

现代人工智能(AI)系统由基础模型驱动。本文介绍了一套新的基础模型,称为Llama 3。它是一群本地支持多语言、编码、推理和工具使用的语言模型。我们最大的模型是一个具有4050亿参数和高达128K令牌上下文窗口的密集Transformer。本文对Llama 3进行了广泛的实证评估。我们发现Llama 3在众多任务上提供了与GPT-4等领先语言模型相当的质量。我们公开发布了Llama 3,包括4050亿参数语言模型的预训练和后训练版本,以及我们的Llama Guard 3模型,用于输入和输出安全。本文还介绍了我们通过组合方法将图像、视频和语音能力集成到Llama 3中的实验结果。我们观察到这种方法在图像、视频和语音识别任务上与最先进的技术竞争。生成的模型尚未广泛发布,因为它们仍在开发中。
1 引言
基础模型是为语言、视觉、语音和/或其他模态设计的通用模型,旨在支持大量AI任务。它们构成了许多现代AI系统的基础。 现代基础模型的发展包括两个主要阶段:(1) 预训练阶段,在这个阶段,模型使用简单的任务(如下一个词预测或字幕生成)进行大规模训练;(2) 后训练阶段,在这个阶段,模型被调整以遵循指令、与人类偏好对齐,并提高特定能力(例如,编码和推理)。
在本文中,我们介绍了一套新的语言基础模型,称为Llama 3。Llama 3模型群原生的支持多语言、编码、推理和工具使用。我们最大的模型是一个具有4050亿参数的密集Transformer,能够在高达128K令牌的上下文中处理信息。表1列出了每个模型成员。本文中呈现的所有结果都是针对Llama 3.1模型的,为了简洁,我们将在全文中称之为Llama 3。

表1 Llama 3模型群的概览。本文中的所有结果都是针对Llama 3.1模型的。 我们相信,在开发高质量的基础模型方面有三个关键的杠杆:数据、规模和管理复杂性。我们在开发过程中寻求优化这三个杠杆:
数据。与Llama的早期版本(Touvron等人,2023a,b)相比,我们改进了用于预训练和后训练的数据量和质量。这些改进包括开发更谨慎的预训练数据处理和策划流程,以及为后训练数据开发更严格的质量保证和过滤方法。我们对Llama 3进行了大约15T多语言令牌的预训练,而Llama 2是1.8T令牌。
规模。我们训练的模型规模远远大于以前的Llama模型:我们的旗舰语言模型使用了3.8×10253.8×1025次浮点运算进行预训练,比Llama 2的最大版本多近50倍。具体来说,我们在15.6T文本令牌上预训练了一个具有4050亿可训练参数的旗舰模型。根据基础模型的规模法则,我们的旗舰模型的表现超过了使用相同过程训练的较小模型。虽然我们的规模法则表明,我们的旗舰模型对于我们的训练预算来说是近似计算最优的大小,我们还训练了更小的模型,比计算最优的时间长得多。产生的模型在相同的推理预算下比计算最优模型表现更好。我们使用旗舰模型在后训练期间进一步提高这些较小模型的质量。
管理复杂性。我们做出设计选择,力求最大化我们扩展模型开发过程的能力。例如,我们选择标准的密集Transformer模型架构(Vaswani等人,2017)进行小幅度调整,而不是选择专家混合模型(Shazeer等人,2017)以最大化训练稳定性。同样,我们采用了相对简单的后训练程序,基于监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO;Rafailov等人(2023)),而不是更复杂的强化学习算法(Ouyang等人,2022;Schulman等人,2017),这些算法往往不太稳定,更难扩展。
我们的工作成果是Llama 3:一个包含8B、70B和405B参数的三种多语言的语言模型的群体。我们在涵盖广泛语言理解任务的众多基准数据集上评估了Llama 3的性能。此外,我们进行了广泛的人类评估,将Llama 3与竞争模型进行了比较。表2展示了旗舰Llama 3模型在关键基准测试中的表现概览。我们的实验评估表明,我们的旗舰模型在各种任务上的表现与GPT-4(OpenAI,2023a)等领先的语言模型相当,并且接近于达到最先进的水平。我们的较小模型是同类中最好的,超过了参数数量相似的替代模型(Bai等人,2023;Jiang等人,2023)。Llama 3还在有益性和无害性之间提供了比其前身(Touvron等人,2023b)更好的平衡。我们在第5.4节中对Llama 3的安全性进行了详细分析。
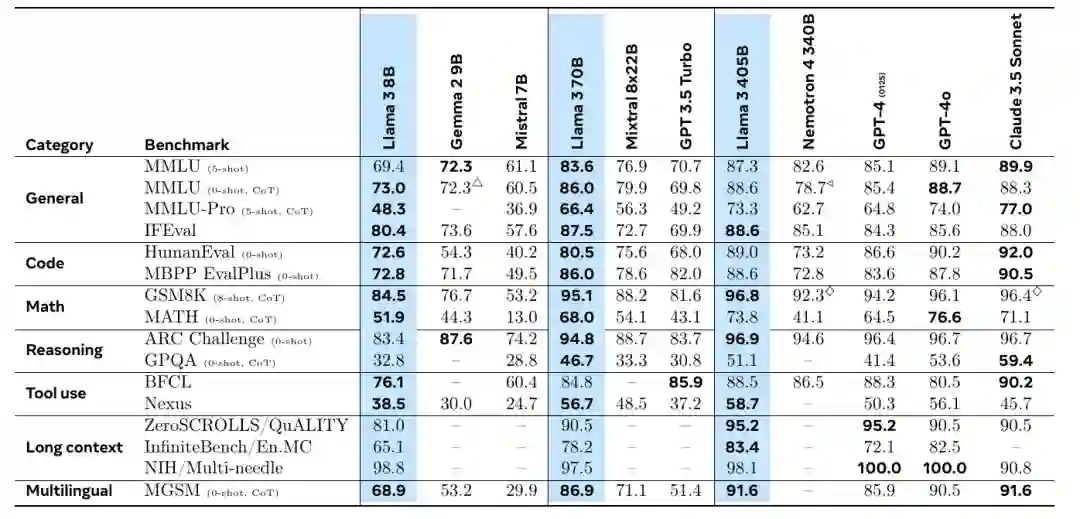
表2 在关键基准评估中微调后的Llama 3模型的性能。该表比较了8B、70B和405B版本的Llama 3与竞争模型的性能。我们在三种模型尺寸等级中,每个等级中表现最佳模型的结果用粗体表示。△表示使用5次提示(无CoT)获得的结果。◁表示未使用CoT获得的结果。ᛜ表示使用零次提示获得的结果。
我们正在根据Llama 3社区许可证的更新版本公开发布所有三个Llama 3模型;请参见 https://llama.meta.com。这包括我们的405B参数语言模型的预训练和后训练版本,以及我们的Llama Guard模型(Inan等人,2023)的新版本,用于输入和输出安全。我们希望旗舰模型的开放发布将激发研究社区的一波创新,并加速朝着负责任的人工通用智能(AGI)发展道路前进。 作为Llama 3开发过程的一部分,我们还开发了模型的多模态扩展,使其具备图像识别、视频识别和语音理解能力。这些模型仍在积极开发中,尚未准备好发布。除了我们的语言建模结果外,本文还展示了我们对这些多模态模型进行的初步实验的结果。




