

在许多科学领域,大型语言模型(LLMs)彻底改变了处理文本和其他数据模式(例如分子和蛋白质)的方式,在各种应用中实现了卓越的性能,并增强了科学发现过程。然而,以往关于科学LLMs的综述往往集中在一到两个领域或单一模式上。本文旨在通过揭示科学LLMs在其架构和预训练技术方面的跨领域和跨模式连接,提供一个更全面的研究视角。为此,我们全面调查了250多种科学LLMs,讨论了它们的共性和差异,并总结了每个领域和模式的预训练数据集和评估任务。此外,我们还探讨了LLMs如何部署以促进科学发现。与本综述相关的资源可在https://github.com/yuzhimanhua/Awesome-Scientific-Language-Models获取。

大型语言模型(LLMs)的出现(Zhao et al., 2023c)为自然语言处理(NLP)带来了新的范式,取代了为每个任务设计的专用模型,使用统一的模型来有效地解决广泛的问题。在科学领域,这种范式不仅重塑了人们处理与自然语言相关任务(如科学论文、医疗记录和气候报告)的策略,还激发了处理其他类型数据(如分子、蛋白质、表格和元数据)的类似想法。除了理解现有的科学数据外,LLMs还展示了通过生成、规划等方式加速科学发现的潜力(Wang et al., 2023c; Zhang et al., 2023f; Wang et al., 2024b)。 鉴于LLMs在各种科学领域和多种模式中的广泛而深远的影响,有必要全面回顾这一方向的相关工作。然而,现有的科学LLMs综述通常只关注一到两个领域(如生物医学(Wang et al., 2023a; He et al., 2024; Pei et al., 2024)和化学(Xia et al., 2023; Zhang et al., 2024c))或单一模式(如文本(Ho et al., 2024))。事实上,如果我们全面观察研究领域,可以看到不同领域和模式中开发LLMs所使用的类似和相互关联的技术。
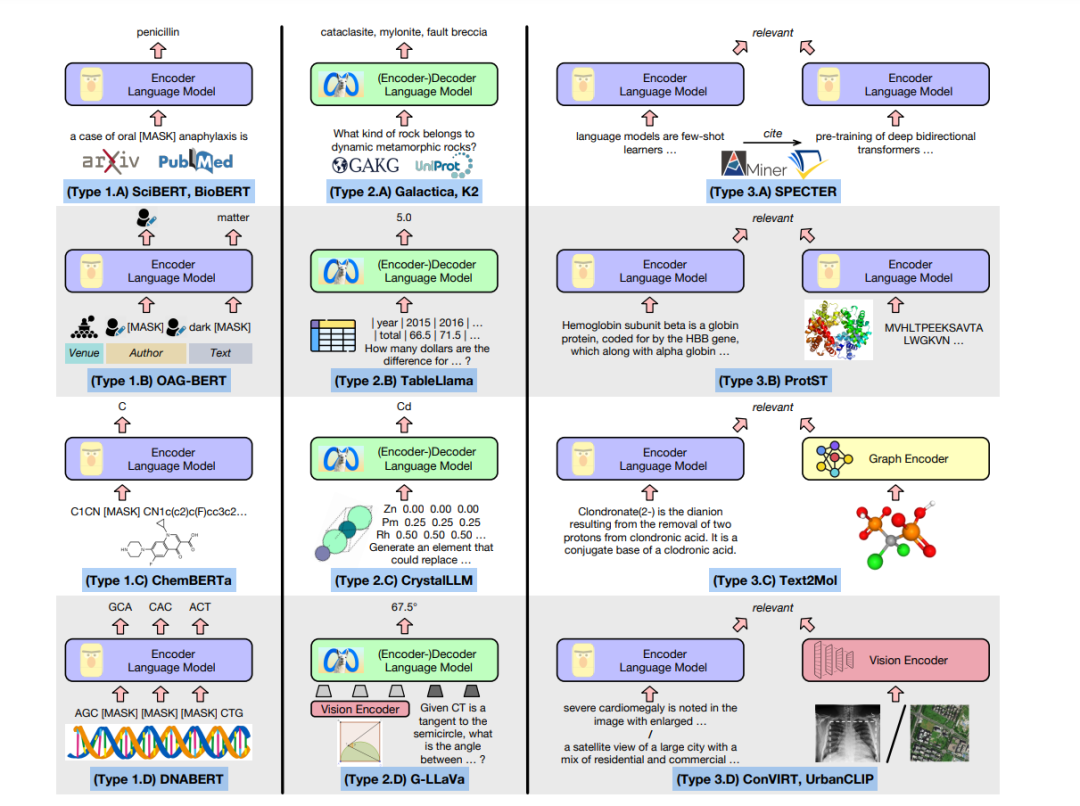
图1展示了三种主要的科学LLM预训练策略(即第1到3列),每种策略我们给出4个例子(即A到D类型)。在第1列,继BERT(Devlin et al., 2019)和RoBERTa(Liu et al., 2019)之后,现有研究使用掩码语言模型(MLM)来预训练编码器语言模型。这里,输入可以是自然序列(如各领域的论文、FASTA格式(Lipman and Pearson, 1985)的蛋白质/DNA/RNA序列)或人为线性化的序列(如SMILES格式(Weininger, 1988)的分子、引文图中的场所/作者/参考节点序列)。
在第2列,受到GPT(Brown et al., 2020)和LLaMA(Touvron et al., 2023a)的启发,先前的研究采用下一个标记预测来预训练(编码器-)解码器语言模型,其中一些进一步采用指令微调和偏好优化(Ouyang et al., 2022)。除了纯文本输入(如知识库或考试中的问答对)外,我们看到更多序列化复杂科学数据的方法,如展平表格单元格并使用粒子坐标描述晶体。即使是图像,在数学(Gao et al., 2023)和生物医学(Li et al., 2023a)中也有研究利用视觉编码器将图像投射到几个视觉标记上,并将它们作为线性化的LLM输入预先附加到文本标记前。
在第3列,继DPR(Karpukhin et al., 2020)和CLIP(Radford et al., 2021)之后,两个编码器通过对比学习预训练,以使相关数据对在潜在空间中更接近。
当两种模态都是序列化的(例如文本-文本或文本-蛋白质)时,模型建立在两个LLM编码器之上。当我们希望保持一种模式的非序列性质时(例如分子图(Edwards et al., 2021)、胸部X光(Zhang et al., 2022)和航拍图像(Yan et al., 2024)),可以采用相应的图形或图像编码器。总之,跨领域跨模式的综述将更准确地描绘不同科学LLMs之间的联系,展示它们的共性,并可能指导其未来的设计。
贡献:在本文中,受上述讨论的启发,我们系统地调查了250多种科学LLMs,涵盖了各个领域(如一般科学、数学、物理、化学、材料科学、生物学、医学和地球科学)、模式(如语言、图形、视觉、表格、分子、蛋白质、基因组和气候时间序列)和规模(从约1亿到约1000亿参数)。对于每个领域/模式,我们研究了科学LLMs常用的预训练数据集、模型架构和评估任务。基于我们的动机,当我们详细讨论模型架构时,会将它们与图1联系起来,构建跨领域跨模式的连接。此外,我们在表A1-表A6(附录A)中提供了这些科学LLMs的结构化总结。此外,对于不同领域,我们介绍了LLMs如何通过增强科学发现过程的不同方面和阶段(如假设生成、定理证明、实验设计、药物发现和天气预报)来促进科学进步。
2 科学领域的大型语言模型(LLMs)
**2.1 语言
科学LLMs最常用的预训练语料库是来自书目数据库的研究论文,例如AMiner(Tang et al., 2008)、Microsoft Academic Graph(MAG)(Sinha et al., 2015)和Semantic Scholar(Ammar et al., 2018)。其中一些来源(如S2ORC(Lo et al., 2020))包含论文的全文信息,而其他来源则仅有标题和摘要。
科学LLMs的发展与通用领域LLMs的发展具有相似性。具体来说,早期模型在预训练期间以自监督的方式利用论文文本,旨在从大规模未标注语料库中获取科学知识。例如,掩码语言模型(MLM)是基于BERT骨干的科学LLMs的默认预训练任务(图1中的类型1.A,如SciBERT(Beltagy et al., 2019));下一个标记预测被广泛用于基于GPT的科学LLMs(图1中的类型2.A,如SciGPT(Luu et al., 2021))。最近,受到LLMs可以被训练成遵循自然语言指令这一事实的启发(Wei et al., 2022a;Ouyang et al., 2022),研究人员更多地投入于通过指令调优LLMs以解决复杂的科学问题(类型2.A,如Galactica(Taylor et al., 2022)和SciGLM(Zhang et al., 2024a))。指令调优数据通常来自下游任务的数据集,如考试问答(Welbl et al., 2017),并由人类或现有的LLMs(如GPT-4(Achiam et al., 2023))进一步过滤/增强。
通用科学LLMs通常在常见的NLP任务上进行评估,例如命名实体识别(NER)、关系抽取(RE)(Luan et al., 2018)、问答(QA)(Wang et al., 2023g)和分类(Cohan et al., 2019)。
**2.2 语言 + 图
除了纯文本外,科学论文还关联有丰富的元数据,包括出版地点、作者和引用(Zhang et al., 2023h)。这些元数据将论文连接成一个图,补充文本信号以表征论文语义。为了利用元数据,一些研究(类型1.B,如OAG-BERT(Liu et al., 2022b))将论文文本与出版地点/作者作为输入进行MLM;其他研究(类型3.A,如SPECTER(Cohan et al., 2020))将引用链接作为监督,训练LLMs使链接的论文在嵌入空间中更接近。最近的方法进一步修改了LLMs中的Transformer架构,使用适配器(Adapters)(Singh et al., 2023)、嵌入GNN的Transformers(Jin et al., 2023b)和专家混合Transformers(Mixture-of-Experts Transformers)(Zhang et al., 2023g)以更好地捕捉图信号。
图感知的科学LLMs通常在涉及两个文本单元(如论文-论文或查询-论文)关系的任务上进行评估,包括链接预测、检索、推荐和作者名消歧。SciDocs(Cohan et al., 2020)和SciRepEval(Singh et al., 2023)是广泛采用的基准数据集。
**2.3 在科学发现中的应用
高性能的科学LLMs可以在整个科学发现过程中与研究人员协同工作。在后续章节将详细讨论领域特定的应用,这里强调LLMs在头脑风暴和评估中的一般用途:Lahav et al.(2022)将LLMs集成到搜索引擎中,用于发现科学挑战和方向;Wang et al.(2023f)和Baek et al.(2024)利用LLMs生成基于先前文献的新科学思想;Zhang et al.(2023i)依靠LLMs为每篇投稿找到专家评审;Liu and Shah(2023)、Liang et al.(2023a)和D'Arcy et al.(2024)探索了GPT-4在提供研究论文反馈以促进自动评审生成方面的能力。
3 数学领域的大型语言模型(LLMs)
3.1 语言
数学LLMs的预训练文本语料库可以分为两类:(1)多项选择问答,代表数据集包括MathQA(Amini et al., 2019)、Ape210K(Zhao et al., 2020)和Math23K(Wang et al., 2017);(2)生成式问答,代表数据集包括GSM8K(Cobbe et al., 2021a)、MATH(Hendrycks et al., 2021)和MetaMathQA(Yu et al., 2023b)。
类似于通用科学LLMs,早期数学LLMs的骨干模型是BERT(类型1.A,如GenBERT(Geva et al., 2020)和MathBERT(Shen et al., 2021))。这些模型大多通过MLM进行训练,唯一的例外是BERT-TD(Li et al., 2022c),其中采用了对比损失。对于基于GPT的数学LLMs(类型2.A,如GSM8K-GPT(Cobbe et al., 2021b)和NaturalProver(Welleck et al., 2022)),我们发现预训练任务多样化:监督微调、下一个标记预测和指令微调。最新的数学LLMs(类型2.A,如Rho-Math(Lin et al., 2024a)和MAmmoTH2(Yue et al., 2024))基于LLaMA并被训练成遵循自然语言指令。然而,当可用的预训练数据集非常庞大(如550亿标记)时,下一个标记预测仍然是唯一的预训练任务(Azerbayev et al., 2023;Lin et al., 2024a)或用于构建基础模型的辅助任务(Shao et al., 2024;Ying et al., 2024)。
问答(QA)和数学世界问题(MWP)一直是最常见的评估任务。此外,定量推理包含更难的问题,因为模型必须提供完整且自洽的解决方案而不依赖外部工具(Shao et al., 2024;Lin et al., 2024a)。GSM8K和MATH在问答中占主导地位,而MathQA和Math23K则在数学世界问题中占主导地位。对于定量推理,MMLU-STEM(Hendrycks et al., 2020)和Big-Bench Hard(Suzgun et al., 2023)是最广泛采用的。
**3.2 语言 + 视觉
几何学是数学中最重要的分支之一,它通过文本和图表共同表达。因此,几何LLMs必须涉及视觉模式。几何LLMs最常用的预训练数据集包括Geometry3K(Lu et al., 2021)和GeoQA(Chen et al., 2021),它们都包含多项选择的几何问题。
将视觉模式融入LLMs的关键是对图像进行编码并获得线性化的视觉表示。具体而言,InterGPS(Lu et al., 2021)(类型2.D)使用RetinaNet(Lin et al., 2017)将图像转换为一组关系,然后应用BART(Lewis et al., 2020a)生成解决方案;G-LLaVA(Gao et al., 2023)(类型2.D)通过预训练的视觉Transformer(ViT)对视觉输入进行编码,将视觉嵌入与文本嵌入连接,然后将连接结果输入LLaMA-2(Touvron et al., 2023b)。这些模型默认通过序列到序列任务进行预训练,其中问题作为输入,真实答案和可选的推理作为输出。为了更好地进行视觉建模,可以选择添加辅助损失,如掩码图像建模、图像构建或文本-图像匹配。
几何LLMs通过解决几何问题进行评估,模型需要在给定图表及其说明、问题和答案选项的情况下选择正确答案。著名的评估数据集包括Geometry3K(Lu et al., 2021)、GEOS(Seo et al., 2015)和MathVista(Lu et al., 2023b)。
**3.3 表格
大量数学知识以表格数据的形式存储。对于“表格”模式,预训练的著名资源包括WikiTableQuestions(Pasupat and Liang, 2015)、WikiSQL(Zhong et al., 2017)和WDC Web Table(Lehmberg et al., 2016)。
表格中的挑战与图表中的相似,即获得线性化的表格表示。在大多数情况下,表格被压缩成线性文本序列,作为上下文的一部分,并在模型输入中加入问题文本。作为这一研究领域的首批工作之一,TAPAS(Herzig et al., 2020)(类型1.A)采用MLM对象来预测文本和表格上下文中的掩码标记。最近的发展(Li et al., 2023c;Zhang et al., 2024d)类似于TableLlama(Zhang et al., 2023d)(类型2.B)的设计,以LLaMA-2为骨干,并以指令微调作为预训练任务。
表格LLMs通过表格问答进行验证,模型需要在给定表格结构、数据值和问题文本的情况下生成正确答案。大多数现有研究在WikiTableQuestions和WikiSQL数据集上进行了评估。TableInstruct(Zhang et al., 2023d)是最新开发的综合基准,集成了跨11个任务的14个数据集。
**3.4 在科学发现中的应用
数学LLMs具有很大的潜力来辅助人类提供潜在的解决方案。例如,AlphaGeometry(Trinh et al., 2024)将LLM与符号推理引擎结合,LLM生成有用的构造,符号引擎应用形式逻辑来寻找解决方案。AlphaGeometry解决了国际数学奥林匹克竞赛的30个经典几何问题中的25个。Sinha et al.(2024)通过添加吴氏方法(Wu's method)(Chou, 1988)扩展了AlphaGeometry,进一步解决了30个中的27个,超过了人类金牌得主。FunSearch(Romera-Paredes et al., 2024)将LLM与程序搜索结合起来。FunSearch的一个显著成就是能够找到组合优化中帽子集问题的新解决方案。这些生成的解决方案比人类专家设计的更快更有效。在Li et al.(2024a)中,LLMs通过利用上下文学习和链式推理(Wei et al., 2022b)迭代提出和评估统计模型。
4 物理领域的大型语言模型(LLMs)
现有的物理LLMs主要集中在天文学和“语言”模式上。作为BERT的衍生产品,astroBERT(Grezes et al., 2021)(类型1.A)通过MLM和下一句预测进一步使用与天文学相关的论文进行预训练。它在命名实体识别(NER)任务上进行评估。同样,AstroLLaMA(Nguyen et al., 2023b)(类型2.A)使用来自arXiv的超过30万篇天文学摘要对LLaMA-2进行微调。它在论文生成和论文推荐任务上进行评估。AstroLLaMA-chat(Perkowski et al., 2024)(类型2.A)是AstroLLaMA的聊天版本。它在GPT-4生成的特定领域对话数据集上持续训练。
5 化学与材料科学领域的大型语言模型(LLMs)
**5.1 语言
化学和材料科学领域的LLMs预训练语料库通常来自研究论文和数据库(例如,Materials Project(Jain et al., 2013))。此外,最近的工作采用了从PubChem(Kim et al., 2019)、MoleculeNet(Wu et al., 2018)等来源派生的领域特定指令微调数据集(例如,MolInstructions(Fang et al., 2023a)和SMolInstruct(Yu et al., 2024))。
早期的化学LLMs大多采用中等规模的仅编码器架构,通过MLM预训练(类型1.A,如ChemBERT(Guo et al., 2022)、MatSciBERT(Gupta et al., 2022)和BatteryBERT(Huang and Cole, 2022))。这些模型通常在下游任务上进行评估,包括反应角色标注(Guo et al., 2022)和摘要分类(Gupta et al., 2022)。最近,研究人员更多地关注通过下一个标记预测和指令微调训练的大规模仅解码器LLMs(类型2.A)。示例包括ChemDFM(Zhao et al., 2024)、ChemLLM(Zhang et al., 2024b)和LlaSMol(Yu et al., 2024)。鉴于这些模型的广泛推广能力,它们在多样化的任务集上进行评估,如名称转换(Kim et al., 2019)、反应预测(Jin et al., 2017)、逆合成(Schneider et al., 2016)、基于文本的分子设计(Edwards et al., 2022)和晶体生成(Antunes et al., 2023;Flam-Shepherd和Aspuru-Guzik, 2023;Gruver et al., 2024)。
**5.2 语言 + 图
图是表征分子的合适数据结构(Jin et al., 2023a)。包含分子图的流行数据集包括ChEBI-20(Edwards et al., 2021, 2022)、ZINC(Sterling和Irwin, 2015)和PCDes(Zeng et al., 2022)。 在某些场景中,分子图与文本信息同时出现,因此现有工作探索了如何有效地编码两者。第一类模型采用GNN作为图编码器,LLM作为文本编码器。两种模式通过对比学习连接(Liu et al., 2023d)(类型3.C)。例如,Text2Mol(Edwards et al., 2021)使用GCN(Kipf和Welling, 2016)和SciBERT分别编码分子及其相应的自然语言描述,以进行文本到分子的检索。第二类模型同时使用LLM编码文本和图(Zeng et al., 2022)。图可以线性化为SMILES字符串(Edwards et al., 2022)(类型2.C),或通过图编码器投射到虚拟标记上(Zhao et al., 2023a;Liu et al., 2023f)(类型2.D)。例如,3D-MoLM(Li et al., 2024b)使用3D分子编码器将分子表示为标记,并与指令一起输入LLaMA-2以进行分子到文本的检索和分子描述。
**5.3 语言 + 视觉
补充文本和图模式,分子图像构成了化学中的视觉模式。现有工作采用类似于BLIP-2(Li et al., 2023b)的理念,将每个图像表示为标记并输入LLM(类型2.D)。例如,GIT-Mol(Liu et al., 2024)将包括图和图像在内的所有模式投射到潜在文本空间,并使用T5(Raffel et al., 2020)进行编码和解码。
**5.4 分子
不同于5.2节,本节介绍不含相关文本信息的分子模型。也就是说,受到LLMs启发的类似方法被用来开发分子语言模型(Flam-Shepherd et al., 2022)。具体来说,大多数研究采用SMILES或SELFIES(Krenn et al., 2020)字符串作为分子的序列表示。类似于“语言”模式的趋势,先驱分子LLMs关注双向Transformer编码器的表示学习(类型1.C,如SMILES-BERT(Wang et al., 2019)和MoLFormer(Ross et al., 2022))。例如,ChemBERTa(Chithrananda et al., 2020)采用与RoBERTa(Liu et al., 2019)类似的架构和预训练策略。这些模型在分子理解任务中表现出色,如分子性质预测(例如毒性分类(Wu et al., 2018)和原子化能量回归(Ramakrishnan et al., 2014))以及虚拟筛选(Riniker和Landrum, 2013)。后来的工作探索了以自回归方式表示分子(类型2.C,如BARTSmiles(Chilingaryan et al., 2022)和ChemGPT(Frey et al., 2023))。例如,T5Chem(Lu和Zhang, 2022)采用T5骨干和序列到序列预训练目标。这些模型在生成任务中进行评估,包括分子生成(Gaulton et al., 2017)、反应预测和逆合成。除了线性化分子,还有研究修改Transformer架构以接纳分子图,如MAT(Maziarka et al., 2020)和R-MAT(Maziarka et al., 2024)。
**5.5 在科学发现中的应用
先前的研究表明,LLMs促进了自主化学研究。例如,Bran et al.(2024)提出了一个化学LLM代理ChemCrow,可以集成专家设计的工具用于有机合成、药物发现和材料设计;Boiko et al.(2023)开发了一个由LLM驱动的智能系统Coscientist,可以设计、规划和执行化学研究。LLMs还帮助药物和催化剂设计。例如,ChatDrug(Liu et al., 2023e)探索了使用LLMs进行药物编辑,采用提示模块、领域反馈模块和对话模块;DrugAssist(Ye et al., 2023a)被提议为一种基于LLM的交互模型,通过人机对话进行分子优化;Sprueill et al.(2023, 2024)使用LLMs作为代理,通过蒙特卡罗树搜索和原子神经网络模型的反馈寻找有效催化剂。
6 生物学与医学领域的大型语言模型(LLMs)
**6.1 语言
生物医学LLMs的预训练语料库包括研究文章(例如,来自PubMed的标题/摘要(Lu, 2011)和PMC的全文(Beck和Sequeira, 2003))、电子健康记录(例如,MIMIC-III(Johnson et al., 2016),MIMIC-IV(Johnson et al., 2023))、知识库(例如,UMLS(Bodenreider, 2004))以及健康相关的社交媒体帖子(例如,COVID-19推文(Müller et al., 2023))。最近的研究进一步从医学考试问题、知识图谱和医生-患者对话中收集监督微调和偏好优化数据集。例子包括ChiMed(Ye et al., 2023b),MedInstruct-52k(Zhang et al., 2023e),以及BiMed1.3M(Acikgoz et al., 2024),其中许多包含非英语成分(例如中文和阿拉伯语)。
生物医学LLMs发展的分水岭时刻是十亿参数架构和指令微调的出现。在此之前,探索了各种中等规模的骨干,包括基于编码器的(类型1.A,例如,BioBERT(Lee et al., 2020),Bio-ELECTRA(Ozyurt, 2020),BioRoBERTa(Lewis et al., 2020b),BioALBERT(Naseem et al., 2022),以及Clinical-Longformer(Li et al., 2022a))和基于编码器-解码器的(类型2.A,例如,SciFive(Phan et al., 2021),BioBART(Yuan et al., 2022a),以及BioGPT(Luo et al., 2022))。这些模型的评估任务从生物医学命名实体识别、关系抽取、句子相似度估计、文档分类和问答(即BLURB基准(Gu et al., 2021))到自然语言推理(NLI)(Romanov和Shivade, 2018)和实体链接(Dogan et al., 2014)。分水岭之后的趋势是指令微调十亿参数LLMs(类型2.A,例如,Med-PaLM(Singhal et al., 2023a),MedAlpaca(Han et al., 2023),以及BioMistral(Labrak et al., 2024))。相应地,评估任务变为单轮问答(Jin et al., 2021;Pal et al., 2022)和多轮对话(Wang et al., 2023h)。与此同时,有研究提出了专门针对生物医学检索任务的双编码器架构(类型3.A,例如,Jin et al., 2023c和Xu et al., 2024),其基准包括NFCorpus(Boteva et al., 2016),TREC-COVID(Voorhees et al., 2021)等。
**6.2 语言 + 图
生物医学本体捕捉了实体之间的丰富关系。类似地,引用链接表征了生物医学论文之间的连接。直观上,共同利用文本和图信息为问答中的多跳推理铺平了道路。例如,Yasunaga et al.(2022a)提出使用LLM和GNN分别编码文本和本体信号,并深度融合它们(类型3.C);Yasunaga et al.(2022b)将来自两个关联论文的文本段落连接起来,并将序列输入LLM进行预训练,这本质上是将元数据邻居(即引用)作为上下文附加到MLM中(类型1.B)。这两种方法在需要复杂推理的问答任务上展示了显著的改进。
**6.3 语言 + 视觉
生物医学文本-图像对通常来自两种来源:(1)医学报告,如胸部X光片(例如,MIMIC-CXR(Johnson et al., 2019))和病理报告(Huang et al., 2023b);以及(2)从生物医学论文中提取的图表-标题对(例如,ROCO(Pelka et al., 2018)和MedICaT(Subramanian et al., 2020))。
大多数生物医学视觉语言模型利用CLIP架构(Radford et al., 2021),其中一个文本编码器和一个图像编码器通过对比学习共同训练,将配对的文本和图像映射得更近(类型3.D)。文本编码器的选择从BERT(Zhang et al., 2022)和GPT-2(Huang et al., 2023b)演变到LLaMA(Wu et al., 2023)和LLaMA-2(Liu et al., 2023b),而图像编码器则从ResNet(Huang et al., 2021)演变到ViT(Zhang et al., 2023c)和Swin Transformer(Thawkar et al., 2023)。MLM、掩码图像建模和文本-文本/图像-图像对比学习(即,通过在语言/视觉模式内创建增强视图)有时作为辅助预训练任务。除了CLIP,其他通用领域的视觉语言架构,如LLaVA(Li et al., 2023a)、PaLM-E(Tu et al., 2024)和Gemini(Saab et al., 2024)也被探索。例如,LLaVA-Med(类型2.D)将图像编码为几个视觉标记,并将它们附加到文本标记之前作为LLM输入。这些模型的评估任务包括图像分类、分割、目标检测、视觉问答、文本到图像/图像到文本的检索和报告生成,其基准包括CheXpert(Irvin et al., 2019)、PadChest(Bustos et al., 2020)、SLAKE(Liu et al., 2021a)等。
**6.4 蛋白质、DNA、RNA和多组学
FASTA格式(Lipman和Pearson, 1985)自然地将蛋白质表示为氨基酸序列,将DNA/RNA表示为核苷酸序列,使得模型可以将它们视为“语言”。这些序列的代表资源包括蛋白质的UniRef(Suzek et al., 2015)和SwissProt(Bairoch和Apweiler, 2000),DNA的GRCh38(Harrow et al., 2012)和1000 Genomes Project(Consortium, 2015),以及RNA的RNAcentral(Consortium, 2019)。
仅编码器的蛋白质、DNA和RNA LLMs(类型1.D),如ESM-2(Lin et al., 2023b),DNABERT(Ji et al., 2021),和RNABERT(Akiyama和Sakakibara, 2022),采用类似BERT的架构,并以MLM作为预训练任务(即预测掩码氨基酸、核苷酸、k-mers或密码子);仅解码器的模型,如ProGen(Madani et al., 2023)和DNAGPT(Zhang et al., 2023a),利用类似GPT的架构,并以下一个标记预测作为预训练任务。也有研究共同考虑文本和蛋白质模式。例如,ProtST(Xu et al., 2023b)通过对比学习(类型3.B)将蛋白质序列与其文本描述(即名称和功能)匹配;BioMedGPT(Luo et al., 2023c)首先将蛋白质投射到标记上,然后将这些标记与文本一起输入LLaMA-2进行指令微调,类似于类型2.D。
现有的多组学LLMs主要集中在单细胞转录组学(例如scRNA-seq)数据上,例如单细胞内基因的表达水平(Franzén et al., 2019)。除了基于BERT的(例如,Geneformer(Theodoris et al., 2023))和基于GPT的(例如,scGPT(Cui et al., 2024))架构外,由于其在处理长scRNA-seq数据时的线性注意力复杂性,Performer(Yang et al., 2022a;Hao et al., 2024)被广泛使用。
**6.5 在科学发现中的应用
类似于化学,LLMs可以在生物学和医学研究中自动化实验。例如,CRISPR-GPT(Huang et al., 2024)增强了一个LLM代理的领域知识,以改进CRISPR基因编辑实验的设计过程。
7 地理、地质与环境科学领域的大型语言模型(LLMs)
**7.1 语言
地球科学LLMs的预训练语料库包括地球科学研究论文、气候相关新闻文章、维基百科页面、企业可持续性报告、知识库(例如,GAKG(Deng et al., 2021))和兴趣点(POI)数据(例如,OpenStreetMap(Haklay and Weber, 2008))。
地球科学LLMs的初步研究主要集中在使用Transformer编码器骨干的双向LLMs的预训练(类型1.A,例如,ClimateBERT(Webersinke et al., 2021),SpaBERT(Li et al., 2022b)和MGeo(Ding et al., 2023))。例如,SpaBERT和MGeo在地理实体链接和查询-POI匹配中对地理位置序列执行MLM。最近,相关研究集中在扩展地球科学中自回归LLMs的解码风格(类型2.A,例如,K2(Deng et al., 2024),OceanGPT(Bi et al., 2023b)和GeoGalactica(Lin et al., 2024b))。例如,K2和OceanGPT分别通过领域特定指令的监督微调,将LLaMA适应于地球科学和海洋科学。这些模型的评估在地球科学基准(例如,GeoBench(Deng et al., 2024)和OceanBench(Bi et al., 2023b))上进行,涵盖广泛的任务,包括问答、分类、知识探测、推理、摘要和生成。
**7.2 语言 + 图
一些地球科学应用涉及图信号,例如异构POI网络和知识图谱。为了共同处理这些信号和文本,ERNIE-GeoL(Huang et al., 2022)在基于BERT的架构中引入了一个基于Transformer的聚合层,以深度融合文本和POI信息;PK-Chat(Deng et al., 2023)结合LLM和指针生成网络在知识图谱上构建了一个知识驱动的对话系统。
**7.3 语言 + 视觉
航拍图像与位置描述共同描绘了城市区域。为了共同处理语言和视觉模式,UrbanCLIP(Yan et al., 2024)考虑了CLIP架构(类型3.D),这也是生物医学视觉语言模型广泛采用的架构(参见6.3节),用于城市指标预测的文本-图像对比学习。
**7.4 气候时间序列
LLMs的直觉和方法论也促进了气候基础模型的构建。基于气候时间序列的ERA5(Hersbach et al., 2020)和CMIP6(Eyring et al., 2016)数据集,以前的研究利用ViT和Swin Transformer架构预训练天气预报的基础模型。代表模型包括FourCastNet(Pathak et al., 2022)、Pangu-Weather(Bi et al., 2023a)等。
**7.5 在科学发现中的应用
在地理学中,Wang et al.(2023b)和Zhou et al.(2024)强调了LLMs在可持续性、生活、经济、灾害和环境视角下城市规划中的潜力。在地质学中,除了气候和天气预报外,基础模型还应用于同时地震检测和相位挑选(Mousavi et al., 2020)。在环境科学中,ChatClimate(Vaghefi et al., 2023)通过提供对气候变化外部、科学准确知识的访问,增强了GPT-4,以构建气候科学对话AI。
8 挑战与未来方向
在本综述中,我们汇编了有关科学LLMs预训练数据、架构和任务的文献,以及科学LLMs如何应用于科学发现的下游应用。特别地,我们强调了在不同领域和模式中科学LLMs演变过程中观察到的类似架构、任务和趋势。除了回顾先前的研究外,我们提出了一些挑战,以激发对这一主题的进一步探索。
**深入细化主题
大多数现有的科学LLMs针对的是一个粗粒度的领域(例如化学),而一些任务依赖于细粒度主题的高度专业知识(例如铃木耦合)。当LLMs在更通用的语料库上进行预训练时,频繁出现的信号可能主导模型参数空间,而领域特定的尾部知识可能被忽略。我们认为,自动策划深入的、主题集中的知识图谱(Hope et al., 2021)并用它们来指导生成过程将是解决这一问题的有前景的方向。
**泛化到分布外的科学数据
在科学领域,测试分布与训练分布的变化是常见的(Zhang et al., 2023f):新发表的论文中不断出现新的科学概念;测试期间可能出现具有不同骨架的未知分子和具有不同肽链数量的未知蛋白质。处理这种分布外数据仍然是预训练科学LLMs的挑战。据我们所知,不变学习(Arjovsky et al., 2019)可以作为分布外分析的理论基础,如何将其整合到LLM预训练中值得探索。
**促进可信的预测
LLMs可能会生成听起来合理但实际上不正确的输出,这通常被称为幻觉(Ji et al., 2023),在化学和生物医学等高风险科学领域尤其危险。为了减轻这一问题,检索增强生成(RAG)为LLMs提供了相关的、最新的和可信的信息。然而,以前在科学领域的RAG研究主要集中在检索文本(Xiong et al., 2024)和知识(Jin et al., 2024),而科学数据是异构和多模式的。我们预计,跨模式RAG(例如,通过相关的化学物质和蛋白质指导文本生成)将提供额外的机会,进一步增强科学LLMs的可信性。
局限性
本综述主要涵盖了数学和自然科学领域的LLMs。我们知道LLMs也可以通过在代表性任务中取得显著成绩(Ziems et al., 2024)并作为社会模拟实验的代理(Horton, 2023)显著影响社会科学,但由于篇幅限制,我们将这些努力的综述留作未来工作。此外,本文重点介绍了在科学数据上预训练或通过领域特定知识增强以促进科学发现的LLMs。还有一些研究(Wang et al., 2023g;Guo et al., 2023)提出了新的科学问题基准数据集,但仅评估了通用LLMs的性能,我们未将这些工作包括在我们的综述中。此外,根据本文的分类标准,一些LLMs可能属于多个领域或模式类别。例如,BioMedGPT(Luo et al., 2023c)同时在生物学和化学数据上进行预训练;GIT-Mol(Liu et al., 2024)同时考虑了语言、图形和视觉模式。为了简洁起见,我们仅在一个小节中介绍每个模型。

