
首篇时序预训练综述!

时序挖掘(Time-Series Mining,TSM)是一个重要的研究领域,因为它在实际应用中显示出了巨大的潜力。依赖大量标注数据的深度学习模型已经成功地被用于TSM。然而,由于数据标注成本的原因,构建一个大规模、标注良好的数据集变得困难。近期,预训练模型(Pre-Trained Models)在时序领域逐渐受到关注,这归功于它们在计算机视觉和自然语言处理领域的卓越性能。在这个综述中,我们对时序预训练模型(Time-Series Pre-Trained Models,TS-PTMs)进行了全面的调研,旨在指导理解、应用和研究TS-PTMs。具体来说,我们首先简要介绍了在TSM中应用的典型深度学习模型。然后,我们根据预训练技术概述了TS-PTMs。我们探讨的主要类别包括有监督的、无监督的和自监督的TS-PTMs。此外,我们进行了大量实验,以分析转移学习策略、基于Transformer的模型和代表性TS-PTMs的优点和缺点。最后,我们指出了TS-PTMs的一些潜在未来工作方向。源代码可在https://github.com/qianlima-lab/time-series-ptms 获取。
1. 引言
作为数据挖掘领域的一个重要研究方向,时序挖掘(Time-Series Mining,TSM)在真实世界的应用中得到了广泛的利用,例如金融[1]、语音分析[2]、动作识别[3]、[4]和交通流量预测[5]、[6]。TSM的基本问题在于如何表征时序数据[7]、[8]。然后,可以基于给定的表征执行各种挖掘任务。传统的时序表征(例如,shapelets[9])由于过度依赖领域或专家知识,因此耗时较长。因此,自动学习适当的时序表征仍然具有挑战性。近年来,深度学习模型[10]、[11]、[12]、[13]、[14]在各种TSM任务中取得了巨大的成功。与传统的机器学习方法不同,深度学习模型不需要耗时的特征工程。相反,它们通过数据驱动的方式自动学习时序表征。然而,深度学习模型的成功依赖于大量标签数据的可用性。在许多真实世界的情况下,由于数据获取和注释成本,构建一个大的良好标注的数据集可能会很困难。
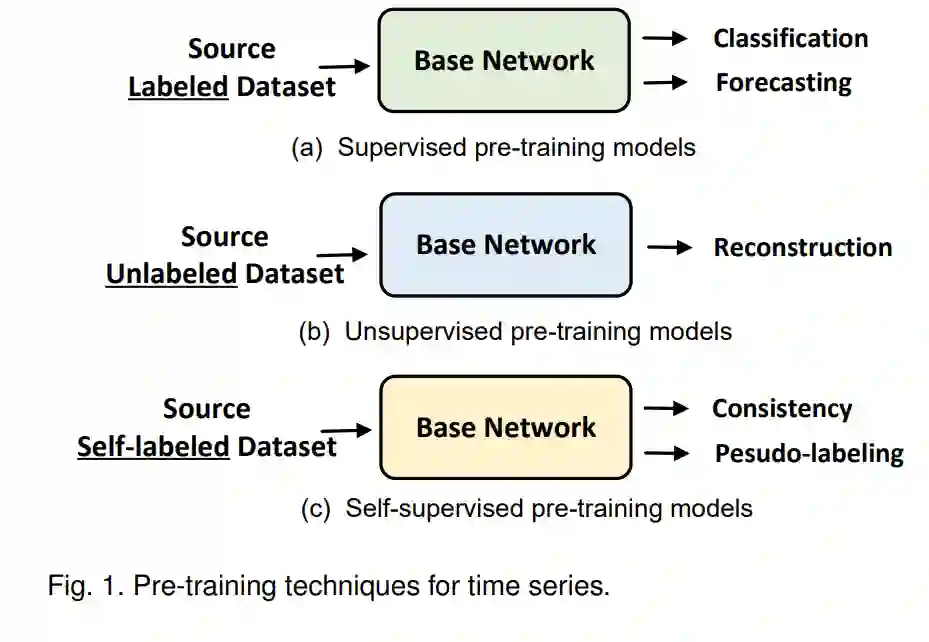
为了减轻深度学习模型对大数据集的依赖,基于数据增强[15]、[16]和半监督学习[17]的方法常常被使用。数据增强可以有效地增强训练数据的规模和质量,并且已经在许多计算机视觉任务中被用作一个重要的组成部分[18]。然而,与图像数据增强不同,时序数据增强还需要考虑时间序列中的属性,如时间依赖性和多尺度依赖性。此外,时序数据增强技术的设计通常依赖于专家知识。另一方面,半监督方法使用大量未标记数据来提高模型性能。然而,在许多情况下,甚至未标记的时序样本也很难收集(例如,医疗保健中的心电图时序数据[19]、[20])。缓解训练数据不足问题的另一个有效解决方案是转移学习[21]、[22],它放宽了训练和测试数据必须独立且具有相同分布的假设。转移学习通常有两个阶段:预训练和微调。在预训练阶段,模型在一些包含大量数据、与目标领域有关但独立的源领域上进行预训练。在微调阶段,预训练模型(PTM)在目标领域的通常有限的数据上进行微调。
最近,特别是基于Transformer的PTMs,在各种计算机视觉(CV)[23]、[24]和自然语言处理(NLP)[25]应用中取得了显著的性能。在这些研究的启发下,近期的研究开始考虑为时序数据设计时序预训练模型(TS-PTMs)。首先,通过监督学习[26]、[27]、无监督学习[28]、[29]或自监督学习[30]、[31]、[32]来预训练一个时序模型,以获得适当的表示。然后,在目标领域上对TS-PTM进行微调,以改善下游的时序挖掘任务(例如时序分类和异常检测)的性能。有监督的TS-PTMs [26]、[33]通常通过分类或预测任务进行预训练。然而,由于很难获得大规模标注的时序数据集用于预训练,这常常限制了有监督TS-PTMs的性能。此外,无监督TS-PTMs利用未标记数据进行预训练,进一步解决了标注数据不足的限制。例如,基于重构的TS-PTMs [28]利用自编码器和重构损失来预训练时序模型。最近,基于对比学习的自监督PTMs [34]、[35]在CV领域展现了巨大的潜力。因此,一些学者[29]、[36]已经开始探索基于一致性任务和伪标签技术来挖掘时序数据的内在属性的设计。尽管如此,TS-PTMs的研究仍然是一个挑战。
我们基于所使用的预训练技术提供了一个分类法和全面的现有TS-PTMs综述。
• 我们进行了大量实验,分析了TS-PTMs的优缺点。对于时序分类,我们发现基于转移学习的TS-PTMs在UCR时序数据集(包含许多小数据集)上表现不佳,但在其他公开可用的大型时序数据集上表现出色。对于时序预测和异常检测,我们发现设计合适的基于Transformer的预训练技术应该是未来TS-PTMs研究的重点。 • 我们分析了现有TS-PTMs的局限性,并针对数据集、Transformer、内在属性、对抗攻击和噪声标签提出了潜在的未来方向。本文的其余部分组织如下。第2节介绍了TS-PTM的背景。然后在第3节中对TS-PTMs进行了全面的审查。第4节介绍了各种TS-PTMs的实验。第5节提出了一些未来的方向。最后,在第6节中总结了我们的发现。
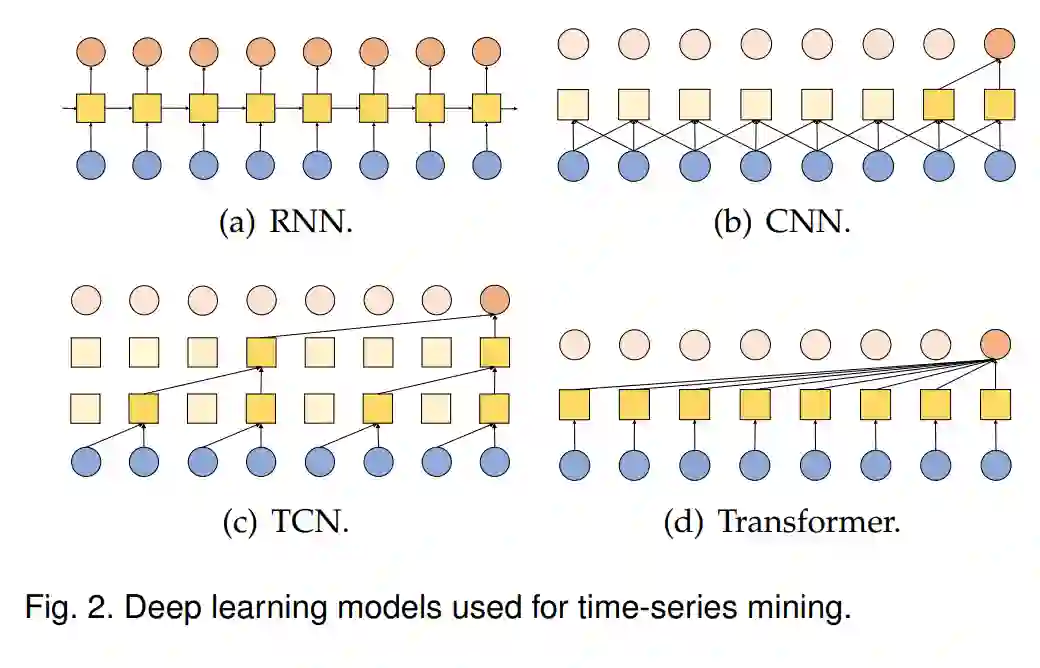
2. TS-PTMs的概述
在本节中,我们提出了一个新的TS-PTMs分类法,根据预训练技术对现有的TS-PTMs进行系统分类。TS-PTMs的分类法如图3所示,请参考附录A.1中的文献概述了TS-PTMs。
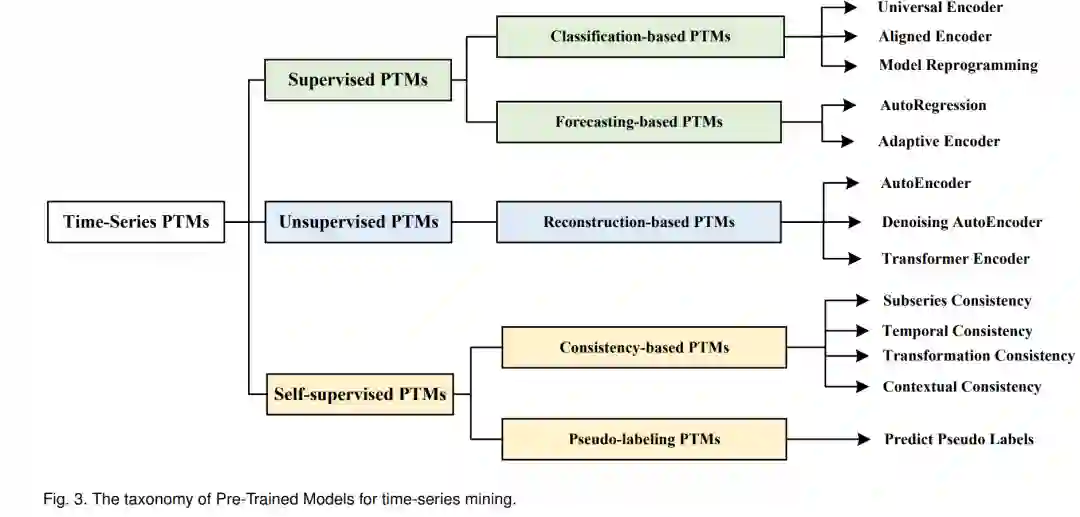
2.1 有监督的PTMs
早期的TS-PTMs受到CV领域转移学习应用的启发。许多基于视觉的PTMs是在大规模标注的数据集(如ImageNet [62])上进行训练的。然后,相应的权重在通常较小的目标数据集上进行微调。这种策略已被证明可以改善深度学习模型在许多CV任务上的泛化性能。自然地,一些研究也探讨了这种策略在时序领域是否有效[26]、[63]。他们在UCR时序数据集[64]上的实验表明,迁移学习可能会提高或降低下游任务的性能,这取决于源数据集和目标数据集是否相似[26]。
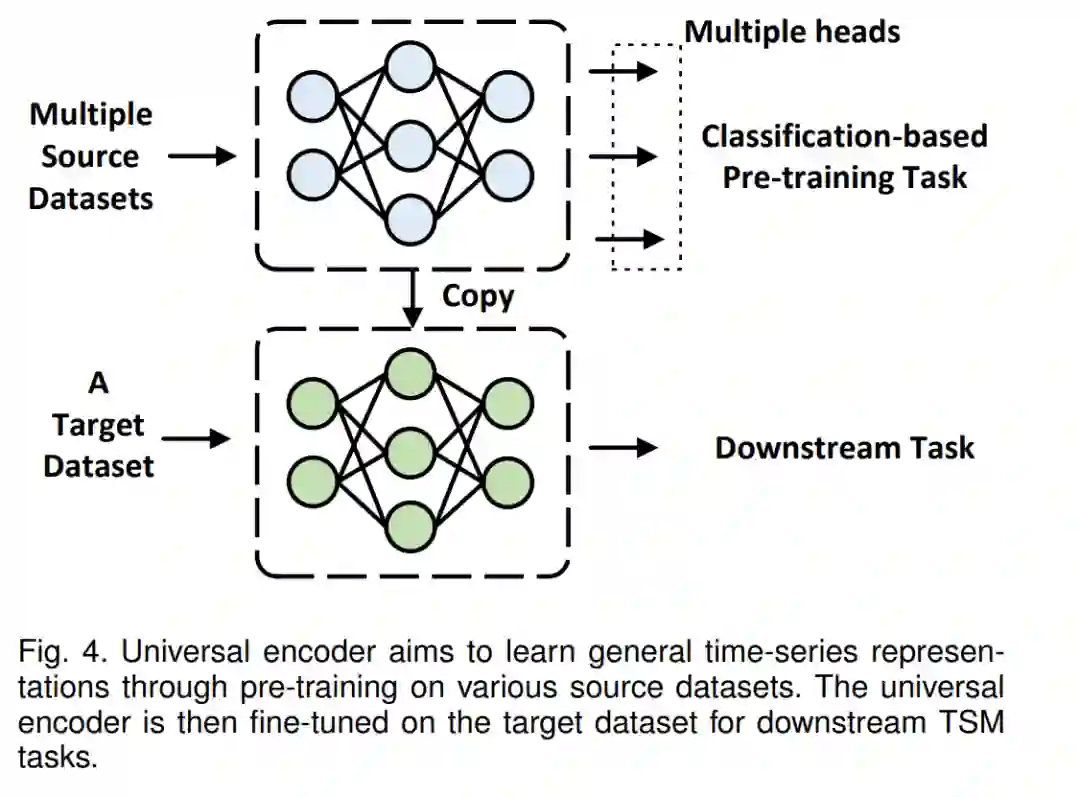
通用编码器首先在标记的源数据集上对基础网络进行预训练,然后将基础网络迁移到目标领域。这通常需要大量的标记源样本进行预训练,在时序领域可能很难获得。当源数据集和目标数据集相似(不相似)时,通常会出现正向(负向)转移。先前的研究已经探索了如何基于数据集间的相似性或潜在表示空间中的时序表示来选择源数据。此外,基于领域适应的对齐编码器考虑了源数据和目标数据分布之间的差异。Voice2Serie [27]提供了一种基于分类的PTMs的新方法。一些特定领域的时序数据(例如语音数据)被用来预训练基础网络,然后通过模型重编程应用于通用时序数据。然而,如何构建一个大规模、标注良好的适用于TS-PTMs的时序数据集尚未探索。
基于时间序列预测(TSF)的预训练模型(PTMs)可以利用时间序列中的复杂动态性,引导模型捕获时间依赖性。基于自回归的模型使用子序列之间的依赖性和同一时间序列未来预测值的一致性,因此使用TSF预训练时间序列数据。与使用人工标签进行预训练的基于分类的PTMs不同,避免在基于TSF任务的预训练中出现子序列(例如,异常值)之间的抽样偏差仍然具有挑战性[68]。同时,基于元学习的自适应编码器允许目标数据集中存在少量时间序列样本的情景。另外,基于回归的单步预测模型(例如,RNNs)可能会因累积错误[10],[49]导致性能下降。相反,一些研究[14],[60]采用基于Transformer的模型一次性生成所有预测。因此,设计高效的TSF编码器将是研究基于TSF的PTMs的基础。
2.2 无监督预训练模型
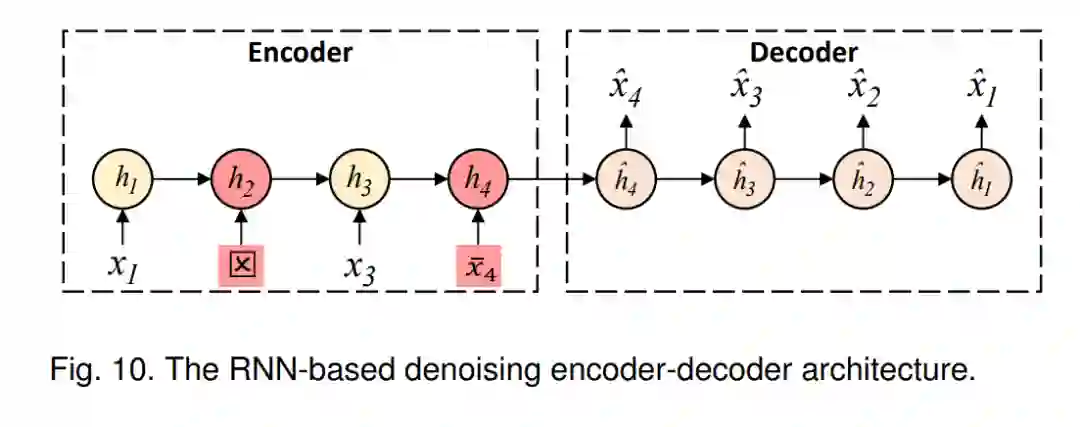
本节介绍无监督的时间序列预训练模型(TS-PTMs),这些模型通常通过重建技术进行预训练。与有监督的TS-PTMs相比,无监督的TS-PTMs应用更为广泛,因为它们不需要有标签的时间序列样本。
2.3 自监督预训练模型
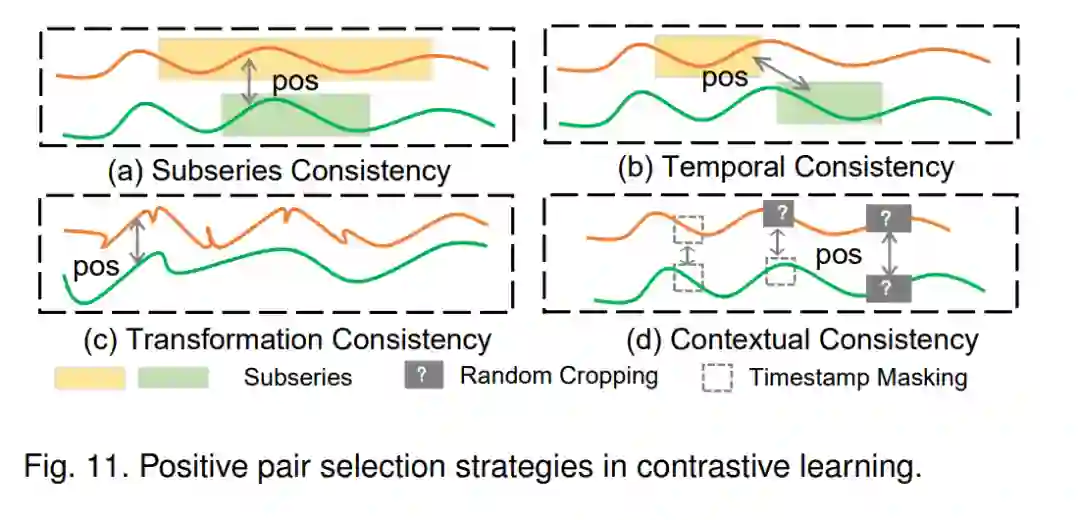
本节介绍了基于一致性和伪标签训练策略的自监督时间序列预训练模型(TS-PTMs),这些策略在自监督学习中常常被使用。与无监督学习(例如,重构)相比,自监督学习在训练过程中使用自提供的监督信息(例如,伪标签)。
3. 实验结果与分析
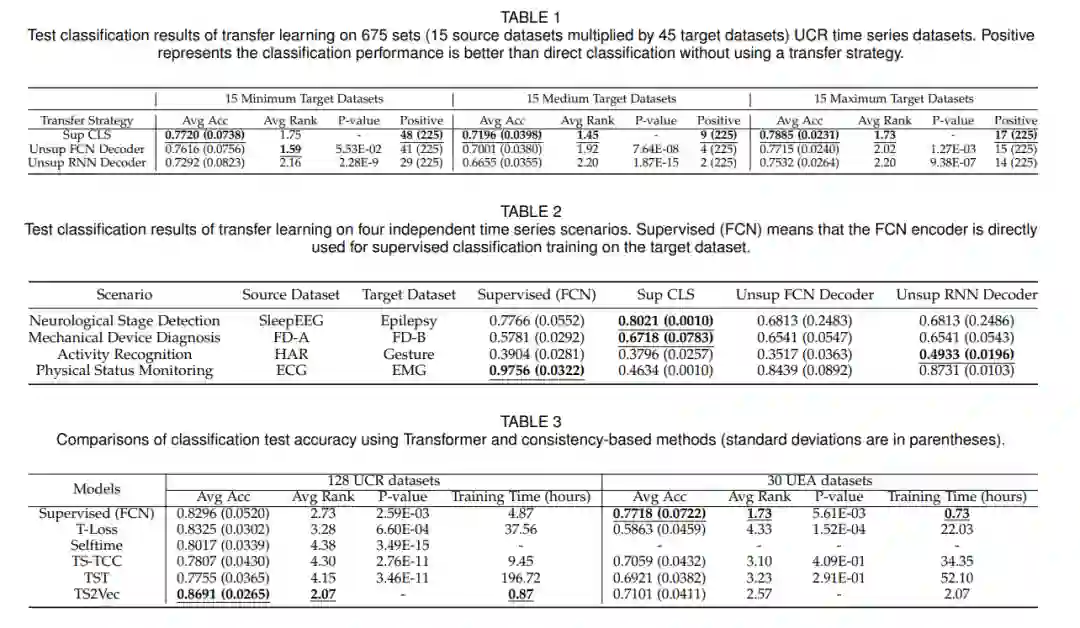
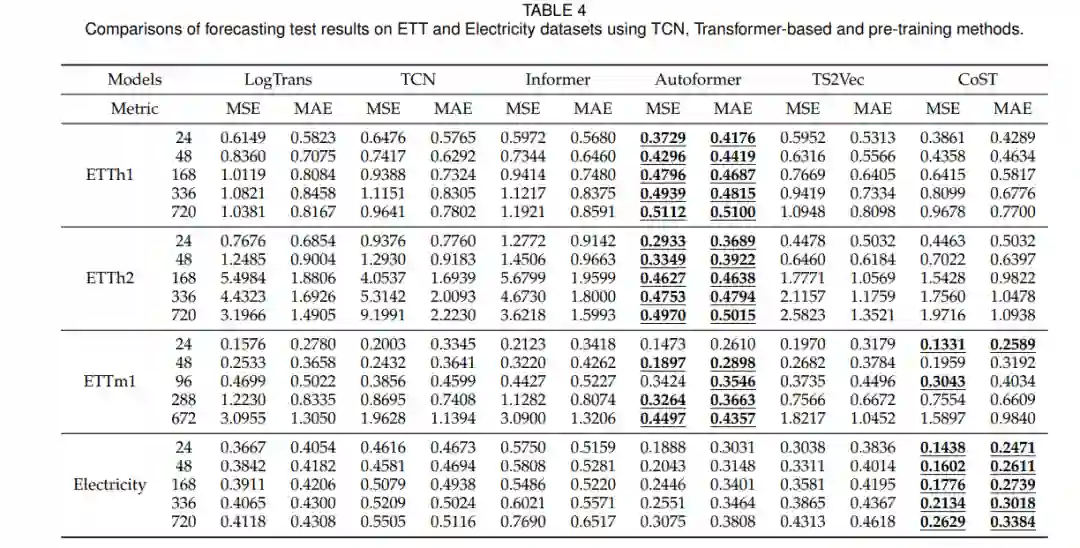
在本节[68]、[142]中,我们在三个TSM任务上评估TS-PTMs,包括分类、预测和异常检测。与[68]一样,我们选择了相应TSM任务中使用的一系列时间序列基准数据集进行评估。我们首先使用UCR[148]和UEA [149] archives时间序列数据集分析了TS-PTMs在分类任务上的性能。继[31]之后,选择了4个时间序列场景数据集进行迁移学习PTMs分析。其次,使用ETT[14]和Electricity[150]数据集比较了TSPTMs和相关基线在预测任务上的性能。最后,利用Yahoo[151]和KPI[152]数据集,分析TS-PTMs和相关基线在异常检测任务上的性能。有关数据集、基线和实现细节的信息,请参阅附录A。
6. 结论
在这份综述中,我们对时间序列预训练模型(TS-PTMs)的发展进行了系统性的回顾和分析。在早期关于TS-PTMs的研究中,相关研究主要基于CNN和RNN模型对PTMs进行迁移学习。近年来,基于Transformer和一致性的模型在时间序列下游任务中取得了显著的性能,并已被用于时间序列预训练。因此,我们对现有的TS-PTMs、迁移学习策略、基于Transformer的时间序列方法以及在时间序列分类、预测和异常检测这三个主要任务上的相关代表性方法进行了大规模的实验分析。实验结果表明,基于Transformer的PTMs对于时间序列预测和异常检测任务具有显著的潜力,而为时间序列分类任务设计合适的基于Transformer的模型仍然具有挑战性。同时,基于对比学习的预训练策略可能是未来TS-PTMs发展的潜在焦点。
