- 扩散 Transformer 的自回归蒸馏

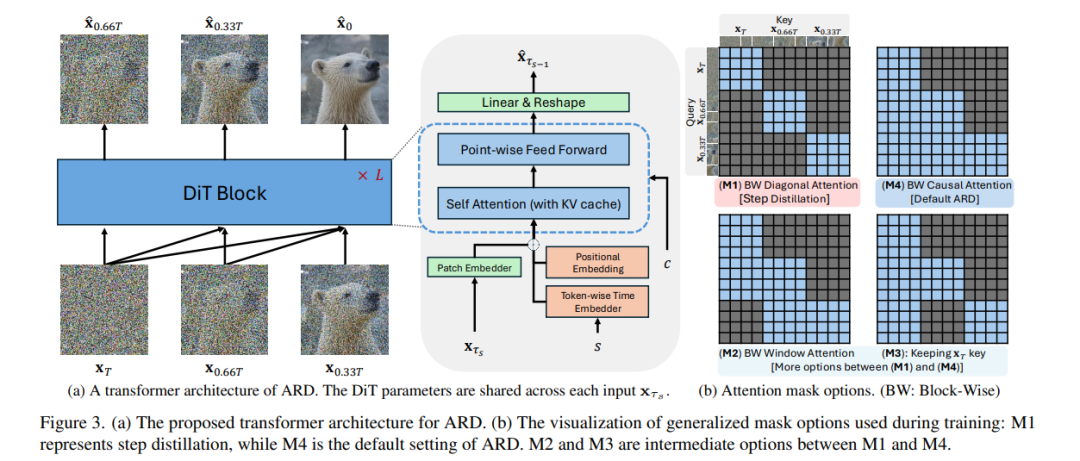
采用 Transformer 架构的扩散模型在生成高保真图像和高分辨率扩展性方面展现了令人瞩目的能力。然而,其合成所需的迭代采样过程资源消耗巨大。为此,一系列研究致力于将概率流常微分方程(ODE)的解蒸馏为仅需少步数的学生模型。然而,现有方法普遍依赖于最近一次的去噪样本作为输入,这使其易受到暴露偏差(exposure bias)的影响。 为了解决这一问题,我们提出了 AutoRegressive Distillation(ARD,自回归蒸馏),这是一种新颖的方法,通过利用 ODE 的历史轨迹来预测未来步骤。ARD 提供了两个主要优势: 1)通过利用预测的历史轨迹来降低暴露偏差,该轨迹对累计误差的敏感性较低; 2)将 ODE 轨迹中的历史信息作为更有效的粗粒度信息来源,从而提升学习效果。 在结构上,ARD 对教师 Transformer 架构进行了改进,添加了按 token 编码的时间嵌入(token-wise time embedding),用于标记来自轨迹历史的每个输入,并在训练中引入了块级因果注意力掩码(block-wise causal attention mask)。此外,将历史输入仅引入 Transformer 的底层层级,还能进一步提升性能与效率。 我们在 ImageNet 的类别条件生成任务以及文本到图像(T2I)合成任务中验证了 ARD 的有效性。实验结果表明:在 ImageNet-256 上,ARD 相比现有基线方法在 FID 退化上降低了 5 倍,而计算开销仅增加了 1.1% FLOPs。此外,ARD 在仅使用 4 步采样的情况下即可在 ImageNet-256 上达到 1.84 的 FID,并在 prompt adherence(文本一致性)得分方面超越了当前公开的 1024p 文本到图像蒸馏模型,同时 FID 与教师模型相比下降极小。 项目页面:https://github.com/alsdudrla10/ARD
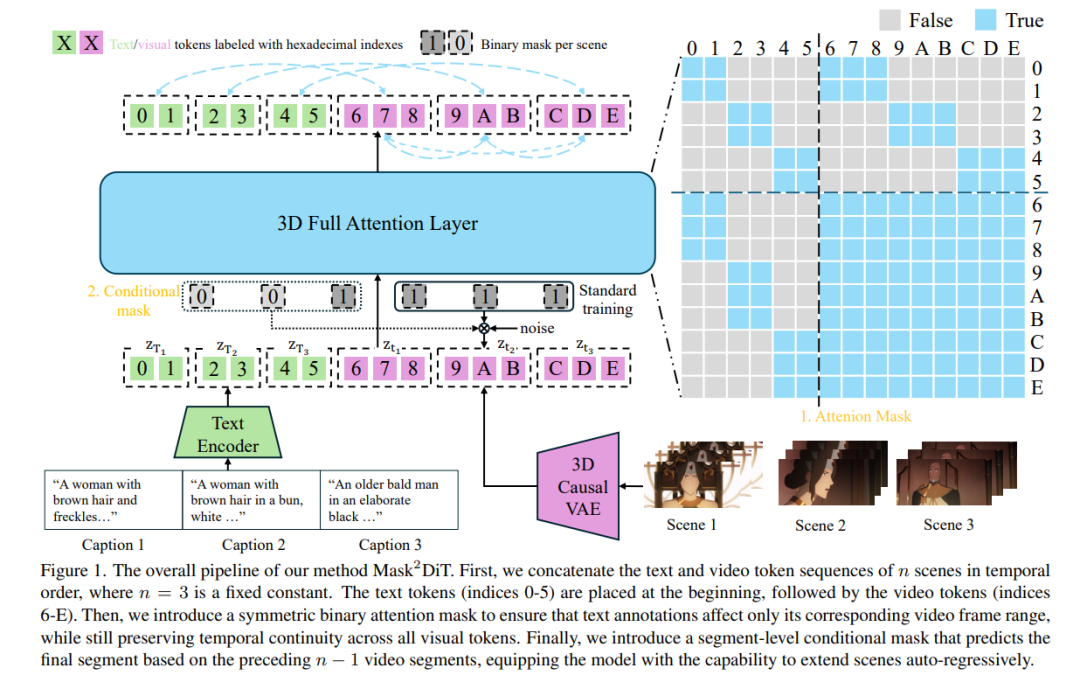
- Mask2DiT:用于多场景长视频生成的双掩码扩散 Transformer

Sora 展示了扩散 Transformer(DiT)架构在单场景视频生成中的巨大潜力。然而,多场景视频生成这一更具挑战性、应用更广泛的任务仍相对较少被深入探索。为弥补这一空白,我们提出了一种新方法 —— Mask2DiT,通过建立视频片段与其对应文本注释之间细粒度的一对一对齐关系,实现更高质量的多场景视频生成。 具体而言,我们在 DiT 架构的每一层注意力机制中引入了对称二值掩码(symmetric binary mask),确保每条文本注释仅作用于其对应的视频片段,同时保持视觉 token 之间的时间连贯性。这种注意力机制使得 DiT 能够实现精确的片段级文本-视觉对齐,从而高效处理具有固定场景数量的视频生成任务。 为了进一步增强 DiT 在生成多个连续场景方面的能力,我们设计了一个片段级条件掩码(segment-level conditional mask)。该掩码机制使得每个新生成的视频片段能够基于前一个片段进行生成,从而实现自回归式的场景扩展。 在定性与定量实验中,Mask2DiT 在保持各片段之间视觉一致性的同时,亦展现出在语义上精准对齐每个片段与其文本描述的优越性能。 项目主页:https://tianhao-qi.github.io/Mask2DiTProject
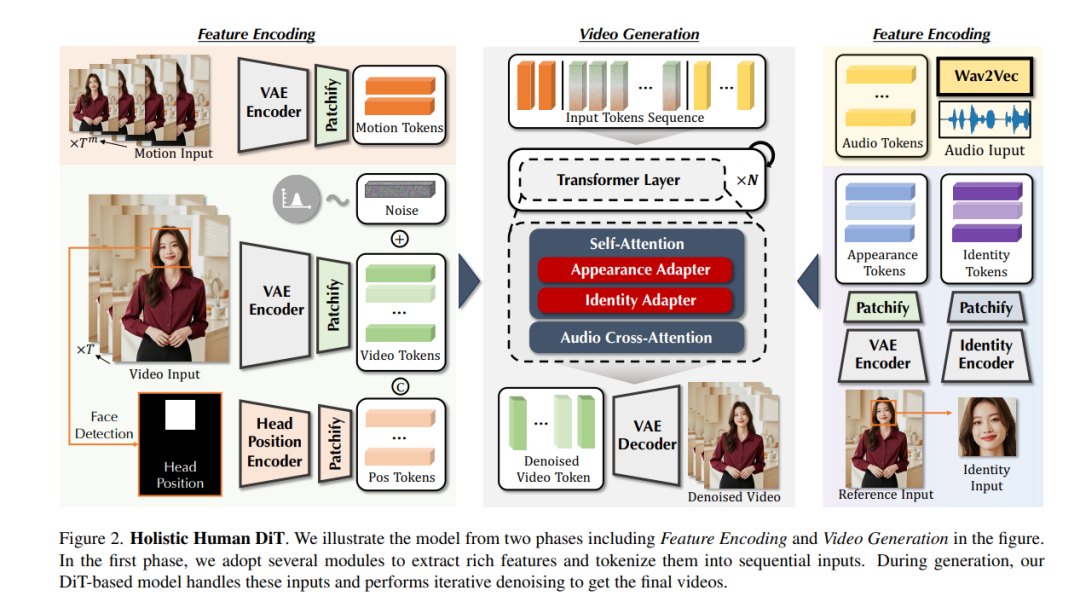
- AudCast:基于级联扩散 Transformer 的音频驱动人类视频生成

尽管音频驱动视频生成在近年来取得了显著进展,现有方法大多聚焦于面部动作的驱动,往往导致头部与身体之间的运动不协调。展望未来,生成具备精准唇动同步与自然随语手势(co-speech gestures)的完整人类视频是一个既有需求又极具挑战性的方向。 在本研究中,我们提出了 AudCast,一个通用的音频驱动人类视频生成框架,采用级联式扩散 Transformer(Diffusion-Transformers, DiTs)范式。该框架能够基于参考图像和输入音频,生成完整的人体视频。主要包括两个关键组件: 1. Holistic Human DiT(全身驱动模块):我们设计了一个音频条件下的全身生成架构,能够直接驱动任意人体的动作,并展现出生动自然的姿态动态; 1. Regional Refinement DiT(局部细节增强模块):针对面部与手部等生成难点,采用区域 3D 拟合作为中介进行特征重构,从而实现局部细节的精致还原,输出最终视频结果。
大量实验表明,AudCast 能够生成具有高保真度、时间一致性的人体视频,同时展现出精细的面部与手部细节,在音频驱动场景中具有显著优势。 项目资源链接:https://guanjz20.github.io/projects/AudCast
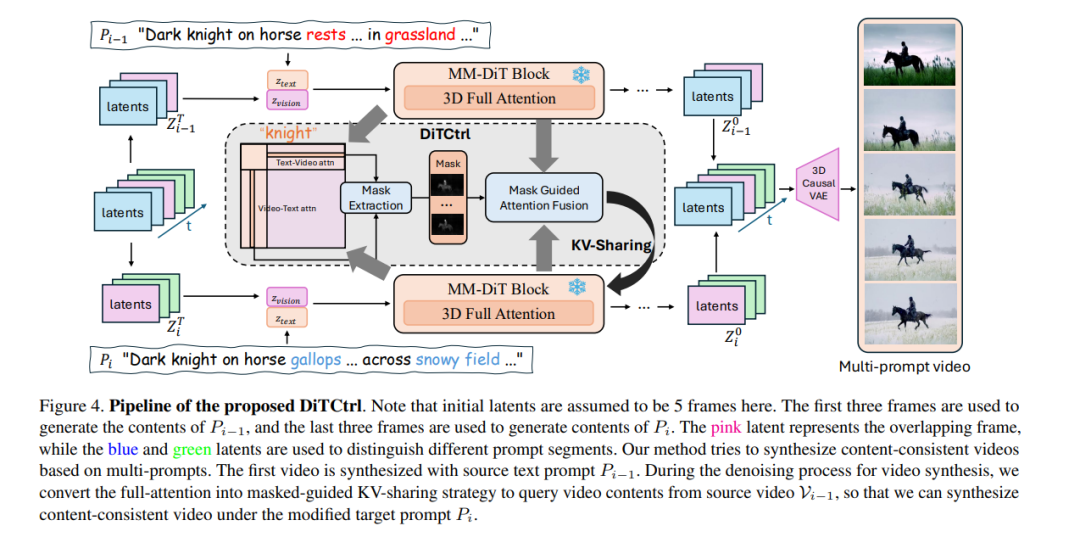
- DiTCtrl:在多模态扩散 Transformer 中探索注意力控制,用于免调优的多提示长视频生成

类似 Sora 的视频生成模型在多模态扩散 Transformer(Multi-Modal Diffusion Transformer, 简称 MM-DiT)架构下取得了显著进展。然而,现有的视频生成方法主要聚焦于单提示(single-prompt)生成,难以应对多序列提示下的连贯场景生成,而这恰恰更贴近现实世界中的动态场景需求。 尽管已有部分前沿工作开始探索多提示视频生成(multi-prompt video generation),但仍面临诸多挑战,包括对训练数据的严格依赖、提示响应能力弱,以及场景过渡不自然等问题。 为了解决上述难题,我们首次在 MM-DiT 架构下提出 DiTCtrl —— 一种无需训练的多提示视频生成方法。我们的核心思想是:将多提示视频生成任务视为一个具有平滑过渡的视频时间编辑问题(temporal video editing)。 为实现该目标,我们首先分析了 MM-DiT 的注意力机制,发现其 3D 全注意力(3D full attention) 的行为方式与扩散模型中类 UNet 架构的交叉/自注意力模块类似。这一特性使得我们可以借助 掩码引导的注意力共享机制,在不同提示之间实现精确的语义控制,从而支持多提示的视频生成。 基于我们精心设计的机制,DiTCtrl 无需额外训练即可生成在多个连续提示下具有平滑过渡与一致物体运动的视频序列。 此外,我们还提出了一个专为多提示视频生成设计的新基准数据集 MPVBench,用于全面评估多提示生成方法的表现。大量实验结果表明,我们的方法在无需训练的前提下,即可达到当前最先进的性能表现。
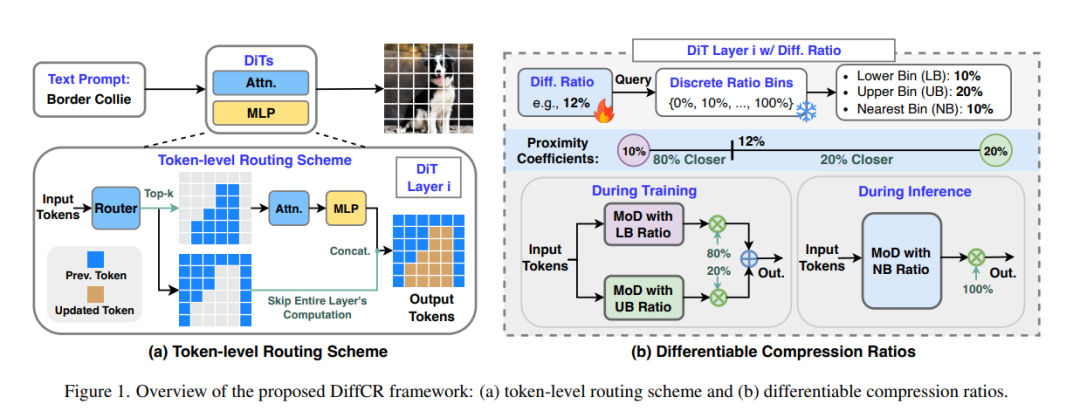
- 用于高效扩散 Transformer 的层级与时间步自适应可微 Token 压缩比策略

扩散 Transformer(Diffusion Transformers,简称 DiTs)已在图像生成任务中达到了最先进(SOTA)的效果,但其高延迟与内存低效问题,严重限制了在资源受限设备上的部署能力。其中一个主要的效率瓶颈在于:现有的 DiTs 在图像所有区域上执行相同强度的计算,然而图像中的各个 token 重要性并不相同,某些局部区域(例如目标物体)通常需要更多的计算资源。 为了解决这一问题,我们提出了 DiffCR,一种具有可微压缩比(differentiable compression ratios)的动态 DiT 推理框架,能够自动学习在不同层级与时间步中针对每个图像 token 动态分配计算资源,从而实现高效的 DiTs 推理。 具体来说,DiffCR 融合了三项关键设计: 1. Token 级路由机制:每一层 DiT 中包含一个路由器模块(router),该模块与模型权重一同微调,用于预测各 token 的重要性分数。对于不重要的 token,可直接跳过整个层的计算过程,从而降低推理成本。 1. 层级可微压缩比机制:不同 DiT 层能够从零初始化中自动学习不同的压缩比。结果显示,对于冗余层,模型会学习出较高的压缩比;而对关键层,则保留更多计算,甚至不做压缩。 1. 时间步可微压缩比机制:每一个去噪的时间步会独立学习其最优压缩比。我们发现模型在噪声较强的早期时间步会使用更高的压缩比,而在图像逐渐清晰的后期则降低压缩比以保留更多细节。
在文本生成图像(text-to-image)与图像修复(inpainting)任务上的大量实验表明,DiffCR 能够在 token、层级和时间步三维度上有效建模动态计算需求,在生成质量与效率之间相较于现有方法取得了更优的平衡。