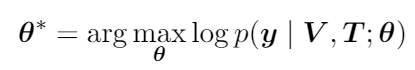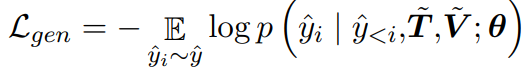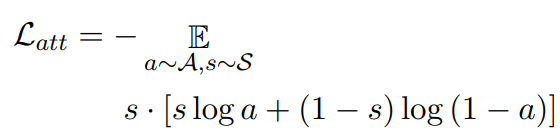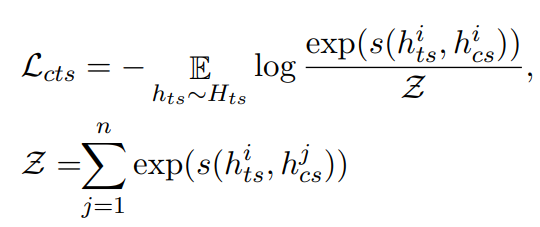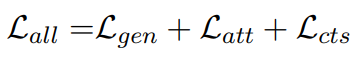(本文阅读时间:11分钟)
编者按:一直以来,图片描述生成任务都是人工智能领域研究人员们关注的热点话题。近期学术界提出的 Localized-Narratives 数据集,为图片描述生成的可控性和可解释性研究提供了新的机会。基于此,微软亚洲研究院的研究员们展开了深入研究,致力于对图像描述生成任务中所涉及的语义概念进行空间和时序关系上的控制,以提高其表现性能。同时,研究员们还提出了一种新模型 LoopCAG,并通过一系列实验证明了其在多个层面的可控性优势。
针对视觉信号和语言信号的对应关系这一研究热点,研究员们从图片描述生成的可控性角度给出了解答,但想要深度理解和研究这一问题还有很长的路要走。希望感兴趣的读者可以阅读论文全文,并发表自己的独特观点,和研究员们一起交流学术感想!
图片描述生成是一项非常经典的人工智能任务,但是随着人们对其关注度的提高,如何控制生成的内容还需要进一步探究。为了生成用户希望且具备事实依据的图片描述,学术界近期提出了一个被称为 Localized-Narratives 的数据集,并且将鼠标轨迹作为一个额外的输入,引入到图片描述生成任务中。
对此,微软亚洲研究院的研究员们进行了深入研究,
发现鼠标轨迹的引入可以增强图片描述生成的可控性和可解释性
,同时研究员们还提出了一种
新模型 LoopCAG,显著提升了图片描述生成的性能
。相关论文“Control Image Captioning Spatially and Temporally”已被 ACL 2021 接收。(论文链接:
https://aclanthology.org/2021.acl-long.157.pdf
)
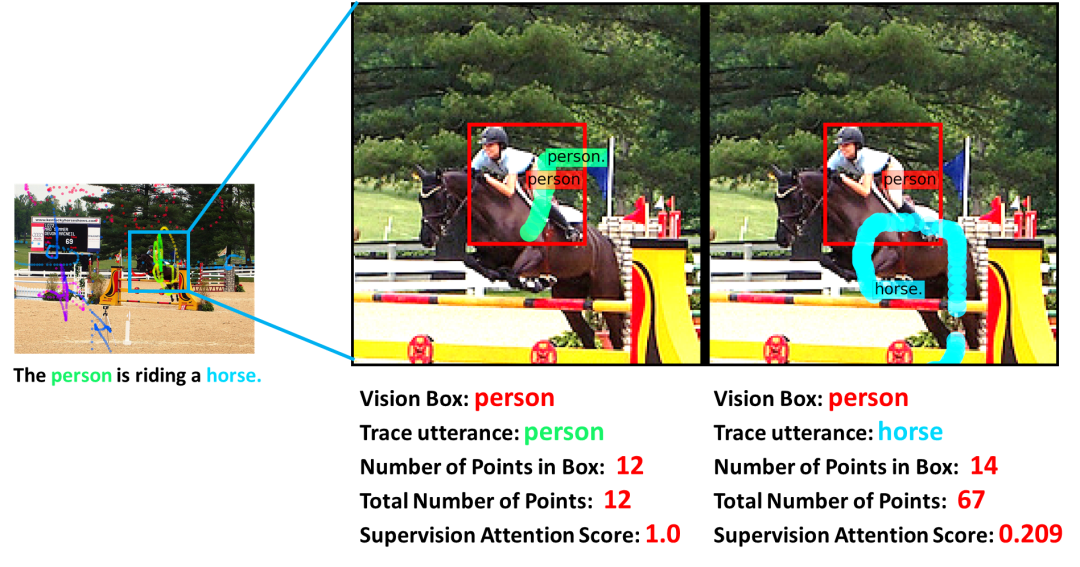
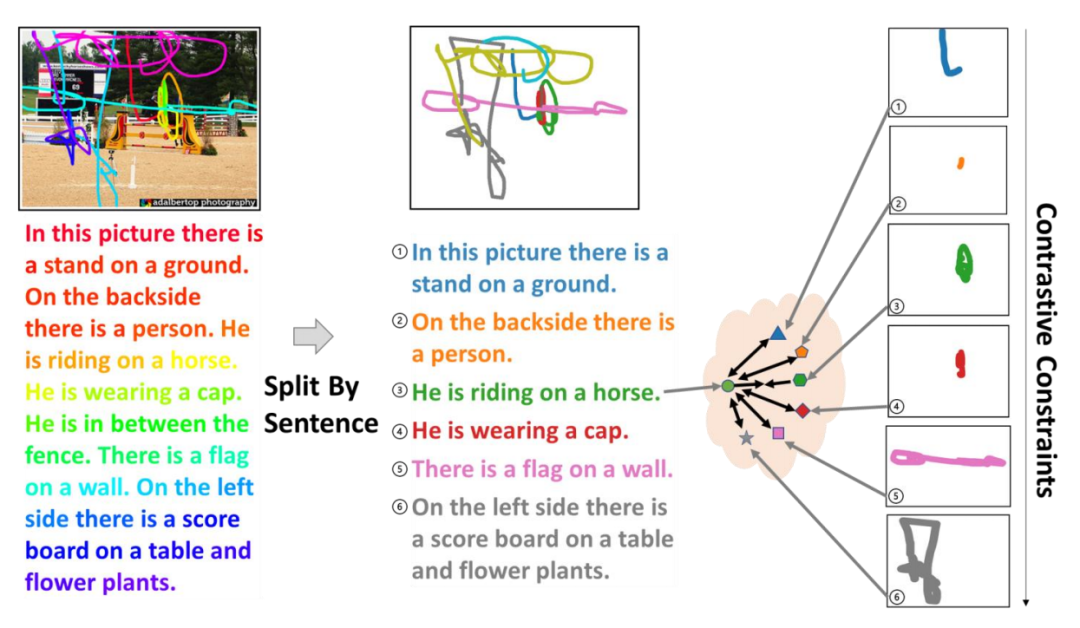
轨迹控制的图片描述生成任务可以定义为:当给定一个图像和代表用户意图的鼠标轨迹时,模型应该生成与轨迹的每个部分相对应的描述。例如,当在图1左侧的图像上画上彩色轨迹时,需要生成如图1右侧的描述。轨迹和标有相同颜色的描述是相互对应的。从图1中可以看出,描述中的一些词,例如 “person”、“horse”、“tree”,可以在空间上直接与图片中的视觉对象一一对应。同时,生成描述的顺序需要与轨迹的顺序保持一致。
虽然,人们可以很容易地做到按轨迹的指示顺序来描述图片中的视觉对象 。但对于人工智能系统来说,如何识别、强调并沿着这些坐标安排视觉语义,是一件非常困难且具有研究意义的事情。
在这项工作中,微软亚洲研究院的研究员们主要致力于对图像描述生成任务中所涉及的语义概念进行控制,其包含两个层面:空间上的对应关系和时序上的排列次序。空间上的对应关系是指,描述中的每一个词都应该在图像的正确区域找到正确的对应;时序上的排列次序是指,描述和轨迹之间的语义顺序应该保持一致。
研究员们首先给出了针对这个问题的形式化表述。对于视觉输入,需要在图像上应用一个预先训练好的视觉目标检测器,得到一个对象级别的视觉特征集 V={v_1,…,v_N} ,其中包括 N 个视觉对象的向量表示。相对应的文字描述则是生成目标,表示为一个字符序列 Y={y_1,…,y_l},其中 y_j 是第 j 个字符,l 是字符序列的长度。
原始轨迹输入是一个带有时间戳的轨迹点序列,将轨迹点序列按相同的时间窗口 𝜏 统一分割,然后再将每个轨迹段转换为最小包围框。每个包围框都可以用一个 5D 向量来表示,其中包含了归一化后的包围框左上坐标,右下坐标和面积占比。同时将这个向量序列表示记为 T={t_1,…,t_M},其中 t_i∈R^5。
因此,当给定神经网络模型的参数 𝜃 时,轨迹控制的图像文本描述任务则可以被表述为以下最大似然形式:
![]()
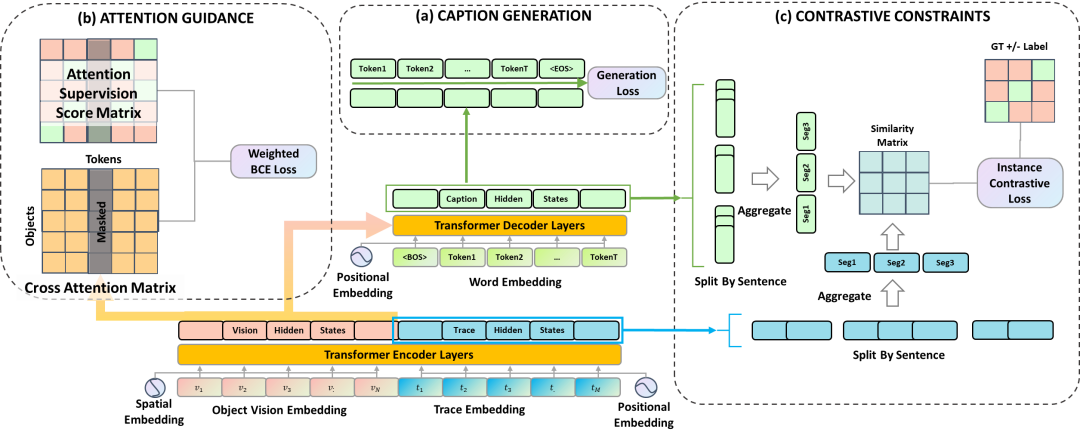
研究员们提出的方法 LoopCAG 可以总结为三部分:用于生成图片描述且以 Transformer 为主干网络的编码器-解码器;用于视觉对象空间定位的注意力引导(Attention Guidance)组件;用于句子级时序对齐的对比性约束(Contrastive Constraints)组件。整体的 LoopCAG 模型结构,如图2所示。
在编码器-解码器部分,前述的视觉特征 V 和轨迹特征 T 被分别编码,并叠加位置信息后得到 V ̃和 T ̃,然后串联在一起作为一个统一的序列输入编码器。
解码器通过交叉注意力(Cross Attention)模块与编码器最后一层的隐藏状态相连,将视觉和轨迹信息结合起来作为生成的前置条件。解码器的优化目标是将以下目标函数最小化:
其中,y ̂_i 是叠加了位置编码和掩码的描述字符向量表示。
2. 注意力引导(Attention Guidance)组件
为了让生成描述中的词语,在空间上明确对应到图片中的视觉物体,可以将轨迹作为一个中间桥梁,来对齐语义描述词语和视觉物体。具体而言,研究员们构建了一个监督矩阵来引导词语和视觉对象之间的注意力。图3是一个监督矩阵分数计算的例子,与语词 “person” 相对应的12个轨迹点都位于视觉对象 “person” 的边界框内,所以伪监督得分是12/12=1;而与词语 “horse” 相对应的轨迹点只有14个在边界框中(总共67个),所以得分是14/67=0.209。
当注意力监督矩阵和模型的交叉注意力矩阵尽可能接近时,词语则可以准确的对应到图片的空间视觉物体上。其损失函数如下:
其中,S 是注意力监督矩阵,A 是模型的交叉注意力矩阵。
3. 对比性约束(Contrastive Constraints)组件
研究员们首先使用了“逐句拆分”来建立描述和轨迹之间的句子级对齐,并聚合它们对应的向量表征,然后再使用对比损失函数来约束生成过程的时间顺序,对比损失的形式是 NCE 函数,用来 学习区分轨迹-描述对之中的正例和负例。在 N 条轨迹和 N 个描述组成的 N*N 个轨迹描述对中,正 例是指在顺序上自然对应的描述句和轨迹段,而其余的轨迹-描述对 组合均为负例。图4展示了这个约束的构建过程:
其中,s(.,.) 是余弦距离函数,h_ts^i 代表第 i 段轨迹的隐向量,h_cs^j 代表第 j 个句子的隐向量。通过将这个损失函数最小化,迫使模型学习句子级时序特点的表征,来生成更精确的文本描述。最后,通过将所有损失的总和最小化来联合优化模型。
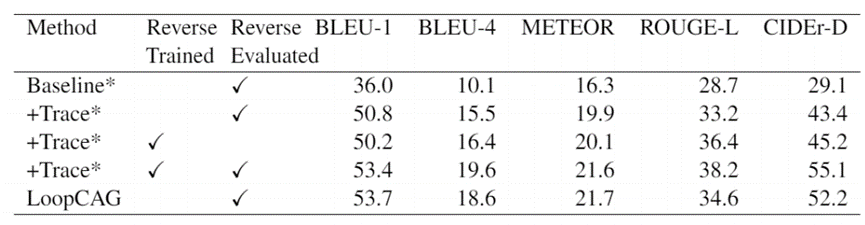
研究员们在 Localized-Narratives COCO 这个数据集上进行了训练和测试,其中训练集包含134,272个样本,测试集包含8573个样本。在测试集上的结果如表1所示,LoopCAG 方法在所有的自动评测指标上都达到了先进水平,在 BLEU-4 和 CIDEr-D 上分别比以前的模型高出2.4和7.5。这表明上述提出的注意力引导方法有助于该模型在空间上建立更好的视觉概念对应关系,进而生成更精确的描述。同时从表中可以看出,ROUGE-L 的得分提升了2.0。由于 ROUGE-L 主要采用了对顺序敏感的最长共同子序列计分方式,这表明对比性约束可以帮助模型更好地将生成句子的顺序与用户的意图对应起来。
为证明 LoopCAG 在描述时序顺序上的优越可控性,研究员们进一步设计了相关实验。首先,将标注的图片描述输入按句号分割,并将分割后句子的顺序颠倒过来(换言之,图片描述的第一句和最后一句将交换顺序,同理,其他句子也依次进行调换 )。然后对于轨迹,也进行同步的分割倒序操作。而后,研究员们将模型在这样的倒序数据集上进行了评估,其性能比较请见表2。在对比性约束机制的帮助下,LoopCAG 模型对轨迹输入的倒序更为鲁棒,其性能甚至可以与在倒序数据上训练得到的模型相比较。相比之下,基线模型在输入的轨迹顺序被颠倒时,几乎所有的指标都有大幅下降。
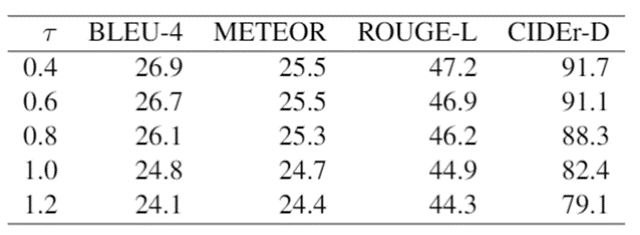
研究员们还对时序频率的可控性同样进行了分析,以说明粗粒度或细粒度的轨迹点是否会影响生成性能。如表3所示,研究员们将时间频率 τ 从0.4逐渐调整为1.2。可以看到,τ 越大,性能越差。这个实验模拟了用户在实际应用场景中的轨迹绘制速度,更大的 τ 相当于更快的绘制速度。换言之,如果用户以更快的速度绘制轨迹,那么模型会生成更为简短的描述,而轨迹的停留时间越长,描述就会越详细。
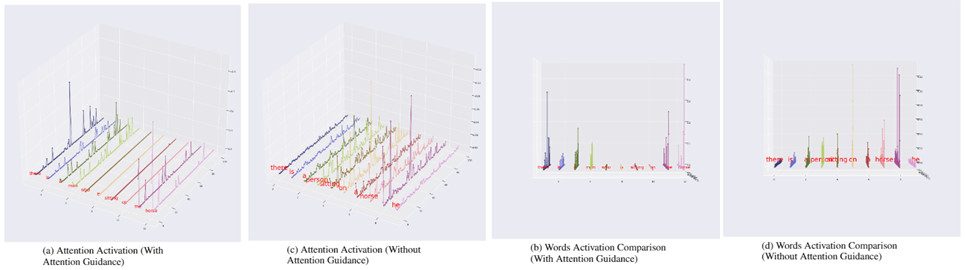
此外,将模型的交叉注意力矩阵可视化,可以观察到,使用了注意力引导机制的模型与基线模型存在统计意义上的显著差异。生成的每个词语对输入视觉物体的注意力选择性更强,这让 LoopCAG 模型具备了更为直观的解释性。这个独特的性质是否与模型性能的提升有关,值得在今后的工作中进一步探讨。
不同方法的文本描述结果如图6所示。可以看出,Baseline Captioning 是以随机顺序描述图像的,而 +Trace Captioning 和 LoopCAG Captioning 描述的图像几乎与人们标注的描述顺序相同。此外,Baseline Captioning 和 +Trace Captioning 还包括一些用红色标出的错误描述。相比之下,LoopCAG Captioning 的描述看来都是合理的。这是注意力引导可以带来卓越视觉信息对应关系的有力证据。
研究员们在本文中探讨了如何充分利用轨迹信息,来增强图片文本描述生成的可控制性。通过引入空间关系的注意力引导,以及时序关系的对比性约束,该论文提出的模型 LoopCAG 相较于基线模型的性能有了明显的提升。此外,研究员们还进行了一系列的可控性实验,证明了新方法在多个层面的可控性优势。
如何有效地建立视觉信号和语言信号的对应关系,是跨模态研究中一个非常重要的问题。本文的工作从图片描述生成的可控性角度对该问题进行了回答,希望可以给更多的研究工作带来灵感,完善人们对视觉语义关系的认识。
8月4日(下周三),我们将邀请论文一作——微软亚洲研究院自然语言计算组实习生闫坤在 ACL 2021 分享专场中,为大家深度解读论文,届时欢迎大家扫码观看。
你也许还想看:
![]()
![]()