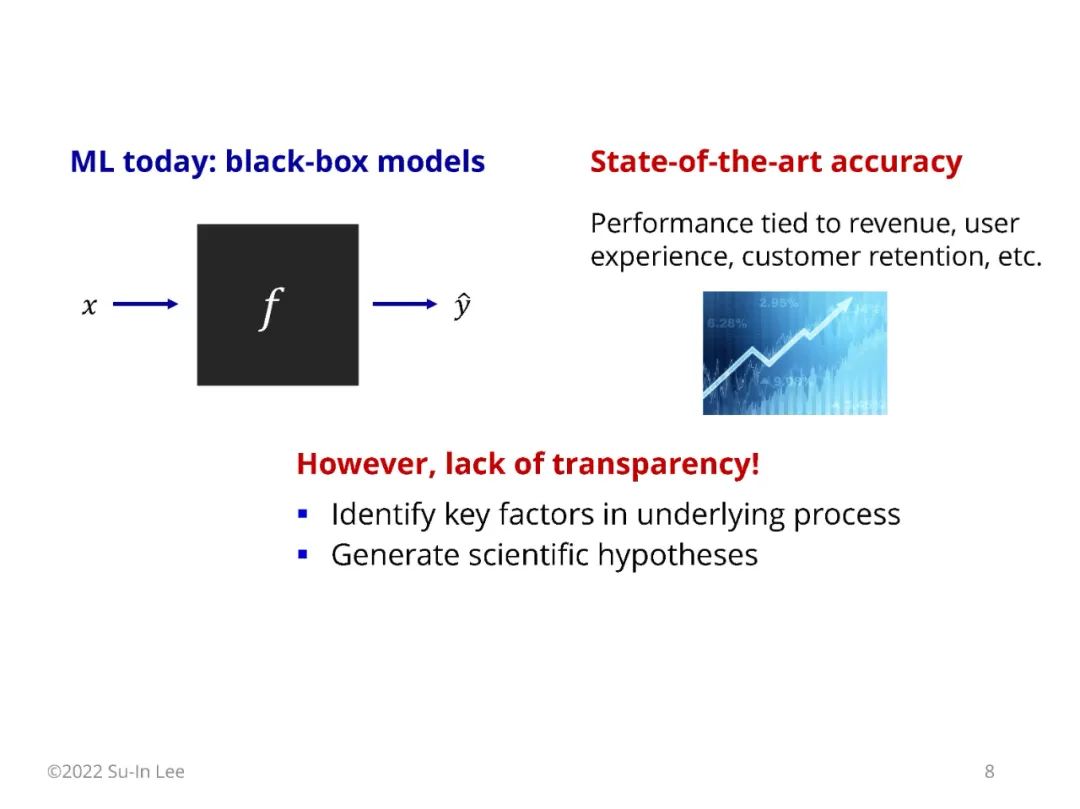
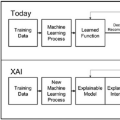
本课程是关于可解释人工智能(XAI)的,这是机器学习的一个分支领域,为复杂模型提供透明度。现代机器学习严重依赖于黑盒模型,如树集成和深度神经网络;这些模型提供了最先进的准确性,但它们使理解驱动其预测的特征、概念和数据示例变得困难。因此,用户、专家和组织很难信任这样的模型,并且了解我们正在建模的底层过程是具有挑战性的。 对此,一些人认为,我们应该在高风险应用中依赖内在可解释的模型,如医药和消费金融。其他人主张事后解释工具,即使是为复杂的模型提供一定程度的透明度。本课程探讨了这两种观点,我们将讨论广泛的工具,以解决模型如何进行预测的不同问题。我们将涵盖该领域许多活跃的研究领域,包括特征归因、反事实解释、实例解释和人类- ai合作。 本课程共设10节课(每节3小时),课程结构如下:
介绍与动机 特征重要性:基于删除的解释,基于传播的解释,评估指标 其他解释范式:固有可解释性模型、概念解释、反事实解释、实例解释、神经元解释 人机协作 工业应用
Lecture 1: Introduction * Lecture 2: Removal-based explanations * Lecture 3: Shapley values * Lecture 4: Propagation and gradient-based explanations * Lecture 5: Evaluating explanation methods * Lecture 6: Inherently interpretable models * Lecture 7: Concept-based explanations, neuron interpretation * Lecture 8: Counterfactual explanations, instance explanations * Lecture 9: Enhancing human-AI collaboration * Lecture 10: Model improvement, applications in industry and healthcare