

本综述深入探讨了大型语言模型(LLMs)领域内的知识蒸馏(KD)技术,突出了KD在将GPT-4等专有巨头的复杂能力转移至LLaMA和Mistral等可访问的开源模型中的关键作用。在不断演变的人工智能领域,这项工作阐明了专有和开源LLMs之间的关键差异,展示了KD如何作为一种重要的渠道,将前者的高级功能和细腻理解注入后者。我们的综述围绕三个基础支柱:算法、技能和垂直化——提供了对KD机制、特定认知能力的增强以及它们在不同领域的实际应用的全面考察。关键地,综述导航了数据增强(DA)与KD之间复杂的相互作用,阐述了DA如何在KD框架内作为一个强大的范式出现,以提升LLMs的性能。通过利用DA生成丰富上下文、特定技能的训练数据,KD超越了传统界限,使开源模型能够逼近其专有对应物的上下文熟练度、伦理一致性和深层语义洞察力。这项工作旨在为研究人员和实践者提供一个富有洞察力的指南,提供知识蒸馏当前方法论的详细概述,并提出未来研究方向。通过弥合专有和开源LLMs之间的差距,本综述强调了更可访问、高效和可持续人工智能解决方案的潜力,促进了人工智能进步中更加包容和公平的景观。相关的Github仓库可在https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs处获得。
https://www.zhuanzhi.ai/paper/65d9c4c6bfc878bf096d5a8ad33a5268
在人工智能(AI)不断演变的景观中,如GPT3.5(Ouyang et al., 2022)、GPT-4(OpenAI et al., 2023)、Gemini(Team et al., 2023)和Claude2等专有的大型语言模型(LLMs)已经作为开创性技术出现,重塑了我们对自然语言处理(NLP)的理解。这些模型以其庞大的规模和复杂性为特征,开启了新的可能性领域,从生成类人文本到提供复杂的问题解决能力。这些LLMs的核心重要性在于它们的涌现能力(Wei et al., 2022a,b),这是一种模型展示出超出其明确训练目标的能力的现象,使它们能够以非凡的熟练度处理多样化的任务。它们对上下文、细微差别和人类语言的复杂性的深刻理解使它们能够在广泛的应用中表现出色,从创意内容生成到复杂问题解决(OpenAI et al., 2023;Liang et al., 2022)。这些模型的潜力远远超出当前的应用,承诺将革新行业,增强人类的创造力,并重新定义我们与技术的互动。尽管像GPT-4和Gemini这样的专有LLMs具有非凡的能力,但在考虑到开源模型提供的优势时,它们并非没有缺点。一个重大的缺点是它们的可访问性有限和成本较高(OpenAI et al., 2023)。这些专有模型通常伴随着高昂的使用费用和限制的访问权限,使得它们对个人和较小的组织来说较难获得。在数据隐私和安全性方面(Wu et al., 2023a),使用这些专有LLMs经常涉及将敏感数据发送到外部服务器,这引发了数据隐私和安全性的担忧。对于处理机密信息的用户而言,这一方面尤其关键。此外,虽然功能强大,但专有LLMs的通用设计可能并不总是与特定需求的小众应用完全对齐。因此,可访问性、成本和适应性的限制呈现出在充分利用专有LLMs的全部潜力方面的重大挑战。
与专有的大型语言模型(LLMs)相比,像LLaMA(Touvron et al., 2023)和Mistral(Jiang et al., 2023a)这样的开源模型带来了几个显著的优势。开源模型的主要好处之一是它们的可访问性和可适应性。没有许可费用或限制性使用政策的约束,这些模型更容易被从个人研究者到较小组织的更广泛用户群体所获取。这种开放性促进了更协作和包容的AI研究环境,鼓励创新和多样化的应用。此外,开源LLMs的可定制性允许更加定制化的解决方案,解决通用的大规模模型可能无法满足的特定需求。然而,开源LLMs也有自己的一套缺点,主要源自于与它们的专有对手相比,它们相对有限的规模和资源。最显著的限制之一是较小的模型规模,这通常导致在具有一堆指令的实际任务上性能较低(Zheng et al., 2023a)。这些参数较少的模型可能难以捕捉GPT-4等更大模型体现的知识的深度和广度。此外,这些开源模型的预训练投资通常较少。这种减少的投资可能导致预训练数据的范围较窄,可能限制模型对多样化或专业化主题的理解和处理(Liang et al., 2022; Sun et al., 2024a)。而且,由于资源限制,开源模型经常进行的微调步骤较少。微调对于优化模型针对特定任务或行业的性能至关重要,缺乏微调可能阻碍模型在专业化应用中的有效性。当这些模型与经过高度微调的专有LLMs相比时,这一限制尤为明显,后者通常被定制以在广泛的复杂场景中表现出色(OpenAI et al., 2023)。
认识到专有和开源LLMs之间的差异,NLP领域见证了采用知识蒸馏技术(Gou et al., 2021; Gupta and Agrawal, 2022)的激增,作为弥合这一性能差距的手段。在这一背景下,知识蒸馏涉及利用像GPT-4或Gemini这样的更大、专有模型的更高级、微妙的能力作为指导框架,以增强开源LLMs的能力。这个过程类似于将一位高度熟练的老师的‘知识’转移给学生,其中学生(例如,开源LLM)学习模仿老师(例如,专有LLM)的性能特征。与传统的知识蒸馏算法(Gou et al., 2021)相比,数据增强(DA)(Feng et al., 2021)已成为实现LLMs知识蒸馏的普遍范式,其中一小部分知识被用来提示LLM针对特定技能或领域生成更多数据(Taori et al., 2023)。这种知识转移的关键方面是技能的增强,如高级上下文跟随(例如,上下文学习(Huang et al., 2022a)和指令跟随(Taori et al., 2023)),与用户意图的更好对齐(例如,人类价值观/原则(Cui et al., 2023a),以及像思维链(CoT)(Mukherjee et al., 2023)这样的思维模式),以及更深层的语言理解(例如,机器推理(Hsieh et al., 2023),语义理解(Ding et al., 2023a),和代码生成(Chaudhary, 2023))。这些技能对LLMs预期执行的广泛应用至关重要,从随意对话到专业领域的复杂问题解决。例如,在医疗保健(Wang et al., 2023a),法律(LAW, 2023)或科学(Zhang et al., 2024)等垂直领域中,准确性和上下文特定知识至关重要,知识蒸馏允许开源模型通过学习这些领域中已经广泛训练和微调的专有模型,显著提高它们的性能。
在LLMs时代,知识蒸馏的好处是多方面的且具有变革性(Gu et al., 2024)。通过一套蒸馏技术,专有和开源模型之间的差距显著缩小(Chiang et al., 2023; Xu et al., 2023a)甚至填补(Zhao et al., 2023a),使后者能够达到之前仅限于它们的专有对手的更高性能和效率水平。这个过程不仅简化了计算需求,而且还提高了AI操作的环境可持续性,因为开源模型在较低的计算开销下变得更加熟练。此外,知识蒸馏促进了一个更包容和公平的AI景观,其中较小的实体和个人研究者获得了最先进能力的访问权限,鼓励了AI进步中更广泛的参与和多样性。这种技术的民主化导致了更强大、多功能和可访问的AI解决方案,催化了各行各业和研究领域的创新和增长。
由于AI景观的迅速演变(OpenAI et al., 2023; Team et al., 2023)和这些模型的增加复杂性,对LLMs知识蒸馏进行全面综述的迫切需求不断上升。随着AI继续渗透到各个领域,从专有LLMs高效、有效地蒸馏知识到开源模型的能力不仅是一个技术愿景,而且是一个实际必需。这种需求由对更可访问、成本效益和可适应AI解决方案的日益增长的需求所驱动,这些解决方案可以满足广泛的应用和用户群体。在这一领域进行综述对于综合当前的方法论、挑战和知识蒸馏的突破至关重要。它可能作为研究人员和实践者的灯塔,引导他们通过将复杂的AI能力蒸馏成更易管理和更易访问形式的错综复杂的过程。此外,这样的综述可以照亮前进的道路,识别当前技术中的差距,并提出未来研究的方向。综述组织。这项综述的其余部分被组织成几个全面的部分,每个部分旨在深入探讨LLMs领域内知识蒸馏的多方面。继本介绍之后,§2提供了知识蒸馏的基础概述,比较了传统技术与LLMs时代出现的技术,并强调了数据增强(DA)在此背景下的作用。§3深入探讨了从教师LLMs中引出知识的方法和核心蒸馏算法,检查了从监督微调到涉及差异和相似性、强化学习和排名优化的更复杂策略的方法。然后,§4专注于技能蒸馏,探索如何增强学生模型以改善上下文理解、与用户意图的对齐以及在各种NLP任务中的表现。这包括对自然语言理解(NLU)、生成(NLG)、信息检索、推荐系统和文本生成评估的讨论。在§5中,我们涉足特定领域的垂直蒸馏,展示了知识蒸馏技术如何在法律、医疗保健、金融和科学等专业领域内应用,说明了这些方法的实际含义和变革性影响。综述在§6中提出了开放问题,识别了知识蒸馏研究中当前的挑战和差距,为未来的工作提供了机会。最后,§7中的结论和讨论综合了获得的洞察,反思了对更广泛的AI和NLP研究社区的影响,并提出了未来研究的方向。
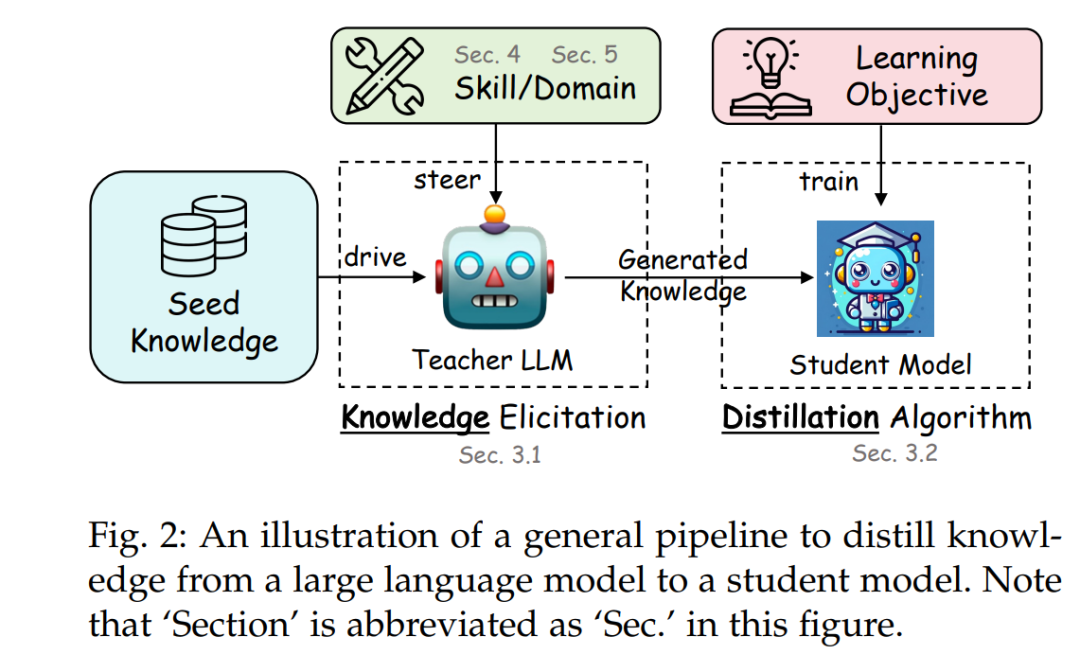
大型语言模型(LLMs)的一般蒸馏流程是一个结构化和有条理的过程,旨在将知识从一个复杂的教师模型转移到一个较不复杂的学生模型。这个流程对于利用像GPT-4或Gemini这样的模型的先进能力,在更可访问且高效的开源对应模型中至关重要。这个流程的概要可以广泛地分为四个不同阶段,每个阶段在知识蒸馏的成功中都扮演着至关重要的角色。一个示意图展示在图2中。
知识蒸馏算法
本节通过知识蒸馏的过程进行导航。根据第2.4节,它被分为两个主要步骤:‘知识’,专注于从教师LLMs中引出知识(公式1),以及‘蒸馏’,集中于将这些知识注入学生模型中(公式2)。我们将在后续章节中详细阐述这两个过程。
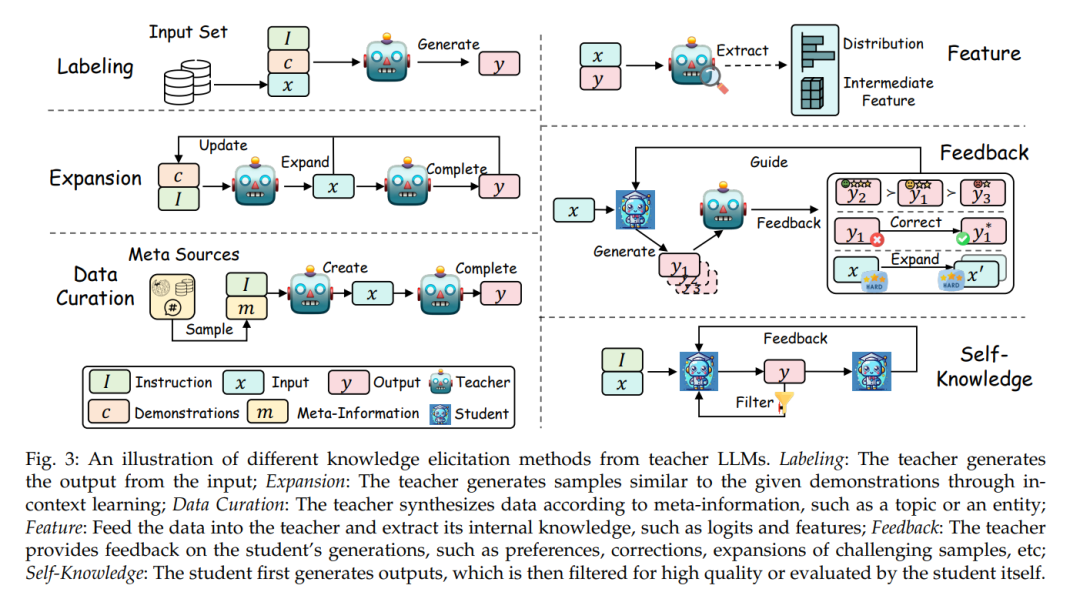
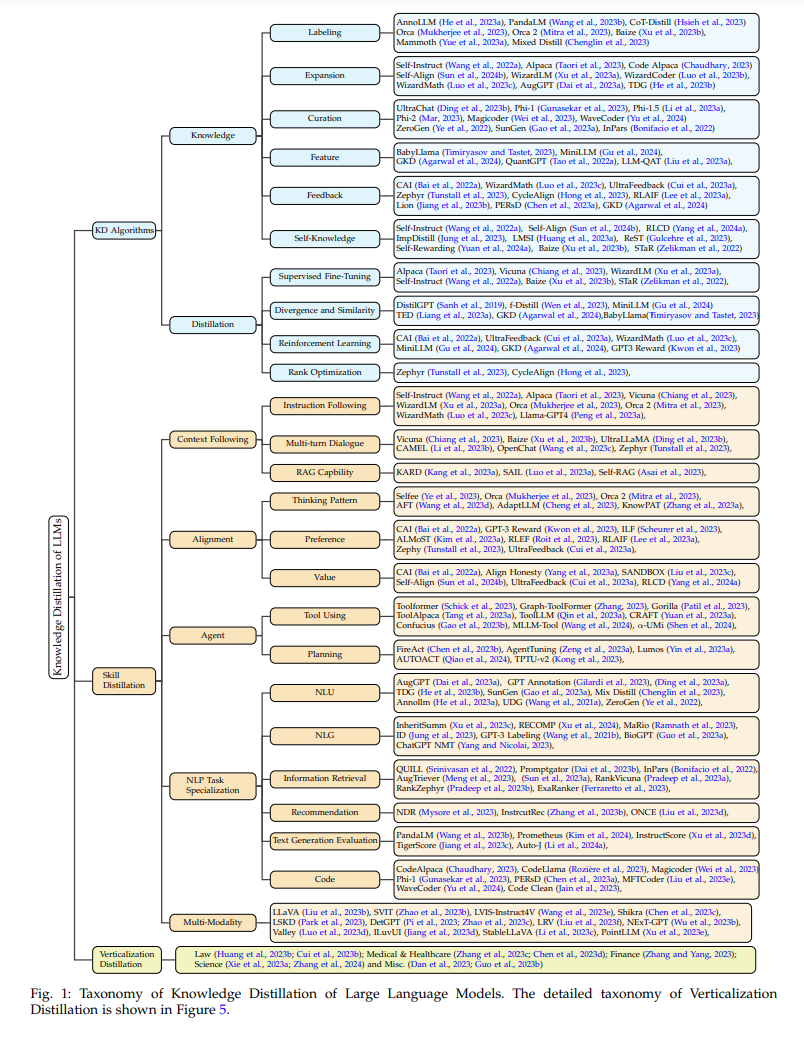
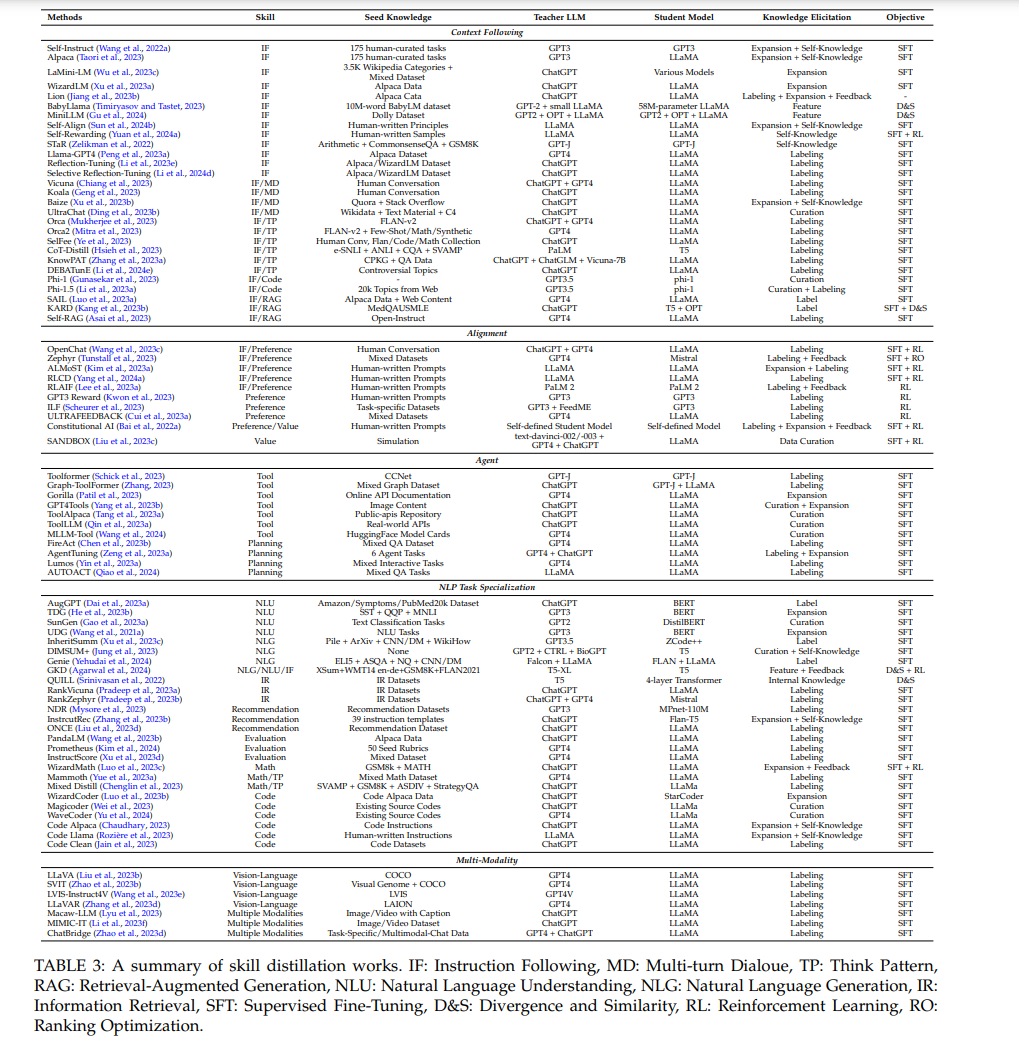
本节聚焦于有效地将从教师LLMs中引出的知识转移到学生模型中的方法论。我们探讨了一系列蒸馏技术,从通过监督微调增强模仿的策略,到差异与相似性,再到像强化学习和排名优化这样的高级方法,如图1所示。
技能蒸馏
在第3节关于引出知识和蒸馏算法的基础上,我们将关注转向这些技术如何促进LLMs中特定技能的蒸馏。我们的探索将包括LLMs展示的多种技能,包括上下文跟随、对齐、代理、NLP任务专业化和多模态性。上下文跟随侧重于学生模型理解和有效响应输入信息的能力。对齐深入探讨学生模型将其输出与教师响应对齐的能力。接下来,代理强调语言模型的自主性。NLP任务专业化突出了LLM在各种自然语言处理任务中专业化的多样性,展示了其适应性。最后,多模态性包括从教师LLMs到多模态模型的知识转移。
结论与讨论
本综述遍历了应用于LLMs的知识蒸馏的广阔领域,揭示了这一充满活力领域中众多技术、应用和新兴挑战。我们强调了KD在民主化获取专有LLMs的先进能力方面的关键作用,从而促进了更公平的AI景观。通过细致的审查,我们突出了KD如何作为一座桥梁,使资源有限的实体能够从LLMs的深远进步中受益,而无需承担训练和部署最先进模型所关联的禁止性成本。
我们的探索勾勒出了KD的多方面方法,包括算法创新、技能增强到特定领域的蒸馏。每个部分都揭示了在定制蒸馏模型以模仿其更加笨重对手的精密理解和功能时所固有的微妙复杂性和潜力。值得注意的是,数据增强策略在KD过程中的整合,作为提高这一LLM时代蒸馏效果的关键杠杆,强调了生成丰富上下文训练数据与蒸馏努力之间的协同潜力。
展望未来,几条研究途径呼之欲出。AI的不断演变,特别是在模型架构和训练方法论的迅速进步,为知识蒸馏提出了挑战与机遇。追求更高效、透明和伦理的AI模型,需要在知识蒸馏技术上不断创新,特别是那些能够在模型忠实度、计算效率和伦理考虑之间细致平衡的技术。此外,探索知识蒸馏在诸如弱到强泛化、自我对齐、多模态LLMs、实时适应和个性化AI服务等新兴领域的应用,承诺将扩展蒸馏模型可以实现的视野。 因此,LLMs的知识蒸馏处于一个关键时刻,具有显著影响AI发展和应用轨迹的潜力。正如本综述所阐明的,研究社区在推动知识蒸馏边界的共同努力,将在实现所有人都能访问的、高效的、负责任的AI的愿景中起到关键作用。