© 作者|蒋锦昊机构|中国人民大学研究方向|自然语言处理、大语言模型 知识图谱(KG)作为一种重要的知识来源,如何将其与大语言模型(LLM)相结合受到了学术界广泛的关注。考虑到 LLM 的通用性,通常以外挂 KG 的形式增强 LLM,一般被称为 协作增强 的方法。这类方法通常会设计一种在 KG 和 LLM 之间进行信息交互的机制以求解目标问题。然而,目前的交互机制不够自主和灵活且对闭源超大模型(例如 GPT-4)依赖程度较高。为解决上述问题,我们提出了一个名为 KG-Agent 的自主 LLM-based 代理框架,它使得一个相对小型的 LLM(7B)也能够在知识图谱上自主决策,完成推理过程。在 KG-Agent 中,我们整合了 LLM、多功能工具箱、基于知识图谱的执行器和知识记忆器,并设计了一个迭代机制,通过自主选择工具-更新记忆,以进行知识图谱推理。文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!

研究背景与动机
尽管在各种自然语言处理任务上表现出色, 大语言模型 (LLMs) 在仅基于其参数知识解决复杂任务方面仍有局限性,例如多跳和知识密集型推理。知识图谱 (KG) 以图结构格式存储大量知识三元组,已被广泛用于为LLMs提供外部知识补充。获得的奖励。由于知识图谱(KG)的超大数据量和结构化组织格式,大型语言模型(LLMs)难以有效利用 KG 中的信息。近期的工作主要采用 检索增强 或 协同增强 的方法来增强 LLMs 对 KG 数据的利用。前一种方法检索并序列化与任务相关的三元组,作为 LLMs 提示的一部分,而后一种方法设计了 KG 和 LLMs 之间的信息交互机制,以迭代方式找到问题的解决方案。特别是,协同增强方法可以利用基于 KG 的结构化搜索(例如 SPARQL)和 LLMs 的语言理解能力,达到与之前最先进方法相当或更好的性能。尽管取得了一定成功,现有的协同增强方法仍然存在两个主要限制:1. LLM 和 KG 之间的信息交互机制通常是预定义的(例如,遵循人工设计的多轮计划),不能灵活地适应各种复杂任务。例如,在推理过程中处理非计划中的需求(例如,不同难度的问题或约束操作)时可能会变得无效。2. 这些方法大多依赖于更强大的闭源 LLM API(例如,ChatGPT 和 GPT-4)来理解或学习解决复杂任务。然而,这些蒸馏的计划或程序,也限制于特定任务设置或能力水平,可能并不最适合指导这些较弱的模型。
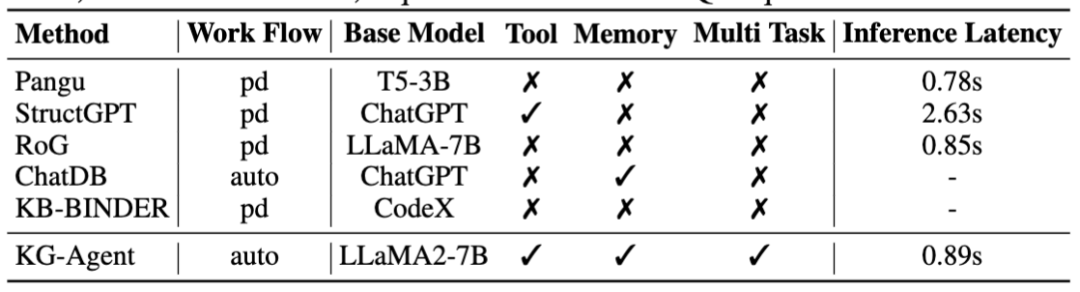
表1 KG-Agent与各类方法对比为了解决这些问题,本文提出了 KG-Agent,这是一种基于大型语言模型(LLM)的自主代理框架,用于对知识图谱(KG)进行复杂推理任务。其动机有两方面:1. 设计自主推理方法,使其在推理过程中能够主动做出决策,无需人工干预;2. 使相对较小的模型(例如7B LLM)能够有效执行复杂推理任务,而无需依赖封闭源代码的 LLM API。 为实现这一目标,我们的方法在技术上有三大贡献:1. 我们通过策划一个多功能工具箱扩展了 LLM 操作结构化数据的能力,使LLM能够对 KG 数据和中间结果执行离散或高级操作(例如过滤、计数和检索)。2. 我们利用现有的 KG 推理数据集合成基于代码的指令数据来微调 LLM,首先根据 KG 上的推理链生成程序,然后合成指令数据。 3. 我们提出了一种基于工具选择和记忆更新的自主迭代机制,将微调后的 LLM、多功能工具箱、基于 KG 的执行器和知识记忆结合起来,实现对 KG 我们在领域内和领域外任务上进行了广泛的评估(例如基于知识图谱的问题回答(KGQA) 和开放域问题回答(ODQA)),验证了我们的 KG-Agent 的有效性。我们将我们的贡献和结果总结如下:1. 自主和通用的 KG Agent:据我们所知,KG-Agent是第一个使用相对较小的 LLM(7B)开发自主代理的方法。2. 高效的训练和推理:KG-Agent 仅在10K个样本上进行训练 (例如 GrailQA 的22.6%),并具有较低的推理延迟 (例如相比于 StructGPT,推理速度几乎提高了3倍)。 3. 高效的训练和推理:KG-Agent 仅在10K个样本上进行训练 (例如 GrailQA 的22.6%),并具有较低的推理延迟 (例如相比于 StructGPT,推理速度几乎提高了3倍)。
KG-Agent
**
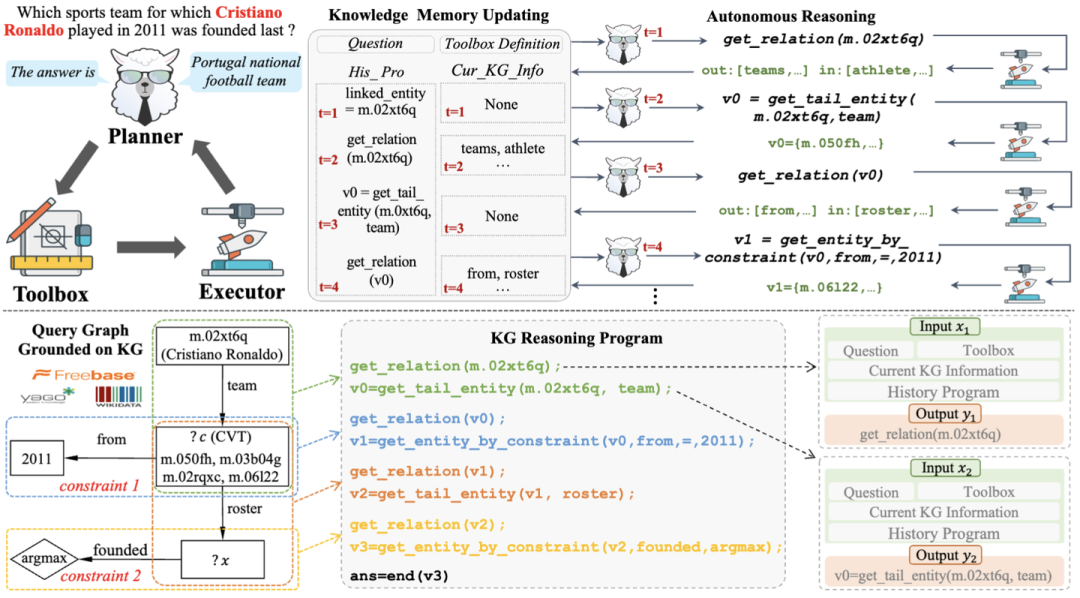
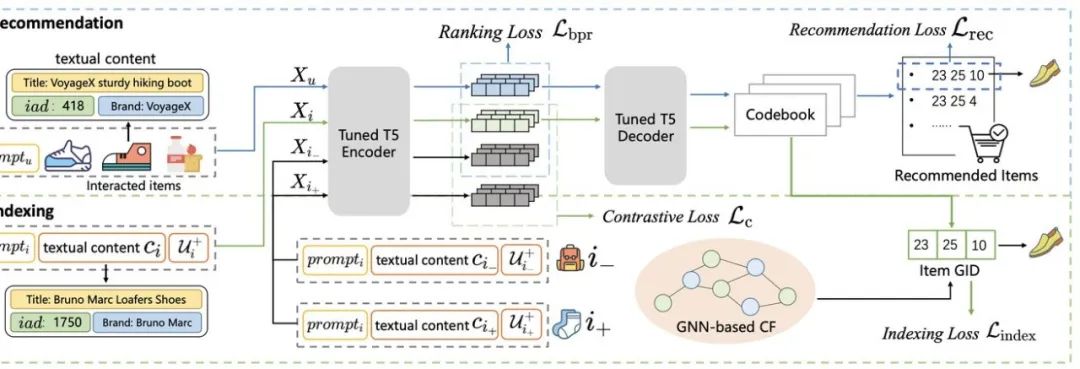
图1 KG-Agent整体框架图
KG-Agent 框架的核心是一个指令微调的 LLM,它可以在知识图谱上自主决策推理。首先,通过设计一个工具箱来扩展 LLM 的能力,工具箱中包含支持操作 KG 数据或中间结果的工具。为了增强逐步推理的能力,我们利用现有的知识图谱问答(KGQA)数据集来合成 KG 推理程序,并将其转换为格式化的指令调优数据。最后,我们基于知识记忆器设计了一个有效的代理框架,以支持在知识图谱上的自主推理。 多功能工具箱 由于 LLMs 难以准确地操作结构化数据,我们构建了一个多功能工具箱,以支持 LLM 更好地利用 KG 信息。根据已有工作,在 KG 上推理通常需要三个基本操作,即从 KG 中提取信息、根据问题的语义过滤不相关的信息以及对提取的信息进行操作。因此,我们为 LLMs 在 KG 上的推理设计了三种类型的工具,即提取工具、语义工具和逻辑工具。详情可参考论文中的 Table 9. KG-Agent 指令微调 为了实现自主推理过程,我们构建了一个高质量的指令数据集,用于微调一个小型 LLM(例如 LLaMA2-7B)。为此,我们首先利用现有的基于知识图谱问答(KGQA)数据集来生成知识图谱推理程序,然后将其分解为多个步骤。最后,将每个步骤表述为包含输入和输出的指令数据。 (1)KG推理程序生成 我们建议利用现有的 KGQA 数据集来合成 KG 推理程序,而不是从闭源的大型语言模型(例如 GPT-4)中提取。这些 KGQA 数据集包含带注释的 SQL 查询,可以直接执行以提取每个问题的答案实体。特别是,SQL 查询通常包括关系链、条件或约束,这些对推理程序的合成是有益的。具体来说,我们首先将 SQL 查询映射到知识图谱(KG)上以获得查询图,然后从查询图中提取推理链和约束条件,最后将链分解成多个代码片段作为推理程序。 推理链生成 由于整个 KG 非常大且包含不相关的数据,第一步是获取与问题相关的小型知识图谱子图,称为查询图。按照之前的工作,我们通过规则匹配从知识图谱中获得查询图。如图所示,查询图具有类似树状的结构,可以直接映射到逻辑形式,并且可以描述SQL查询的执行流程以获取答案。其次,从问题中提到的实体(如克里斯蒂亚诺·罗纳尔多)开始,我们采用广度优先搜索(BFS)访问查询图上的所有节点。这一策略最终会生成一个推理链(如teams→→roster_team)将起始实体链接到答案实体,并且相关的约束条件(如 roster_from = "2011")或数值操作(如 founded 必须是最近的)可以自然地包含在此过程中。 推理程序生成 在提取推理链后,我们将其转换为多个相互关联的三元组,每个三元组通常对应一个中间推理步骤。最后,我们将这些三元组重新表述为代码格式的几个函数调用,这些调用代表工具的调用,并且可以执行以基于 KG 获得相应的三元组。给定一个三元组 <e, r, e'>,我们设计了一种基于规则的方法来合成代表从 e 到 e' 的信息流的函数调用。具体来说,我们从 get_relation(e) 函数调用开始,以获取与 e 在知识图谱上关联的当前候选关系 {r}。然后,我们选择一个关系 r 并将其传递给其他所需的函数调用(例如 get_tail_entity 或 get_entity_by_constraint ),并最终获得新实体。按照推理链的顺序,我们生成所有函数调用以组成最终的知识图谱推理程序,用于生成指令数据集。我们在图1中展示了一个示例,以直观地说明从注释的 SQL 查询到我们所需的知识图谱推理程序的转换过程。 (2)KG 推理指令合成 在获取到KG上的推理程序后,我们进一步利用它来合成用于监督微调(SFT)的指令数据。我们的指令数据高度基于推理程序,并与 KGQA 的中间推理步骤一致。 输入-输出对构建 合成的知识图谱(KG)推理程序由多个函数调用按顺序组成。对于每个函数调用,我们旨在构建一个输入-输出对作为指令。具体来说,输入包含问题、工具箱定义、当前的KG信息(即当前实体集的下一跳候选关系)以及当前步骤之前的历史推理程序;输出则是当前步骤的函数调用。接下来,在当前推理步骤执行函数调用后,输入中的历史推理程序和当前KG信息将相应更新,而输出将更新为下一步骤的函数调用。通过对上述过程进行迭代,对于知识图谱问答(KGQA)数据集中的每个样本,我们可以获得多个由相应推理程序导出的输入-输出对,它们描述了在知识图谱上的完整推理轨迹。为了帮助 LLM 更好地理解,我们进一步利用一个统一的提示,如图1所示,来格式化每个输入-输出对,并获得最终的指令调整数据。 代理指令微调 基于上述格式化的指令微调数据,我们对一个小型语言模型(例如 LLaMA2-7B )进行监督微调,这个模型比之前工作的基础模型要小得多。

基于KG自治推理 在指令调优之后,我们进一步设计了一个有效的代理框架,使 KG- Agent 能够在 KG 上自主地执行多步推理来寻找答案。KG-Agent的整体示意图如图1所示。它主要包含四个部分: 核心的指令调优 LLM,简称 基于 LLM 的规划器,多功能工具箱,执行工具调用的执行器,以及记录整个过程中上下文和当前有用信息的知识存储器。 知识记忆器初始化 知识存储器保留了当前有用的信息,以支持基于 LLM 的规划器进行决策。它主要包含四部分信息,即自然语言问题、工具箱定义、当前 KG 信息和历史推理程序。前两部分用给定的问题和工具箱定义初始化,在推理过程中保持不变。后两个部分初始化为空列表,在LLM生成函数调用和执行程序调用相应的工具之后,每个步骤都会不断更新空列表。 规划器选择工具 基于当前的知识记忆,基于 LLM 的规划器在每一步选择一个工具与知识图谱(KG)进行交互。具体来说,当前知识记忆中的所有部分将根据相应的提示模板进行格式化以组成输入,然后LLM将通过从输入中选择一个工具及其参数来生成一个函数调用。通常,规划器需要调用预定义工具箱中的工具来满足四种类型的任务需求: 链接实体,获取 KG 信息,处理中间结果,返回最终答案并结束推理。 执行器执行调用并更新记忆器 在计划器生成函数调用之后,基于 KG 的执行器将使用程序编译器执行它。它可以缓存或操作中间变量,并从 KG 中提取新的实体或关系。执行后,知识内存会相应更新。首先,将当前函数调用添加到历史推理程序中。其次,如果被调用的工具要从 KG 获取新信息,执行器将把它添加到 KG 信息中,以更新知识记忆器。 自治代理 KG-Agent 框架自动迭代上述工具选择和记忆更新过程,以执行逐步推理,其中知识记忆用于维护从 KG 访问的信息。这样,Agent的多回合决策过程就像沿关系在 KG 上行走。一旦到达目标实体,代理将自动停止迭代过程。整个过程与任务类型和特定 KG 无关。因此,我们的方法是一个通用框架,可以应用于需要对任何KG进行推理的各种复杂任务。
实验结果
我们选择了四个常用的 KGQA 数据集作为域内数据集,分别是基于 Freebase 的 WebQSP、CWQ 和 GrailQA,以及基于 Wikidata 的 KQA Pro。我们选择三个 ODQA 数据集作为域外数据集,分别是WQ、NQ 和 TQ。 表2和表3分别展示了基于 Freebase 和 Wikidata 的领域内数据集的结果。首先,第二块基于 LM 的 seq2seq 生成方法在 WebQSP 和 KQA Pro 上可以获得比第一块基于子图推理方法更好的 F1 得分。这表明由 LM 生成的 SPARQL 查询可以获得更完整的答案集,并且结构化查询在某些复杂操作(例如最大值、计数)上比传统的基于子图的推理方法更具支持性。其次,尽管 LLM 功能强大,直接使用 Davinci-003、ChatGPT 甚至 GPT-4 与在WebQSP、GrailQA 和 KQA Pro 中表现最佳的微调方法相比,仍存在较大的性能差距,这表明单靠 LLM 回答复杂问题仍然存在难度。最后,我们的 KG-Agent 在混合数据上进行指令调优后,在所有数据集上明显优于所有其他竞争基线。通过不同数据集之间的互补增强,我们的方法在 WebQSP、CWQ 和 Grailqa 上分别取得了1.7%、7.5%和2.7%的F1提升。得益于自主推理机制,我们的方法能够在两个知识图谱上进行推理,并在所有数据集上获得一致的改进。
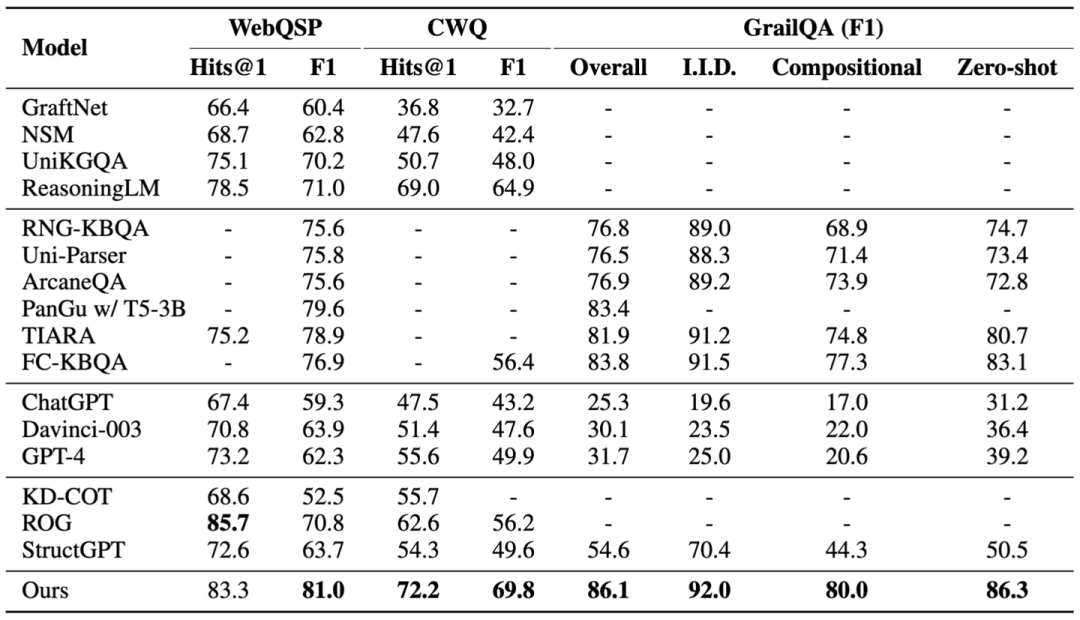
表2 在基于Freebase的数据集上的结果

表3 在基于Wikidata的数据集上的结果 经过指令微调后,我们直接在跨领域数据集上评估了我们的 KG-Agent 的零样本性能。如表4所示,尽管使用完整数据进行了微调,小型预训练语言模型(例如T5和BART)无法有效回答这些事实性问题。由于参数规模较大,Davinci-003 和 ChatGPT 在 NQ 和 TQ 上的表现良好,这些数据集是基于它们可能已经预训练过的维基百科构建的。然而,它们在基于Freebase KG构建的WQ上的表现不佳。相比之下,我们的 KG-Agent 只需学习如何与KG交互,而不需要记住特定的知识。因此,它可以在零样本设置中利用外部KG,并且与微调后的预训练语言模型相比,实现了持续的改进。
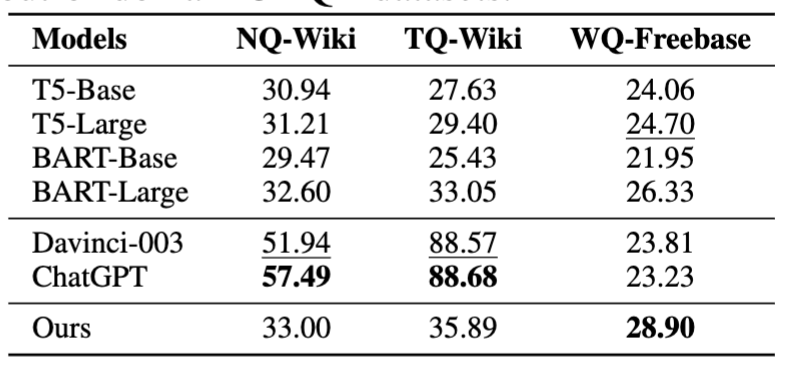
表4 在ODQA数据集上零样本表现
结论
在这项工作中,我们提出了一个自主代理框架来协同大型语言模型(LLM)和知识图谱(KG)以在 KG 上执行复杂推理,即 KG-Agent。在我们的方法中,我们首先为 KG 精心策划了一个工具箱,包含三种类型的工具,以支持在 KG 上推理时的典型操作。然后,我们开发了一个基于工具选择然后记忆更新的自主迭代机制,该机制整合了LLM、多功能工具箱、基于 KG 的执行器和知识记忆,用于在 KG 上进行推理。接下来,我们利用现有的 KGQA 数据集合成了基于代码的指令调优数据集。最后,仅凭10K的调优样本,我们实现了依赖于相对较小的7B LLM(即LLaMA2)的自主代理,其性能大多优于基于全数据调优或更大 LLM 的最先进基线。