败或与激光雷达方法相媲美。 从学术角度来看,设计一个基于相机的管道,使其性能优于激光雷达,其本质是更好地理解从2D外观输入到3D几何输出的视图转换过程。如何像在点云中那样将相机特征转换成几何表示形式,对学术界有着重要的影响。从工业角度考虑,一套激光雷达设备进入SDV的成本是昂贵的;原始设备制造商(原始设备制造商,如福特、宝马等)更喜欢对软件算法进行廉价且准确的部署。将只使用相机的算法改进为激光雷达的算法自然就达到了这一目标,因为相机的成本通常是激光雷达的10倍。此外,基于相机的管道可以识别远距离目标和基于颜色的道路元素(如交通灯),这两种方法都是激光雷达无法识别的。 尽管基于相机和基于激光雷达的感知有几种不同的解决方案,但就优越的性能和业界友好的部署而言,BEV表示是基于激光雷达的方法的最佳候选方案之一。此外,最近的趋势表明,BEV表示在多摄像机输入方面也有巨大的进步。由于相机和激光雷达数据可以投影到BEV空间,BEV的另一个潜力是我们可以很容易地在统一的表示下融合来自不同模态的特征。
**空间。**BEV认知中是否存在需要大量创新的开放性问题或注意事项?BEV感知背后的要点是从相机和激光雷达输入中学习一个鲁棒的和可泛化的特征表示。这在LiDAR分支中很容易,因为输入(点云)具有这样的3D属性。这在相机分支中是非常重要的,因为从单目或多视图设置中学习3D空间信息非常困难。虽然我们看到有一些尝试通过姿态估计[9]或时间运动[10]来学习更好的2D-3D对应关系,但BEV感知背后的核心问题需要从原始传感器输入进行深度估计的实质性创新,特别是对于相机分支。另一个关键问题是如何在管道的早期或中期整合功能。大多数传感器融合算法将该问题视为简单的对象级融合或沿着Blob通道进行简单的特征拼接。这也许可以解释为什么由于相机和激光雷达之间的不对中或不准确的深度预测,一些融合算法的表现不如激光雷达解决方案。如何从多模态输入中对齐和整合特征至关重要,从而留下广阔的创新空间。
**准备就绪。**关键条件(如数据集、基准)是否准备好进行BEV感知研究?简短的回答是肯定的。由于BEV感知同时需要相机和激光雷达,2D和3D物体之间的高质量注释和准确对齐是此类基准的两个关键评估。KITTI[11]较为全面,在早期自动驾驶研究中备受关注,而Waymo[8]、nuScenes[7]、Argoverse[12]等大规模、多样化的基准为验证BEV感知思想提供了坚实的平台。这些新提出的基准通常包括高质量的标签;场景多样性和数据量也在很大程度上扩大。此外,这些排行榜上的开放挑战[13]为保留测试数据提供了一个公平的设置,所有的先进水平都可以在开放和及时的意义上进行比较。在算法准备方面,近年来通用视觉出现了很大的发展,其中Transformer[14]、ViT[15,16]、mask Auto-encoders (MAE)[17]和CLIP[18]等比传统方法获得了令人印象深刻的增益。我们相信这些工作将有利于和激励伟大的BEV感知研究。
基于以上三个方面的讨论,总结出BEV感知研究具有巨大的潜在影响,值得学术界和产业界长期关注并投入大量精力。与最近关于三维物体检测的研究[19,20,21,22,23]相比,我们的研究不仅在更高的层次上总结了最近的BEV感知算法,并将其形成了一个通用的管道,而且在这种背景下提供了有用的方法,包括基于摄像机和基于LiDAR设置的可靠数据增强、高效的BEV编码器设计、感知头和损失函数族、有用的测试时间增强(TTA)和集成策略等。我们希望这个调研可以成为一个好的起点,为新初学者和当前的研究人员在这个社区有深刻的讨论。
这项综述的主要贡献有三个方面。1) 综述了近年来BEV感知研究的总体情况,包括高层次的理念和深入的详细讨论。2) 对BEV感知文献进行了综合分析。涵盖了深度估计、视图变换、传感器融合、域自适应等核心问题。介绍和讨论了几种重要的电动汽车感知工业系统级设计。3) 除了理论贡献外,我们还提供了一个实用的操作指南,以提高在各种BEV感知任务中的表现。这样的发布可以帮助社区在“抓取即走”的菜谱意义上实现更好的性能。