

如何从人工智能体中引出我们想要的行为?**指导智能系统行为的一种方法是通过奖励设计。通过指定要优化的奖励函数,我们可以使用强化学习(RL)使智能体能够从自己的经验和互动中学习。**因此,RL在能够手动指定与预期行为良好对齐的奖励函数的场景中取得了巨大成功(例如,使用分数作为游戏的奖励)。然而,随着我们发展必须在丰富多样的现实世界中学习更复杂行为的智能系统,奖励设计变得日益困难——并且至关重要。为了应对这一挑战,我们认为改善奖励信号将需要结合人类输入的新方法。
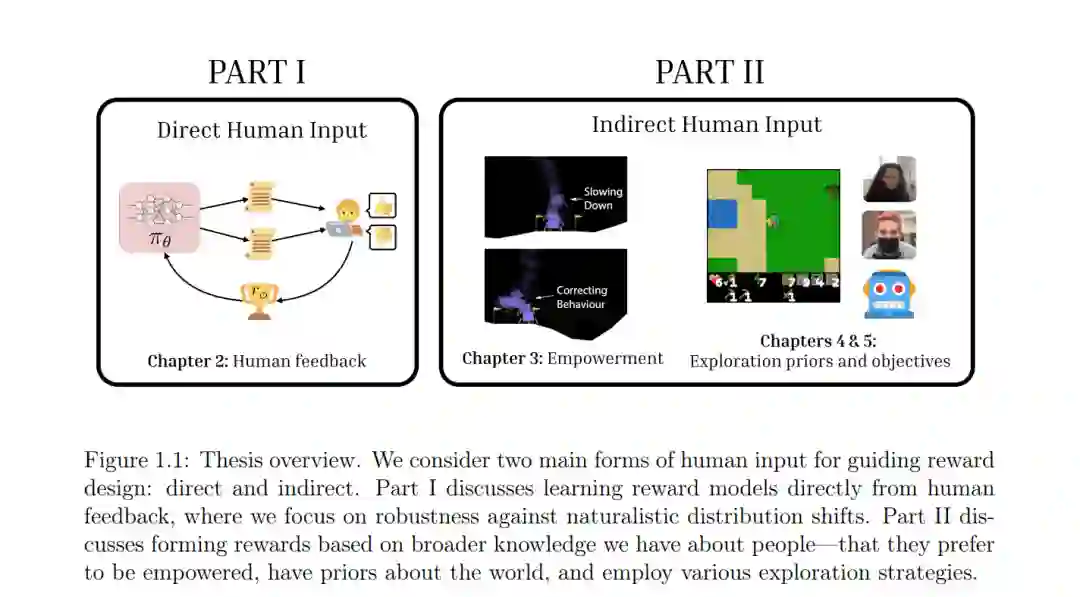
本论文包含两个主要部分:直接使用人类输入或间接使用我们对人类的一般知识进行奖励设计。在第一部分,我们提出了一个框架,用于从直接人类反馈中构建稳健的奖励模型。我们提出了一种适用于大规模预训练的视觉-语言模型的奖励建模公式,这导致在视觉和语言分布偏移下更具泛化性的多模态奖励函数。在第二部分,我们使用关于人类的广泛知识作为奖励设计的新型输入形式。在人类协助设置中,我们提议使用人类赋能作为任务不可知的奖励输入。这使我们能够训练辅助智能体,避开现有基于目标推断方法的限制,同时也旨在保护人类自主权。最后,我们研究了在人工智能体中激发探索性行为的情况。与之前为了鼓励探索而无差别地优化多样性的工作不同,我们提议利用人类先验知识和普遍的世界知识来设计内在奖励函数,从而导致更类似于人类的探索。为了更好地理解指导人类行为的内在目标如何能够为智能体设计提供信息,我们还比较了人类和智能体在一个开放式探索设置中的行为与通常作为内在奖励提出的信息论目标的一致性。我们以对奖励设计挑战和未来工作方向的一些反思结束。
从机器中引出所需行为是人工智能(AI)研究中的一个根本挑战。尽管我们已经看到深度神经模型在生成文本(Brown et al., 2020a; Touvron et al., 2023)和图像(Ho et al., 2020; Rombach et al., 2022)到控制机器人代理(Agarwal et al., 2023; Brohan et al., 2023)方面的能力日益显著,但确保这些系统一致地生成与人类目标(即价值对齐(Shapiro & Shachter, 2002; Hadfield-Menell et al., 2016)或智能体对齐(Leike et al., 2018))一致的行为仍然是一个未解决的问题。同时,随着这些系统在现实世界中的部署,实施和评估对齐变得越来越重要。 解决这个问题的一种方法是通过模仿学习来训练智能体。也就是说,如果我们人类——从与智能系统互动的日常用户到设计这些系统的从业者——知道理想行为可能是什么样的,一个自然的解决方案就是创建这些行为的演示,并通过最大似然目标训练模型来产生同样的行为。这种模仿学习的方法在可以收集大量高质量演示数据的情况下可能非常有效(例如,在训练大型语言模型(Brown et al., 2020a)或视觉-语言模型(Alayrac et al., 2022)的情况下利用现有的互联网规模的文本和图像数据,或让人类生成机器人任务演示(Sammut et al., 1992; Jang et al., 2022))。然而,更多时候,获取高质量且覆盖理想行为分布的演示的过程是艰难且昂贵的。此外,仅从演示中学习可能很困难——这个过程可能导致脆弱的策略,如果智能体偏离给定演示太远就会失败(Camacho & Michie, 1995; Ross & Bagnell, 2010; Wang et al., 2017)。 强化学习(RL)(Sutton & Barto, 2018)提供了一个训练智能代理的替代框架。与模仿“理想行为”的演示不同,RL使智能体能够通过优化实现高奖励的行为来从自己的经验中学习。当给定的奖励函数与理想行为良好对齐时,这个过程强化了表现出所述理想行为的学习策略。因此,在这个框架中,我们将指定理想行为的挑战推迟到奖励设计上。尽管我们已经看到在能够手动指定与理想行为对齐的奖励函数的情况下深度RL技术取得了巨大成功(例如,在游戏中使用分数(Samuel, 2000; Mnih et al., 2013)),但随着我们试图训练现实世界中复杂行为的策略,奖励设计逐渐变得更具挑战性。奖励设计的重要性和难度的同时增加在奖励工程原理中得到了体现(Dewey, 2014)。实际上,即使在奖励设计看似简单的情况下,轻微的误设定或漏洞也可能通过奖励黑客或游戏化导致不良行为(Amodei et al., 2016; Leike et al., 2017)。随着我们为越来越复杂的任务设置开发更通用的代理,我们如何在奖励设计过程中加强人类监督? 在这篇论文中,我们认为,为越来越通用和能力强大的代理进行奖励设计将需要结合人类输入的新方法。我们注意到,使用人类输入指导奖励设计本身并不是新颖的——以前的工作已经广泛研究了使用人类输入指导智能体目标的一系列方法。例如,逆强化学习从人类演示中提取奖励函数(Russell, 1998; Ng et al., 2000; Ziebart et al., 2008),主动学习或教学可以用来通知奖励估计(Lopes et al., 2009; Cakmak & Lopes, 2012; Hadfield-Menell et al., 2016; Sadigh et al., 2017b),或者可以使用深度神经网络从人类反馈中建模奖励(Leike et al., 2018)。在这里,反馈可以从对生成行为的偏好(Christiano et al., 2017; Lee et al., 2021, 2023)到直接奖励草图(Cabi et al., 2020)不等。Jeon et al. (2020) 提出了奖励合理隐含选择,这是一种统一形式,用于由人类提供的奖励学习的不同形式的信息。Shah et al. (2020) 通过展示奖励学习问题可以重新构想为协助的特殊情况,进一步统一了奖励学习和协助的范式。
这篇论文的目标是通过使用直接或间接形式的人类输入,以两种主要方式推动奖励设计的前沿:在前者中,我们专注于在从直接人类反馈中学习奖励模型的环境中构建稳健性并提高人类反馈效率。在后者中,我们提出了使用我们对人类的一般知识设计更复杂行为的奖励的新方法——即人类协助和探索。
具体来说,第2章首先介绍了从不同形式的聚合人类反馈中学习奖励模型的一般设置。在这个领域,我们展示了我们的工作,即通过重新构思奖励建模问题,使其适应于大规模、预训练的视觉-语言模型,从而为高维输入开发更具泛化性的奖励模型。在这里,我们展示了对于语言和视觉分布变化的增强鲁棒性。这使我们能够将多模态奖励模型扩展到丰富的、真实世界的设置中,在那里可以有许多不同的方式来完成相同的基础任务或目标。接下来,我们询问:我们能否基于我们对人类的一般知识设计奖励?
第3章介绍了我们在辅助代理的奖励设计方面的工作。辅助提出了独特的挑战,其中同一任务的奖励函数可以根据每个人的独特偏好而变化,并且当代理错误地推断出个人目标时极易出现失败模式。我们如何设计奖励,以平衡辅助与保持个体人类自主权和偏好?我们提出重新构思辅助的目标,明确地增加人类控制,通过使用人类赋能作为奖励输入,这显著提高了在辅助下的客观人类性能,以及对助手有用性的主观评价。第4章和第5章探讨了更具挑战性的领域:为激发探索行为而设计的奖励。
虽然先前的工作提出了用于RL代理探索的内在奖励函数,但这些内在奖励通常旨在无差别地最大化多样性。因此,它们无法很好地适应真实世界探索的复杂性,其中可以有无限多样和有趣的状态。另一方面,人类能够以一种由丰富的先验知识以及一些内在目标指导的方式探索新环境。第4章提出了用丰富的人类先验知识指导探索,这些知识被提炼到大型语言模型中。这使我们能够通过利用对有意义行为的先验知识进行开放式环境的探索,这些行为是常识性的并且对上下文敏感。第5章介绍了我们对比人类和代理在开放式环境中探索行为的工作。最后,在第6章中,我们反思所学到的经验教训,并讨论令人兴奋的未来方向。
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2023/EECS-2023-231.html


作者介绍:

加州大学伯克利分校的四年级博士研究生,由Pieter Abbeel教授在伯克利人工智能研究(BAIR)实验室指导。我在英属哥伦比亚大学获得工程物理学士学位,并辅修荣誉数学,我的指导教授是Machiel Van der Loos和Elizabeth Croft,他们是合作先进机器人与智能系统(CARIS)实验室的成员。 此前,我还曾是FAIR(Meta)的访问研究员,并在DeepMind和X公司,即“月球工厂”实习过。 我主要对帮助基于强化学习的代理从人类那里学习感兴趣——无论是理解人类偏好、通过交互学习,还是获取世界先验知识。例如,我以前的一些工作包括从人类数据中训练多模态奖励模型、学习协助和赋能个人,以及利用常识性的人类先验进行开放式探索。