来自中科院自动化所、字节跳动的研究者提出了一种高性能的指代性分割基准模型,与之前的最佳结果相比,该方法可以获得更好的分割效果。
![]()
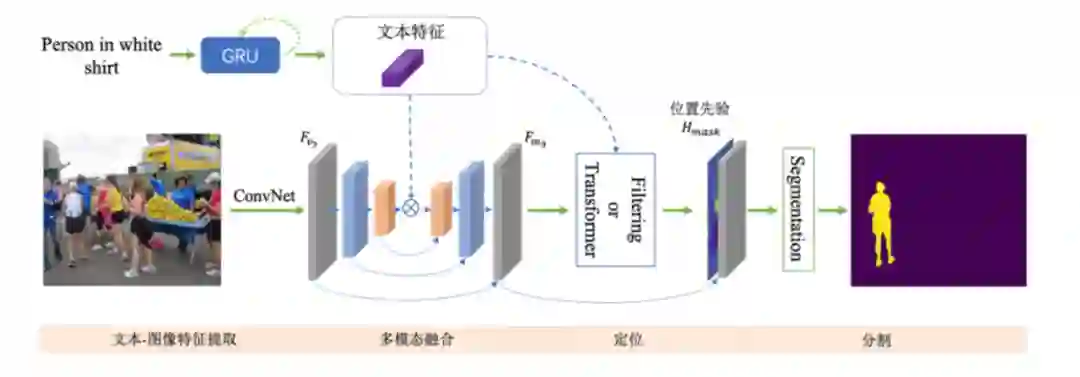
如何通过自然语言定位并分割出场景中的目标物体?比如给定一张图片,语言指示 「分割出穿白色衬衫的人」。这个任务在学术界叫做指代性物体分割(Referring Image Segmentation)。目前指代性分割的工作通常着重于设计一种隐式的递归特征交互机制用于融合视觉 - 语言特征来直接生成最终的分割结果,而没有显式建模被指代物体的位置。
为了强调语言描述的指代作用,来自
中科院自动化所、字节跳动的研究者将该任务解耦为先定位再分割的方案(LTS,Locate then Segment)
,它在直观上也与人类的视觉感知机制相同。比如给定一句语言描述,人们通常首先会注意相应的目标图像区域,然后根据对象的环境信息生成关于对象的精细分割结果。该方法虽然很简单但效果较好。在三个流行的基准数据集上,该方法大幅度优于所有以前的方法。这个框架很有希望作为指代性分割的通用框架。
![]()
论文地址:https://arxiv.org/abs/2103.16284
指代性分割旨在为自然语言表达所描述的图像生成对应的分割结果。除了语义分割面临的问题,图像和语言之间的语义鸿沟也是该任务的一个重要挑战。现有的指代性图像分割方法通常利用卷积神经网络和递归神经网络来提取图像特征和语言特征,然后使用多模态交叉注意和循环 ConvLSTM 用于融合视觉和文本特征来得到一个粗糙的分割。最后进一步将 DenseCRF 用作后处理,来获得最终的精细分割结果。这些方法主要集中在如何融合图像特征和语言特征,它们通常使用复杂的网络架构,此外,这些方法没有明确地定位由语言表达指代的对象,而仅利用耗时的后处理来生成最终的精细分割。
本文从另外的角度看待这个问题:将指代性图像分割任务分解为两个子序列任务:
1. 被指代对象的位置预测。通过位置建模可以显式获取语言所指代的对象;
2.对象分割结果的生成。后续的分割网络则可以根据视觉环境信息来得到准确的轮廓。
![]()
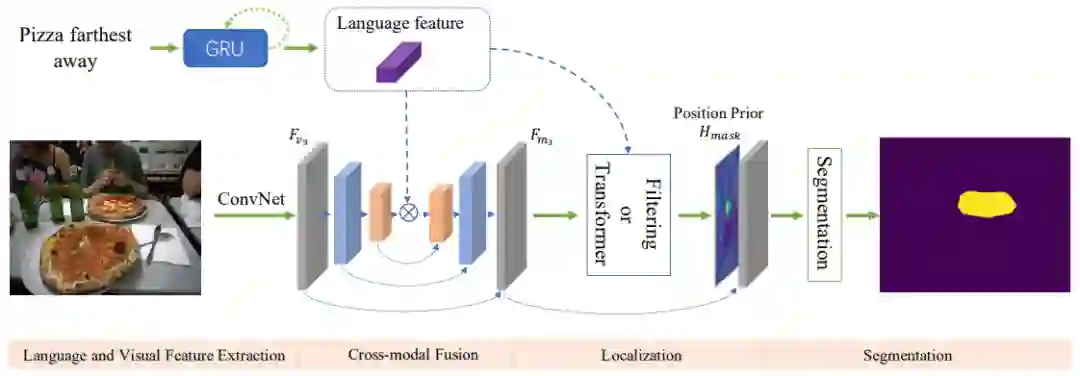
其中定位模块旨在找到语言表达所指代的视觉区域。首先基于语言描述生成卷积核,然后使用该卷积核对提取到的多模态特征进行过滤来得到位置信息,其中被指代对象所在区域的响应得分应该高于无关的视觉区域,这也是一个粗略的分割结果。
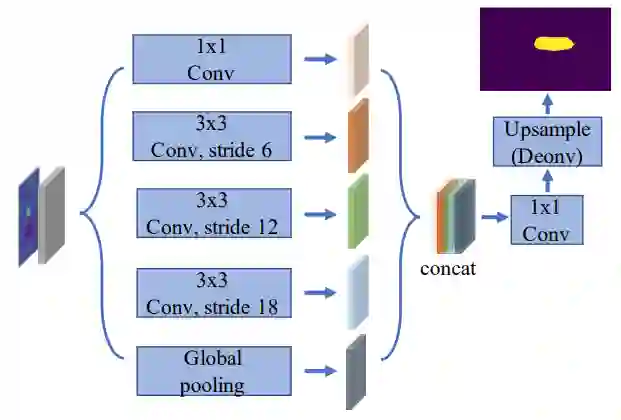
为了得到精细的分割结果,分割模块将原始的多模态特征和位置先验进行拼接,然后利用一个分割网络去细化粗分割结果,它的主要结构是 ASPP,通过使用多个采样率在多个尺度上捕获对象周围的信息。
最后,为了获得更精确的分割结果,本文采用反卷积的方式对特征图进行上采样。
![]()
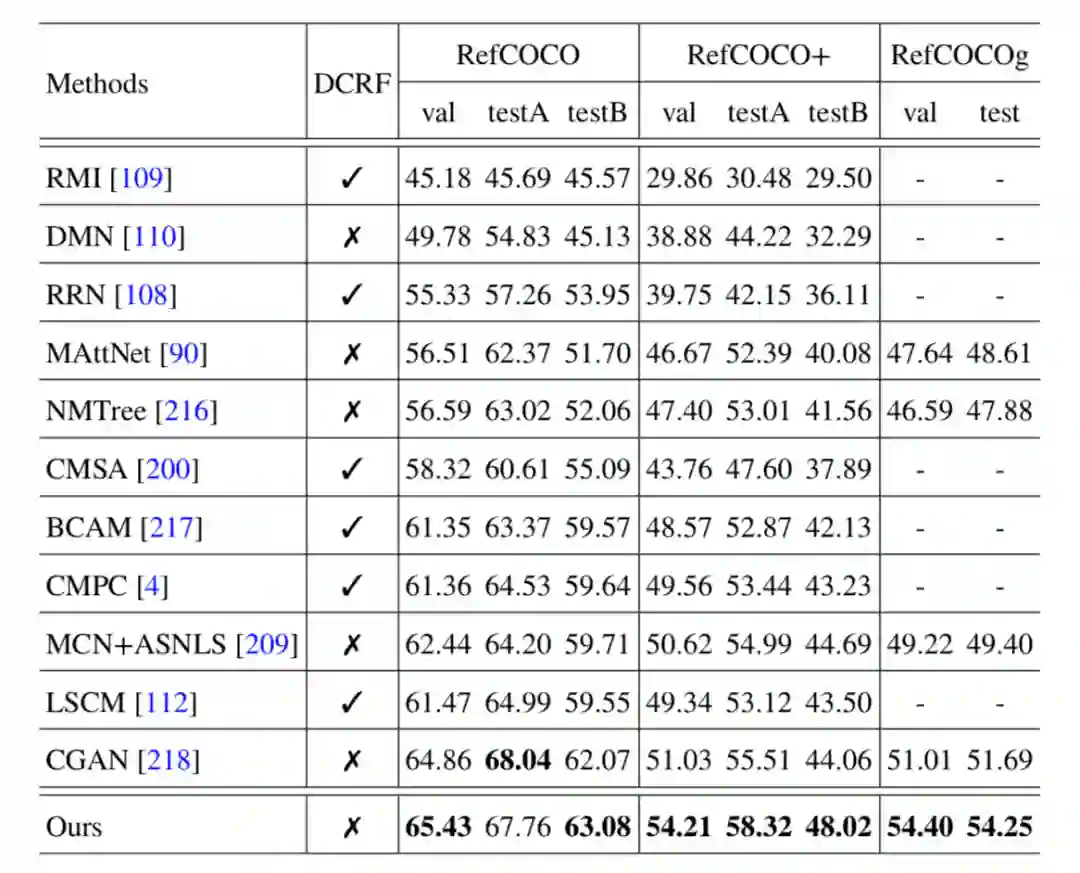
本文提出的方法在三个通用的公开数据集 RefCOCO、RefCOCO + 和 RefCOCOg 上评估了模型的有效性。实验结果如下:
![]()
由结果可以看出,该研究提出的方法比之前性能最好的方法 CGAN 性能更高,尤其在 RefCOCO + 和 RefCOCOg 上可以提高大约 3%IoU。
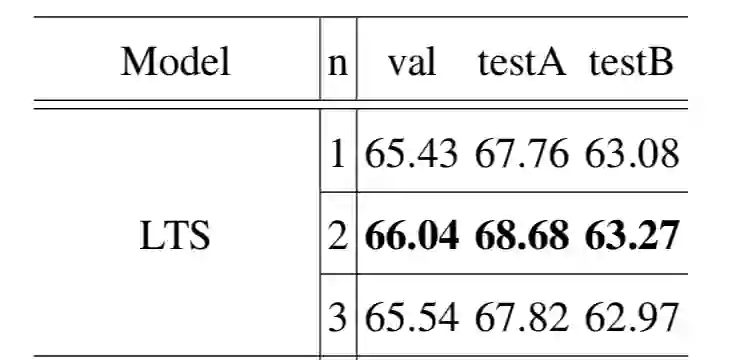
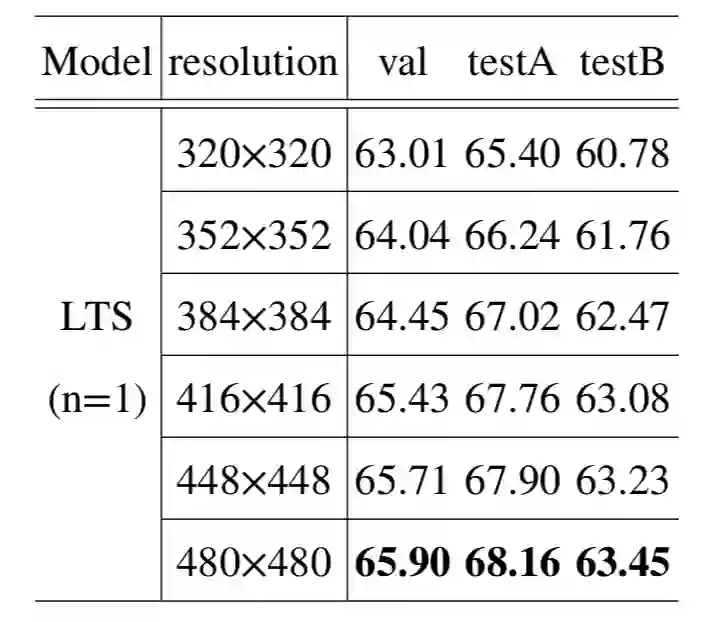
此外,将定位模块中的过滤方式替换为 transformer 方式,使用多次过滤、更大的图像输入都可以进一步提高模型的性能。实验结果如下:
![]()
![]()
![]()
本文针对指代性分割提出了一种简单而有效的方法。该方法将任务分解为两个子序列任务:
被指代对象位置预测和精细对象分割结果生成
。通过对位置进行显式建模,与之前的最佳结果相比,该方法可以获得更好的分割效果。大量的消融研究也证明了方法中每个组成模块都是有效的。
CVPR 2021 线下论文分享会
为更好的服务 AI 社区,促进国内计算机视觉学术交流,机器之心计划于 6 月 12 日组织大型「CVPR 2021 线下论文分享会」。
本次活动将设置
Keynote、 论文分享和 Poster 环节
,邀请顶级专家、论文作者与现场参会观众共同交流。欢迎论文作者、AI 社区从业者们积极报名参与。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com