大型语言模型(LLMs)已成为增强自然语言理解的转型力量,代表了向人工通用智能迈出的重要步伐。LLMs的应用超越了传统语言学边界,包括了各个科学学科内发展的特殊语言系统。这一日益增长的兴趣促成了科学LLMs的出现,这是一种专为促进科学发现而精心设计的新型子类。作为AI用于科学领域中的一个新兴领域,科学LLMs值得全面探索。然而,目前缺乏一项系统的、最新的综述来介绍它们。在本文中,我们努力系统地阐述“科学语言”的概念,同时提供对科学LLMs最新进展的详尽回顾。鉴于科学学科的广泛领域,我们的分析采用了聚焦的视角,专注于生物学和化学领域。这包括对LLMs在文本知识、小分子、大分子蛋白、基因组序列及其组合的深入考察,并从模型架构、能力、数据集和评估方面进行分析。最后,我们批判性地审视当前的挑战,并指出与LLMs进展相关的有前途的研究方向。通过提供该领域技术发展的全面概述,这篇综述旨在成为研究者在探索科学LLMs错综复杂的领域时的宝贵资源。
https://www.zhuanzhi.ai/paper/1741b30343c8826898d7c39dafe9df20
人类通过感知和认知获取对世界的知识,其中自然语言(即人类语言)是表达这种世界知识的典型媒介。从历史上看,这种丰富的世界知识已通过自然语言表达、记录和传播。目前,大型语言模型(LLMs)成为处理自然语言和收集世界知识的前沿工具。通常,LLMs指的是基于Transformer架构的,具有数亿(甚至数十亿)可训练参数的模型,它们在广泛的文本语料库上进行训练[218]。典型的例子包括GPT-3 [32]、PaLM [47]、Galactica [233]、LLaMA [239]、ChatGLM [288]和百川2[14]。它们已展现出强大的理解自然语言和处理复杂任务(如文本生成)的能力,并在学术和工业领域引起了极大的兴趣。LLMs的卓越表现让人们希望它们可能会在我们当前的时代进化成为人工通用智能(AGI)。
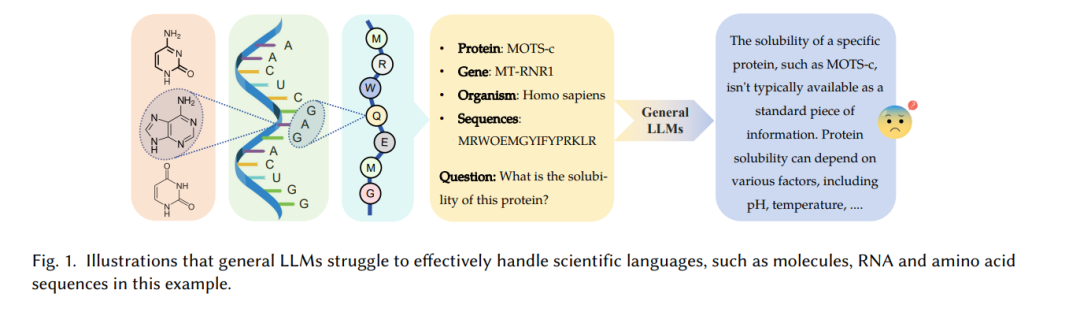
除了自然语言,为了封装更专业的科学知识,开发了一系列的科学语言,如图1所示。这包括科研领域的文本表达、定义数学公式的数学语言、代表分子结构的化学语言(如SMILES),以及描述蛋白质或基因组的生物语言,详细说明生物体的复杂构成。这些科学语言带有它们独特的词汇,每个术语都有特定的含义,与自然语言完全不同。例如,英文中的字符“C”在蛋白质语言中代表氨基酸半胱氨酸[87],而在SMILES语言系统中,它代表一个碳原子[262]。此外,特定领域的专家制定语法规则来组织这些术语,使构建的句子具有精确的语义功能。例如,计算化学家创建语法规则以确保机器生成分子的准确性,使用的是SELFIES格式[128]。经过数十年的演变,科学语言已成为无价的工具,显著加速了科学发现。由于科学语言与自然语言之间可能存在的语义和语法差异,现有的通用LLMs(如ChatGPT 1或GPT-4 [190])通常无法正确处理分子和蛋白质等科学数据[5]。正如著名的奥地利哲学家路德维希·维特根斯坦所指出的,“我的语言的极限意味着我的世界的极限。”[202] 通用LLMs的世界可能仅限于自然语言。
为了促进对科学语言的理解,研究人员设计了专门针对各种科学领域和学科的科学大型语言模型(Sci-LLMs)。例如,分子语言模型已被开发出来,将分子结构表示为一串原子和化学键[140]。这些模型有助于预测分子属性[252]、设计新药[298]、提出逆合成路线[215]。类似地,蛋白质语言模型基于氨基酸序列运作[30, 205]。它们用于预测3D蛋白质结构和功能[149]、改善现有蛋白质以提高适应性[187]、创造具有特定功能的新蛋白质[184]。作为AI-for-Science研究领域内的一个新兴领域,许多Sci-LLMs已被提出,它们具有修改后的架构、学习方法、训练语料库、评估基准和标准。尽管它们取得了显著成就,这些模型大多在各自的研究领域内被探索。目前尚缺乏一个全面的综述,能够统一这些语言建模的进展。
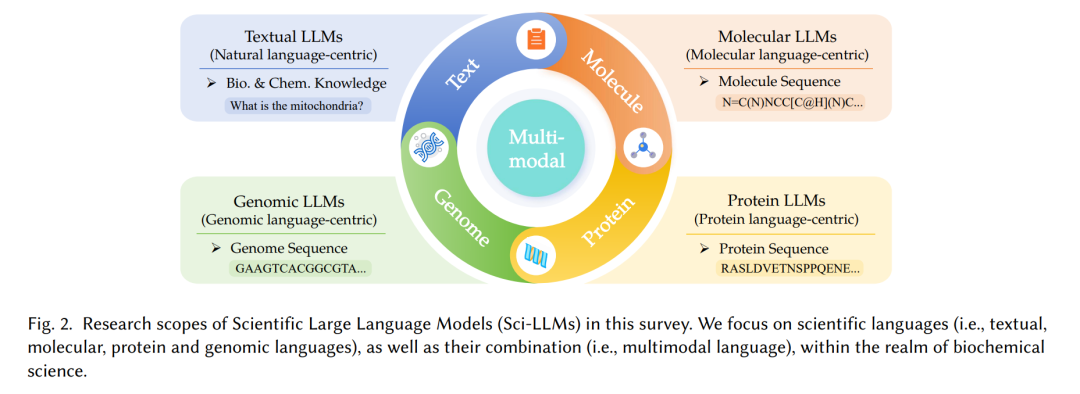
在这篇综述中,我们旨在通过系统地回顾Sci-LLMs的技术进步来填补这一空白,同时密切参考通用LLMs。考虑到科学语言的广泛范围,我们将调查重点放在生物和化学语言上。具体而言,我们的审查涵盖了分子语言、蛋白质语言和基因组语言。除了这些专门的科学语言外,我们也认识到教科书、专利和研究论文中蕴含的巨大科学知识,这些文献都是用自然语言撰写的。因此,我们探索了强调科学知识的文本LLMs,更重要的是,研究了包含各种类型科学语言的多模态LLMs。
在深入探讨每种语言系统时,我们首先回顾了LLM的架构,并将它们分类为三类:仅编码器、仅解码器和编码器-解码器。然后,我们报告了模型的能力,并总结了Sci-LLMs可以执行的典型下游任务。在模型训练和评估方面,我们收集了一系列常用的训练语料库和评估基准。最后,我们提出了科学语言建模的区分性和生成性任务的适当标准。
这项综述受限于特定边界。首先,我们关注科学语言,特别是化学和生物语言。我们排除了那些既没有通用定义的词汇表,也没有语法结构的语言,如数学语言。其次,在讨论文本LLMs时,我们的重点仍然是表达在自然语言中的化学和生物领域知识。这一选择确保了与化学和生物学特定语言(如分子和蛋白质语言)的一致和连贯互动。第三,我们的技术探索主要局限于基于Transformer的语言模型。尽管图神经网络和扩散模型等替代神经架构在分子和蛋白质建模中广泛应用,但我们没有包括它们。图2描述了这项综述中Sci-LLMs的研究范围。
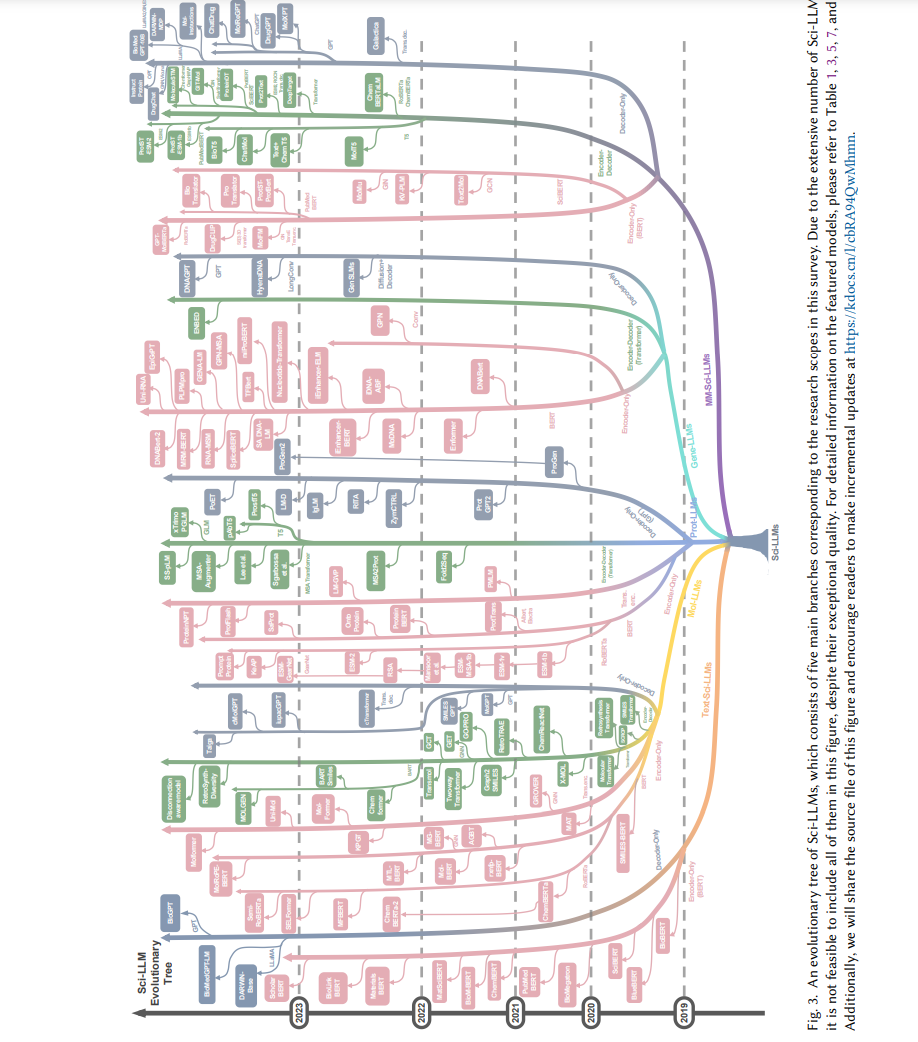
这项综述的独特边界使其不同于其他关于LLMs和分子、蛋白质和基因组计算建模的回顾。与主要集中在自然语言[281, 304]的那些不同,我们的重点更倾向于科学语言。与仅专注于分子[64, 269]、蛋白质[23, 105, 241, 246]或基因组数据[52]的综述不同,我们旨在提供一个关于化学和生物研究的语言模型的全面视角。此外,我们深入探讨了多模态LLMs,探索文本与分子/蛋白质/基因组语言之间的互动。据我们所知,这种微妙的探索在以前的综述中尚未涵盖。本综述的贡献可总结如下: • 我们提供了一个关于科学领域内语言建模的全面回顾,包括文本、分子、蛋白质和基因组语言,强调领域特定知识。 •我们提供了现有Sci-LLMs的详细总结,涵盖了模型架构、能力、训练数据、评估基准和评估标准。我们还在图3中展示了Sci-LLMs的演化树。 • 我们列举了Sci-LLMs的可用资源,开源并在https://github.com/HICAI-ZJU/Scientific-LLM-Survey上维护相关材料,从而方便新入行者的访问。 •** 据我们所知,这项综述代表了第一个全面概述多模态Sci-LLMs的尝试**,旨在探索各种科学语言之间的互动。 本综述的其余部分组织如下:第2节介绍LLMs的背景并阐述相关概念。第3、4、5、6和7节分别介绍文本、分子、蛋白质、基因组和多模态LLMs。最后,在第8节中,我们分析了现有模型的局限性,指出潜在的研究方向,并总结本综述。
**文本科学大型语言模型 **
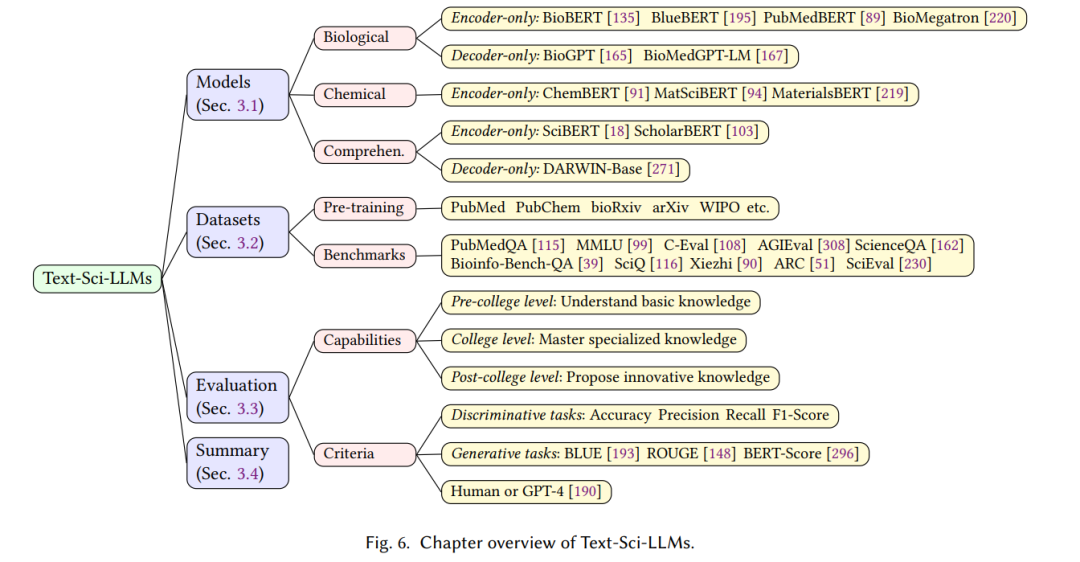
在本节中,我们旨在探索和深入研究专门使用文本语料库(即文本Sci-LLMs)训练的科学大型语言模型,特别强调它们获取化学和生物知识的能力。我们将简要回顾现有的文本Sci-LLMs,并检查它们的能力、所用数据集以及评估方法。本节的概览如图6所示。
**分子大型语言模型 **
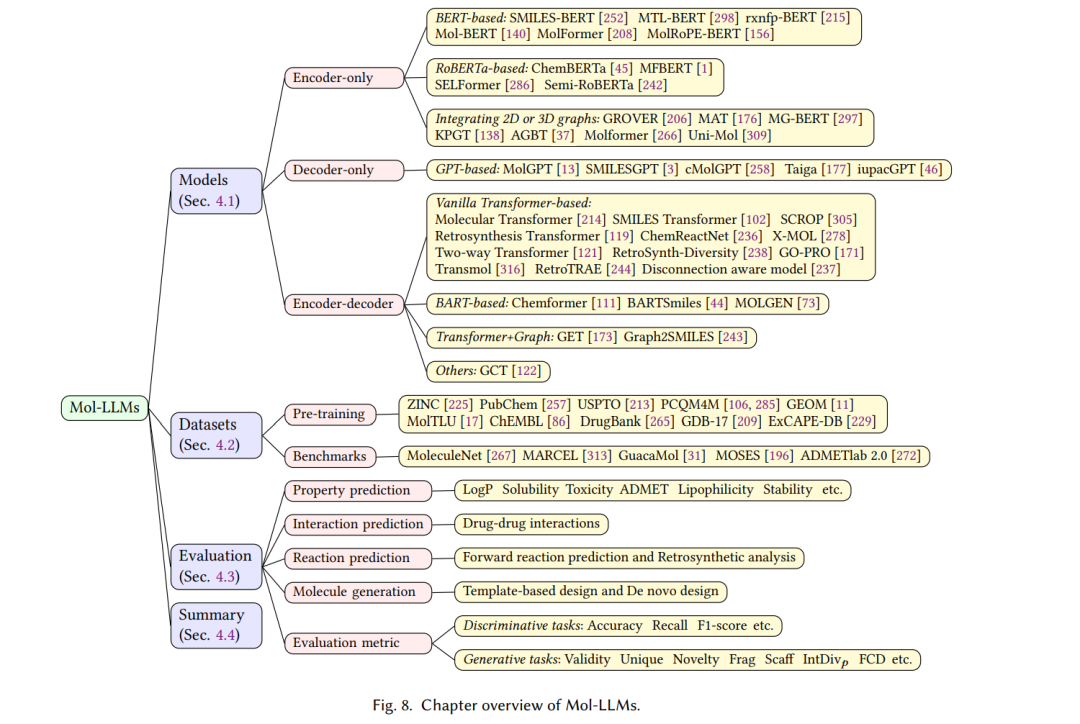
大型语言模型在加速化学分子发现方面显示出巨大潜力。在本节中,我们将回顾在分子语言(Mol-LLMs)中训练的LLMs,包括它们的模型架构、能力、使用的数据集和评估标准的洞察。本节的概览如图8所示。
**蛋白质大型语言模型 **
在过去的几年中,大型语言模型在蛋白质研究中变得越来越有影响力,提供了新颖的见解和能力,用于理解和操纵蛋白质。在本节中,我们提供了一个关于蛋白质的LLMs(称为Prot-LLMs)的全面回顾,包括对它们的模型架构、使用的数据集、各种能力和相应评估标准的详细讨论。本节的概览如图9所示。

**基因组大型语言模型 **
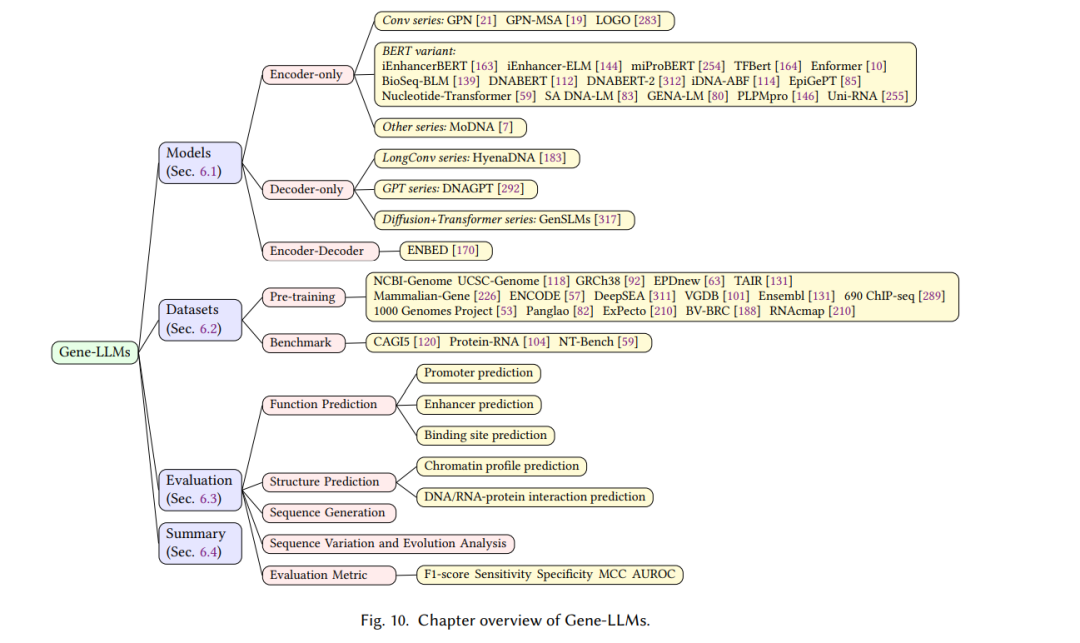
在计算生物学领域,基因组数据显示出与自然语言中观察到的基于序列的信息的相似性,使得大型语言模型能够用于分析基因组序列。在本节中,我们将回顾专为基因组语言(Gene-LLMs)量身定制的LLMs,包括对它们的模型架构、数据集和评估的洞察。本节的概览如图10所示。
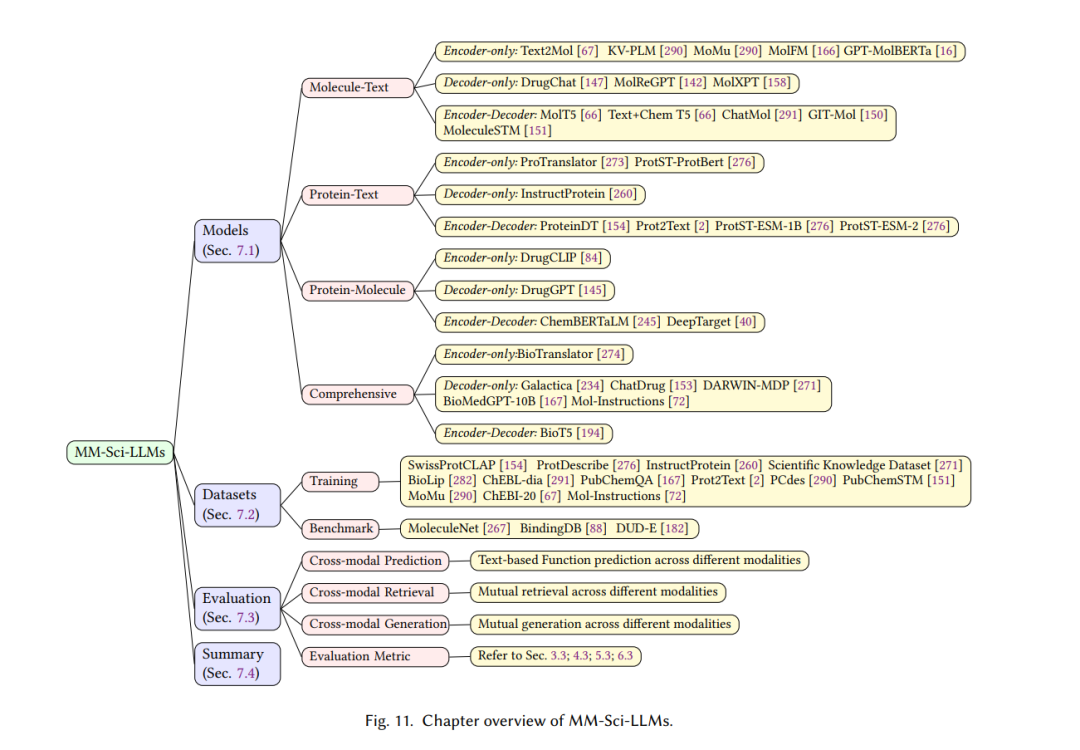
多模态科学大型语言模型
多模态大型语言模型已成为一个突出的研究领域,利用强大的LLMs作为核心来处理多模态数据。这些模型具有将不同数据类型(如文本、图像、音频和其他形式的信息)结合起来的独特能力,使得它们能够在各个领域进行全面的探索和问题解决。这些多模态模型在生物和化学科学领域,特别是蛋白质、分子和基因组研究中,展现出有希望的前景。在本节中,我们探索了这些科学领域内多模态模型的最新进展(即MM-Sci-LLMs),强调它们的能力和利用的数据集。请注意,这项综述专注于跨语言的多模态模型,涉及至少两种来自不同领域的语言,例如文本和分子。因此,我们排除了MM-Sci-LLMs中的单语言多模态方法,如蛋白质序列和结构的联合建模[228, 261, 302]。图4展示了不同语言和模态的多样形式,本节的概览如图11所示。