
北京时间 9 月 13 日午夜,OpenAI 发布 o1 系列模型,旨在专门解决难题。OpenAI o1 在数学、 代码、长程规划等问题上取得了显著提升,而背后的成功最重要离不开后训练阶段 (Post-Training Stage) 中强化学习训练和推理阶段思考计算量的增大。新的扩展律 —— 后训练扩展律(Post-Training Scaling Laws) 已经出现,并可能引发社区对于算力分配、后训练能力的重新思考。
技术原理:
大规模强化学习算法 OpenAI 使用了一种大规模的强化学习算法,来训练 o1-preview 模型。该算法通过高效的数据训练,让模型学会如何利用“思维链”(Chain of Thought)来生产性地思考问题。模型在训练过程中会通过强化学习不断优化其思维链,最终提升解决问题的能力。 OpenAI 发现,o1 模型的性能会随着强化学习时间(训练时计算量)和推理时间(测试时计算量)的增加而显著提高。这种基于推理的训练方式与传统的大规模语言模型(LLM)预训练方式不同,具有独特的扩展性优势。
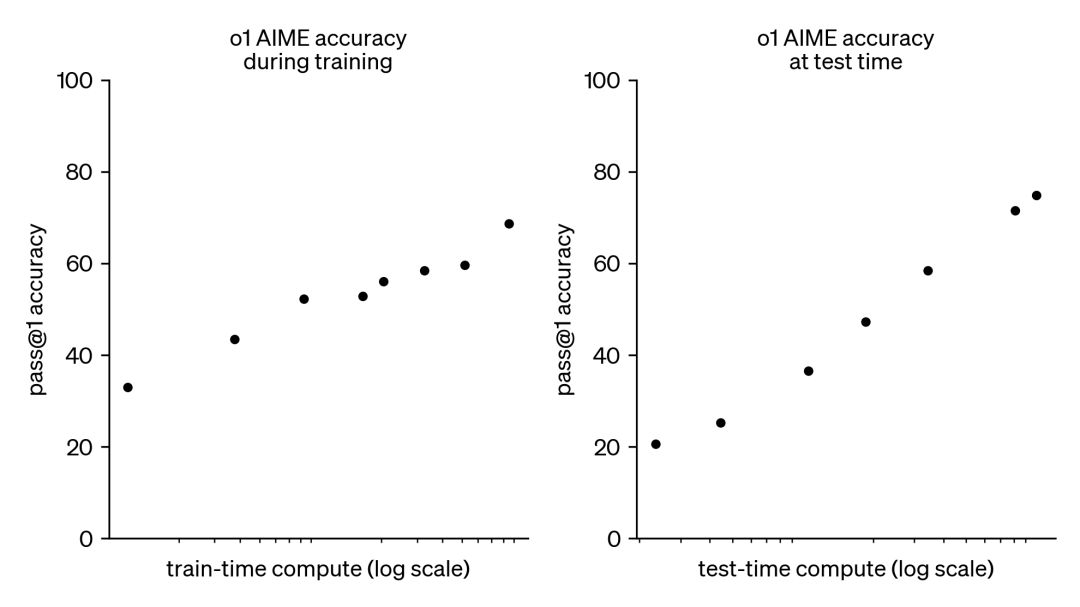
o1 性能在训练时间和测试时间的计算中都平稳提升思维链(Chain of Thought) o1-preview 模型通过 思维链推理 显著增强了其在复杂推理任务中的能力。思维链的基本理念类似于人类思考困难问题的过程:逐步分解问题、尝试不同策略并纠正错误。通过强化学习训练,o1-preview 能够在回答问题前进行深入思考,逐步细化步骤。 这种推理方式大幅提升了 o1-preview 在复杂任务中的表现。例如,o1-preview 能够通过思维链识别问题中的关键步骤并逐步解决。这种推理模式特别适用于需要多步骤推理的任务,如复杂的数学问题或高难度编程任务。 举例说明: * 在某些复杂问题上,o1-preview 能够逐步打破问题的难点,最终找到正确解答。这与人类面对挑战性问题时逐步分析的思维方式非常相似。
中文版:



