12 月 6 日,谷歌 CEO 桑达尔・皮查伊官宣 Gemini 1.0 版正式上线。这次发布的 Gemini 大模型是原生多模态大模型,是谷歌大模型新时代的第一步,它包括三种量级:能力最强的 Gemini Ultra,适用于多任务的 Gemini Pro 以及适用于特定任务和端侧的 Gemini Nano。

现在,谷歌的类 ChatGPT 应用 Bard 已经升级到了 Gemini Pro 版本,实现了更为高级的推理、规划、理解等能力,同时继续保持免费。谷歌预计在明年初将推出「Bard Advanced」,其将使用 Gemini Ultra。

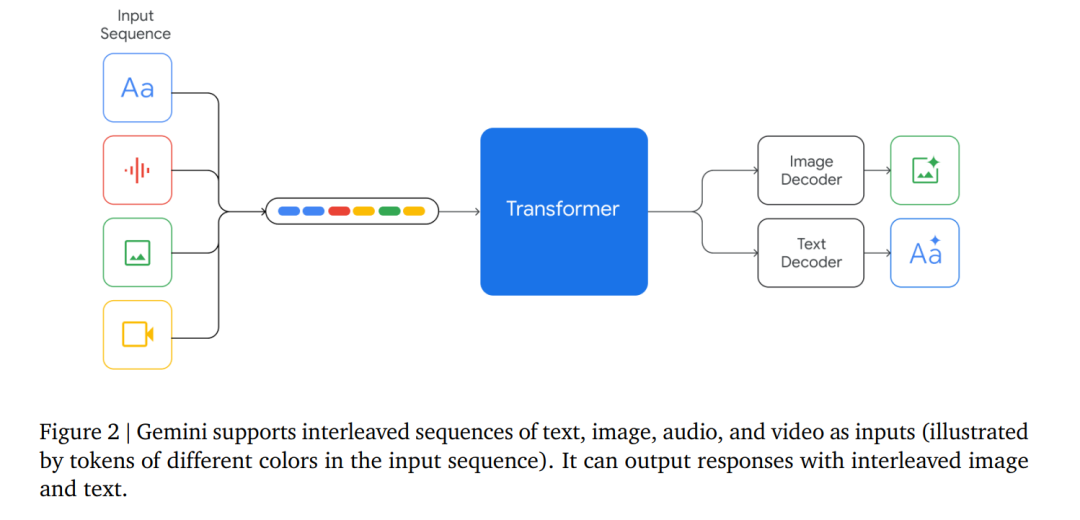
谷歌 DeepMind CEO 和联合创始人 Demis Hassabis 代表 Gemini 团队正式推出了大模型 Gemini。 Hassabis 表示长久以来,谷歌一直想要建立新一代的 AI 大模型。在他看来,AI 带给人们的不再只是智能软件,而是更有用、更直观的专家助手或助理。 今天,谷歌大模型 Gemini 终于亮相了,成为其有史以来打造的最强大、最通用的模型。Gemini 是谷歌各个团队大规模合作的成果,包括谷歌研究院的研究者。 特别值得关注的是,Gemini 是一个多模态大模型,意味着它可以泛化并无缝地理解、操作和组合不同类型的信息,包括文本、代码、音频、图像和视频。 谷歌表示,Gemini 还是他们迄今为止最灵活的模型,能够高效地运行在数据中心和移动设备等多类型平台上。Gemini 提供的 SOTA 能力将显著增强开发人员和企业客户构建和扩展 AI 的方式。

目前,Gemini 1.0 提供了三个不同的尺寸版本,分别如下:
- Gemini Ultra:规模最大、能力最强,用于处理高度复杂的任务;
- Gemini Pro:在各种任务上扩展的最佳模型;
- Gemini Nano:用于端侧(on-device)任务的最高效模型。
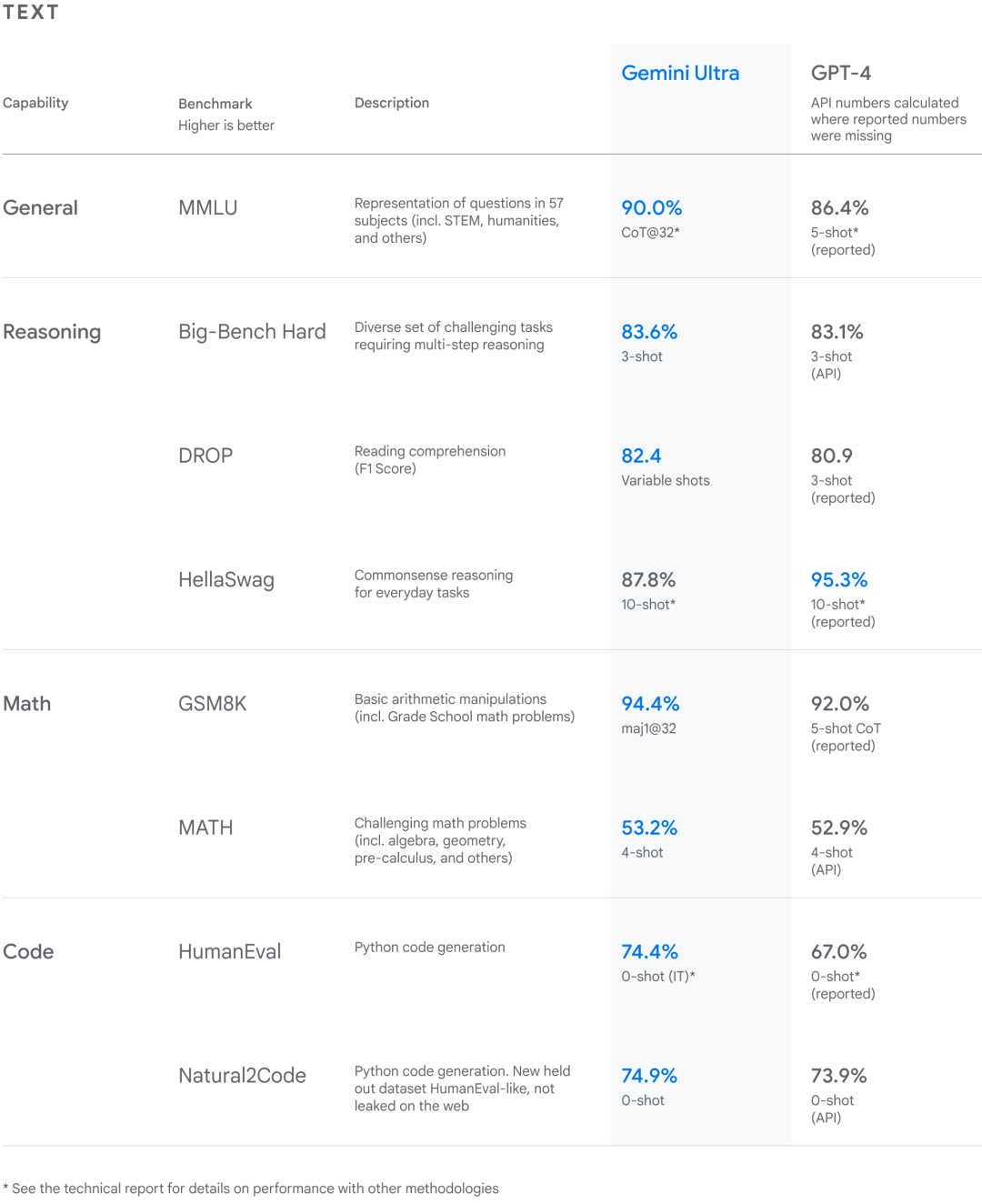
谷歌对 Gemini 模型进行了严格的测试,并评估了它们在各种任务中的表现。从自然图像、音频和视频理解,到数学推理等任务,Gemini Ultra 在大型语言模型研发被广泛使用的 32 个学术基准测试集中,在其中 30 个测试集的性能超过当前 SOTA 结果。 另外,Gemini Ultra 在 MMLU(大规模多任务语言理解数据集)中的得分率高达 90.0%,首次超越了人类专家。MMLU 数据集包含数学、物理、历史、法律、医学和伦理等 57 个科目,用于测试大模型的知识储备和解决问题能力。 针对 MMLU 测试集的新方法使得 Gemini 能够在回答难题之前利用其推理能力进行更仔细的思考,相比仅仅根据问题的第一印象作答,Gemini 的表现有显著改进。 在大多数基准测试中,Gemini 的性能都超越了 GPT-4。
**Gemini 高性能多模态大模型Gemini: A Family of Highly Capable Multimodal Models


这份报告介绍了一种新的多模态模型系列——Gemini,它在图像、音频、视频和文本理解方面展现出非凡的能力。Gemini系列包括Ultra、Pro和Nano三种尺寸,适用于从复杂推理任务到设备内存受限用例的各种应用。在一系列广泛的基准测试中的评估显示,我们最强大的Gemini Ultra模型在这些基准测试的32项中的30项中推进了最新技术水平——特别是它是首个在广受研究的考试基准MMLU上达到人类专家表现的模型,并且在我们检查的所有20项多模态基准测试中提升了最新技术水平。我们相信,Gemini模型在跨模态推理和语言理解方面的新能力将使各种用例成为可能,我们讨论了将它们负责任地部署给用户的方法。

我们在Google开发了一系列高性能的多模态模型——Gemini。我们对Gemini进行了联合训练,覆盖图像、音频、视频和文本数据,旨在构建一个在多种模态上都具有强大的通才能力,并在各自领域内具有先进的理解和推理性能的模型。 Gemini 1.0,我们的首个版本,有三种尺寸:Ultra用于高度复杂的任务,Pro用于提升性能和大规模部署能力,Nano用于设备上的应用。每种尺寸都专门针对不同的计算限制和应用需求进行了优化。我们在一系列内部和外部基准测试上评估了Gemini模型的性能,涵盖了广泛的语言、编程、推理和多模态任务。 Gemini在大规模语言建模(Anil等,2023;Brown等,2020;Chowdhery等,2023;Hoffmann等,2022;OpenAI,2023a;Radford等,2019;Rae等,2021)、图像理解(Alayrac等,2022;Chen等,2022;Dosovitskiy等,2020;OpenAI,2023b;Reed等,2022;Yu等,2022a)、音频处理(Radford等,2023;Zhang等,2023)和视频理解(Alayrac等,2022;Chen等,2023)方面推进了最新技术。它还基于序列模型(Sutskever等,2014)、深度学习基于神经网络的长期研究(LeCun等,2015),以及机器学习分布式系统(Barham等,2022;Bradbury等,2018;Dean等,2012)来实现大规模训练。 我们最强大的模型,Gemini Ultra,在我们报告的32个基准测试中的30个中取得了新的最新技术成果,包括12个流行的文本和推理基准测试中的10个,9个图像理解基准测试中的9个,6个视频理解基准测试中的6个,以及5个语音识别和语音翻译基准测试中的5个。Gemini Ultra是首个在MMLU(Hendrycks等,2021a)上达到人类专家表现的模型——一个通过一系列考试测试知识和推理的著名基准测试——得分超过90%。除了文本,Gemini Ultra在挑战性的多模态推理任务上也取得了显著进展。例如,在最近的MMMU基准测试(Yue等,2023)上,该测试包含了关于图像的多学科任务,需要大学级别的主题知识和深思熟虑的推理,Gemini Ultra取得了62.4%的新最新技术成绩,比之前最好的模型高出5个百分点以上。它为视频问答和音频理解基准测试提供了统一的性能提升。 定性评估展示了令人印象深刻的跨模态推理能力,使模型能够本地地理解和推理音频、图像和文本输入序列(见图5和表13)。以图1中描绘的教育场景为例。一位老师画了一个滑雪者下坡的物理问题,一位学生对其进行了解答。使用Gemini的多模态推理能力,模型能够理解凌乱的手写字,正确理解问题的构成,将问题和解决方案转换为数学排版,识别学生在解决问题时出错的具体推理步骤,然后给出问题的正确解决方案。这为教育领域开辟了激动人心的可能性,我们相信Gemini模型的新多模态和推理能力在许多领域都有重大应用。大型语言模型的推理能力展示了构建能够解决更复杂多步骤问题的通才型代理的前景。AlphaCode团队构建了AlphaCode 2(Leblond等,2023),一种新的由Gemini驱动的代理,它结合了Gemini的推理能力、搜索和工具使用,擅长解决竞赛编程问题。AlphaCode 2在Codeforces竞赛编程平台上排名前15%,比其最先进的前辈排名前50%有了大幅提升(Li等,2022)。 与此同时,我们通过Gemini Nano推进了效率的前沿,这是一系列针对设备上部署的小型模型。这些模型擅长于设备上的任务,如摘要、阅读理解、文本完成任务,并在推理、STEM、编码、多模态和多语言任务方面相对于它们的大小展示了令人印象深刻的能力。 在接下来的部分,我们首先提供模型架构、训练基础设施和训练数据集的概述。然后,我们详细评估了Gemini模型系列,涵盖了广泛研究的基准测试和跨文本、代码、图像、音频和视频的人类偏好评估——包括英语性能和多语言能力。我们还讨论了负责任部署的方法,包括我们对影响评估的过程、开发模型政策、评估和在部署决策前减少伤害的方法。最后,我们讨论了Gemini的更广泛影响,它的局限性以及其潜在应用——为AI研究和创新的新时代铺平道路。