**最近许多机器学习成功的基础是在大量非结构化文本上预训练的自然语言表示。在过去的几十年里,自然语言表示一直在越来越大的数据集上进行训练,最近的表示在超过一万亿token上进行训练。**然而,尽管有如此巨大的规模,现有的表示仍然面临着长期以来的挑战,如捕捉罕见的或长尾的知识和适应自然语言反馈。一个关键的瓶颈是,当前的表示依赖于在非结构化数据中记忆知识,因此最终受到非结构化数据中存在的知识的限制。非结构化数据具有关于许多实体(人、地点或事物)的有限事实,以及有限的特定于领域的数据,如面向目标的对话。本文利用大量未开发和精心策划的资源结构数据来改善自然语言表示。结构化数据包括知识图谱和项集合(例如,播放列表),它们包含实体之间丰富的关系,例如艺术家的出生地、一首歌的所有版本或同一艺术家的所有歌曲。从非结构化数据中学习这些关系可能很困难,因为它们在非结构化数据中可能不经常出现,甚至可能根本不存在。然而,结构化数据有其局限性:人们使用非结构化的自然语言进行交流,而结构化数据也可能是不完整的和嘈杂的。
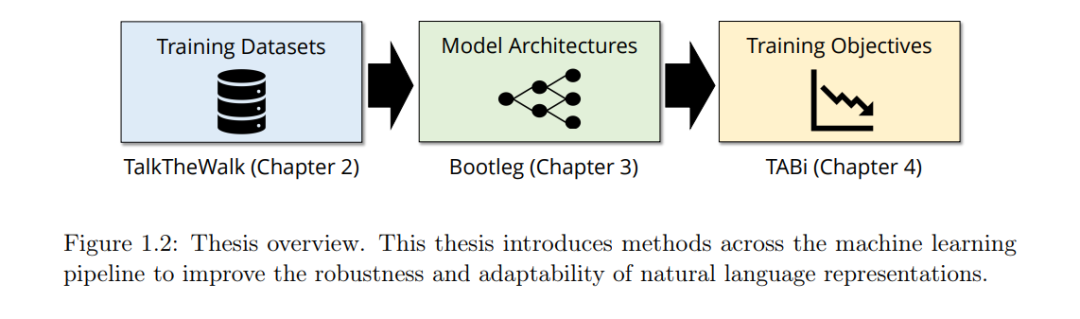
https://searchworks.stanford.edu/view/14641232 **在非结构化和结构化数据互补知识的激励下,本文提出三种将结构化数据与非结构化数据相结合以训练自然语言表示的技术。**我们的技术跨越了机器学习管道的三个主要部分:训练数据、模型架构和训练目标。首先,通过TalkTheWalk,我们使用结构化数据为会话推荐系统生成非结构化训练数据。通过在合成数据上训练一个会话音乐推荐系统,展示了结构化数据如何帮助提高对标准推荐基线的适应性。Bootleg引入了一种基于transformer的架构,利用结构化数据从非结构化文本中学习命名实体消歧的关键推理模式。学习这些推理模式,可以显著提高在文本中很少或从不出现的实体的消歧能力,讨论了将Bootleg应用于一家大型技术公司的生产助理任务的结果。利用TABi,在对比损失函数中添加结构化数据作为监督,以提高鲁棒性,同时使用更通用的模型。实验结果表明,TABi不仅提高了稀有实体检索,而且在结构化数据不完整和有噪声的环境中表现强劲。本文中介绍的三种技术——talkthewalk、Bootleg和TABi——证明了将结构化数据与非结构化数据相结合的训练方法可以实现更鲁棒和适应性更强的自然语言表示。