【NAACL 2018】Self-attention考虑相对位置,谷歌Vaswani团队最新工作
【导读】谷歌Vaswani团队最新工作,在Transformer的基础上利用相对位置或者序列元素之间的距离对self-attention进行扩展,既能有效提高翻译质量,又能提高效率。
【NAACL 2018论文】
Self-Attention with Relative Position Representations

论文链接:https://arxiv.org/abs/1803.02155
摘要
Vaswani等人在2017年介绍了一个完全依靠注意力机制的序列表示方法——Transformer,取得目前最好的机器翻译成绩。与递归神经网络和卷积神经网络相比,它没有在网络结构中显示地建模相对或绝对位置信息。相反,它需要在输入中添加绝对位置的表示。在这项工作中作者提出了另一种方法,将自注意力机制扩展到有效地考虑相对位置的表示,或序列元素之间的距离。在WMT2014从英语到德语和从英语到法语的翻译任务中,本文方法相比绝对位置表示分别提高了1.3 BLEU 和0.3 BLEU。值得注意的是,作者观察到将相对位置和绝对位置表示结合在一起,并不会进一步改进翻译质量。作者描述了本文方法的一个有效实现,并将其转换为一个关系感知的自注意力机制(relation-aware self-attention mechanisms)的实例,该机制可以推广到任意图形标记输入(graph labeled inputs)。
前言
目前sequence to sequence 学习的方法主要利用递归,卷积,attention,或者结合递归和attention。这些方法以不同的方式合并有关元素顺序位置的信息。递归神经网络(RNNs)通常计算隐藏状态ht,作为它们在时间t时的输入和先前的隐状态ht−1的函数,通过时序结构直接捕获时间维度上的相对位置和绝对位置。非递归模型不一定按顺序考虑输入元素,因此可能需要显式编码位置信息才能使用序列顺序。
一种常见的方法是使用与输入元素相结合的位置编码来向模型提供位置信息。这些位置编码可以是位置的确定性函数或学习表示。卷积神经网络本质上捕获每个卷积核大小内的相对位置。然而,它们仍然从位置编码中受益。
对于既不使用卷积也不使用递归的Transformer来说,引入位置信息的显式表示是一个特别重要的考虑因素,因为该模型在其他方面完全不受序列顺序的影响。因此,基于注意力的模型使用了基于距离的位置编码或偏置注意权重(biased attention weights)。
在本文中,作者提出了一种将相对位置表示引入Transformer自注意力机制的有效方法,即使完全取代其绝对位置编码,在两种机器翻译任务中,翻译质量也有了显著的提高。
作者的方法可以作为一种特例,将Transformer的自注意力机制扩展到考虑输入的任意两个元素之间的任意关系,这是作者计划在今后的标有向图建模工作中探索的方向。
背景知识
1. Transformer
Transformer采用由堆叠编码器和解码器层组成的编码器-解码器结构。编码器层由两个子层组成:self-attention层,然后是一个位置感知的前馈层。解码器层由三个子层组成:self-attention,然后是编码器-解码器attention,然后是一个位置感知的前馈层。它使用每个子层周围的残差连接,然后再进行层归一化。解码器在其self-attention中使用掩码以防止给定的输出位置在训练期间包含关于未来输出位置的信息。
在第一层之前,在编码器和解码器输入元件中添加基于频率变化的正弦信号的位置编码。与学习的绝对位置表示相比,作者假设正弦波位置编码将帮助模型推广到训练过程中未见的序列长度,使它能够学习参加相对位置,这一性质是由作者的相对位置表示所共有的,与绝对位置表示相比,相对位置表示与总序列长度是不一致的。
残差连接有助于将位置信息传播到更高的层。
2. Self-Attention
自注意力层采用h attention heads。为了形成子层输出,每个head的结果被连在一起,并应用参数化线性变换。每个attention heads在n个元素的输入序列x=(x1;…;xn)上操作,并计算新序列z=(z1;…;zn),其长度与x相同。
每个输出元素zi被计算为线性变换输入元素的加权和:
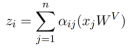
每个权重系数αij,使用一个Softmax函数计算:
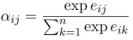
而eij是使用比较两个输入元素的兼容性函数计算的:
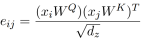
为兼容性函数选择了缩放的点积,这使其能够进行有效的计算。输入的线性变换增加了足够的表现力。
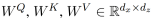
算法结构
1. 位置感知的Self-Attention
作者提出了一个自注意力的扩展,考虑输入元素之间的成对关系。在这个意义上,作者将输入建模为标记的、有向的、完全连通的图。
输入元素xi,xj之间的边由a_ij^V 和a_ij^K 表示,学习两种不同的边缘表示的动机是a_ij^V 和a_ij^K分别适合方程3和4使用。不需要额外的线性变换。这些表示可以在attention head之间共享。
作者修改公式(1)将边缘信息传播到子层输出:
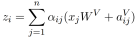
如果任务中由给定的attention head选择的边缘类型的信息对下游编码器或解码器层很有用,则这种扩展可能很重要。然而,这对于机器翻译来说可能并不是必需的。
重要的是,作者还修改了公式(2),在确定compatibility时考虑了边:
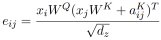
使用简单加法将边表示合并到等式(3)和(4)中的主要动机是为了使实现更有效。
2. 相对位置表示
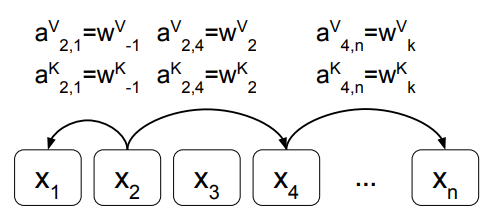
图:示例边表示相对位置,或元素之间的距离。作者学习了在一个裁剪距离K内的每个相对位置的表示。这个图假设2<=k<=n−4。注意不是所有的边都显示出来了。
对于线性序列,边可以捕捉输入元素之间相对位置差异的信息,作者考虑的最大相对位置被剪裁到一个最大绝对值k。作者假设精确的相对位置信息在一定距离之外是不有用的。修剪最大距离还使模型能够推广到训练期间未观察到的序列长度。因此,作者考虑2k+1唯一的边缘标签。
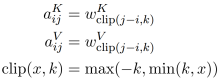
然后作者学习相对位置表示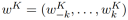
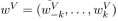
3. 有效实现
对于长度为n的,有h个attention heads的序列,通过在每个head上共享相对位置表示,作者将存储相对位置表示的空间复杂度从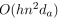
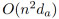
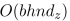
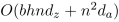
当作者考虑相对位置时,表示因位置pair的不同而不同。这使得作者无法计算单个矩阵乘积中所有位置pair的所有eij。作者也希望避免广播相对位置表示。然而,这两个问题都可以通过将方程的计算分开来解决。方程(4)分为两项:
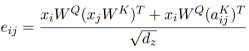
实验
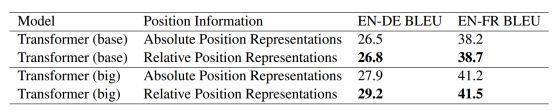
表1:WMT2014从英语到德语和从英语到法语的翻译任务的结果
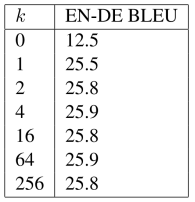
表2:改变裁剪距离k的实验结果
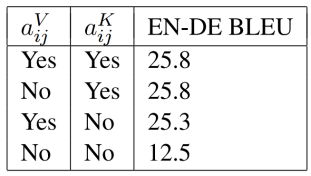
表3:去掉相对位置表示的实验结果
结论
本文提出了一种对自注意力的扩展,它可以用于包含序列的相对位置信息,从而提高了机器翻译的性能。在今后的工作中,作者计划将这种机制扩展为考虑任意有向、有标记的图输入到Transformer。作者还感兴趣的是将输入表示和边缘表示结合在一起的非线性兼容性函数。对于这两个扩展,一个关键的考虑因素将是高效实现。
原文链接:
https://arxiv.org/pdf/1803.02155.pdf
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知





