【导读】如何有效管控新冠,疫情预测是个关键的问题。美国佐治亚理工**“以数据为中心”的解决方案,这些解决方案显示出了利用非传统数据源以及人工智能和机器学习方面的最新创新来提高我们的预测能力的潜力。这项综述深入研究了各种数据驱动的方法和实际进展,并介绍了一个概念框架来阐述。**

2019冠状病毒病(COVID-19,即2019冠状病毒病)疫情大流行使得从公共卫生到整个经济的多个领域的决策者都必须进行疫情预测。虽然预测疫情发展在概念上常常与天气预报类似,但它有一些关键的区别,仍然是一项艰巨的任务。疾病的传播受到多种混杂因素的影响,包括人类行为、病原体动态、天气和环境条件。越来越多的丰富的数据来源捕捉了以前无法观察到的方面,也得益于政府公共卫生和资助机构的举措,如预测挑战和大规模团队科学举措,研究兴趣得到了激发。特别是,这导致了一系列“以数据为中心”的解决方案,这些解决方案显示出了利用非传统数据源以及人工智能和机器学习方面的最新创新来提高我们的预测能力的潜力。这项综述深入研究了各种数据驱动的方法和实际进展,并介绍了一个概念框架来阐述。首先,我们列举了大量与流行病预测相关的流行病学数据集和新颖的数据流,捕捉了各种因素,如症状在线调查、零售和商业、流动性、基因组数据等。接下来,我们讨论了方法和建模范式,重点关注最近的数据驱动的统计方法和基于深度学习的方法,以及将机械模型的领域知识与统计方法的有效性和灵活性相结合的新型混合模型。我们还讨论了这些预测系统在实际应用中出现的经验和挑战,包括根据预测做出决策。最后,我们强调了在预测过程中发现的一些挑战和开放性问题。



图1: 以数据为中心的流行病预测流程概述。(A)在建模之前,我们需要准备数据,包括收集和探索性分析,以处理数据质量问题。在这个阶段,我们还确定了流行病的目标和任务。(B)模型的制定考虑到流行病传播的多个方面(例如,多尺度动力学)和预测的利用(例如,不确定性量化)。验证和模型选择需要使用定量指标来评估预测的可操作性和可靠性。(C)实时预测有多种用途,包括仪表板、集成组成和其他公共卫生举措。这些活动为资源分配、个人风险评估和公众沟通提供决策平台。
2019冠状病毒病大流行对人类生活、经济发展和整个社会造成的毁灭性影响,突显了我们在重大传染病和流行病面前的脆弱性。虽然流行病预测科学在许多方面仍处于初级阶段,但当前的流行病以及之前的流行病(如H1N1和埃博拉)已经显示出其至关重要的意义。预防和应对此类流行病需要可操作的流行病预测,例如设计有效的医疗文件策略和最优的供应链决策。然而,产生这样的预测有多个跨学科的挑战。这些研究包括了解控制病原体进化的生物过程、免疫反应和耐药性,以及异质性群体及其在群落内和跨群落之间的相互作用的种群水平模型。
在过去几年政府公共卫生和资助机构的几项举措的基础上,人们对以数据为中心的流行病预测解决方案越来越感兴趣[197]。例如,2013年,美国疾病控制和预防中心(CDC)引入了“FluSight”挑战[40],这不仅帮助提高了流感预测能力和公共卫生决策,还帮助发展了这一主题的研究人员社区。随后,由欧洲疾病预防控制中心(CDC)[49,152]、IARPA[2]和拉丁美洲PAHO[210]等全球机构领导的针对埃博拉[338]、登革热[158]和COVID-19[77]的类似行动也开始了。这些预测活动为研究人员提供了一个前所未有的机会,来观察当前预测科学的成功和差距。同样,国家科学基金会(NSF)、国家卫生研究院(NIH)和美国陆军研究等机构最近举行了一系列与大流行预测相关的座谈会[117]和筹资呼吁,这为这一主题提供了急需的动力。美国疾病控制与预防中心于2021年建立了第一个预测和爆发分析中心,这也使这种兴趣达到了顶峰[104]。我们的调研深入研究了这种数据驱动的计算方法,这些方法在利用数据科学和人工智能的进步以及从生物到行为的新信息源的结合方面显示出了巨大的潜力。事实上,可靠来源的数据越来越多(其中一些是公开可获取的),而COVID-19大流行只会加速这一趋势。这包括更丰富的流行病学数据集和新的数字数据流,如流动性[10,349]、在线调研[75,270]和废水样本[247]。在这些因素的推动下,在过去两年中,我们还看到了一些使用机器学习和深度学习技术的技术创新,这些技术为流行病预测科学打开了新的视野。
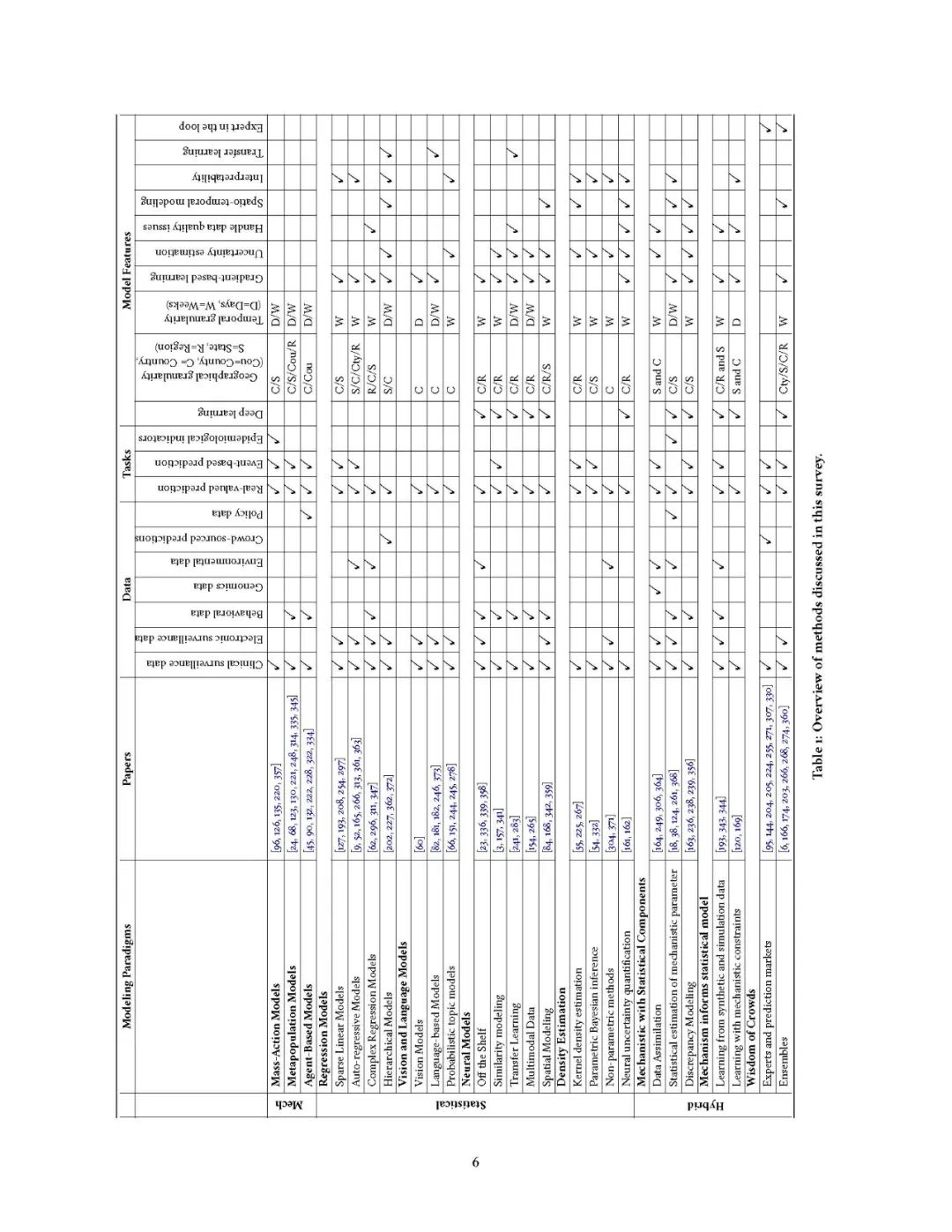
这项调研是在一个适当的时间包含最近的方法和实践进展,以帮助和使更广泛的计算和数据/ML/AI社区参与这一领域。我们可以将以数据为中心的计算流行病预测管道概念化,如图1所示。我们对这些组件进行了概述,并将它们大致分为三种:数据处理、模型训练和验证,以及利用和决策。广义上说,流行病预测的目的是提供关于以多种指标(例如每周到医院就诊的病人人数)衡量的流行病传播轨迹的信息。我们的渠道从来自不同来源和模式的数据开始,这些数据捕捉了流行病传播的多个方面。在准备数据并在空间和时间尺度上确定具体目标和解决办法之后,考虑到疾病传播的特征(例如,多尺度动力学)、数据考虑(例如,噪声数据)以及公共卫生官员和公众的要求(例如,不确定性量化),进行建模训练和部署。我们的调研收集了所有这些因素,并研究了每一个方面的最近发展和当前的重要趋势。在表1中,我们总结并分类了我们综述的方法论工作。我们强调每种建模范式使用的数据类型、它们所用于的任务以及独特的建模特性。
通常,早期的相关调查集中在传统的流行病学方法上,很少强调以数据为中心的观点,通常将调查范围限定在一种疾病上[73,229]。相比之下,虽然没有调研是完全详尽的,但我们提供了一个跨越多种建模方法的更广泛、更全面的视角。最近有一些调研讨论了AI/ML技术在流行病引起的各种医疗挑战中的使用/应用[65,310],这些调研主要集中在医学成像等临床问题上。相反,我们专注于流行病学预测,并提供了一个更广泛的框架来理解从传统机械方法到基于统计机器学习模型的建模范式。事实上,在这里,我们比以前的工作更深入,专注于范式,旨在通过利用两种方法(所谓的混合方法)的优势,弥合流行病学和ML社区之间的差距。我们还提供了一个全面的讨论与这些预测系统的实时部署相关的挑战和解决方案。我们在管道的多个阶段对它们进行研究,包括数据收集、建模、评估和决策。最后,对疫情预测领域的开放问题和研究方向进行了全面讨论。
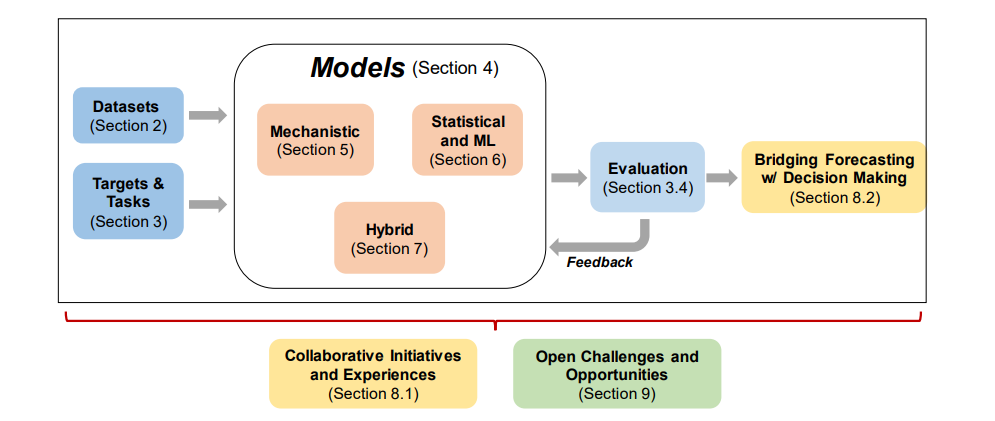
图2: 综述组织。第2节全面介绍了用于更好地为流行病预测提供信息的数据来源。在第3节中,我们描述了建模之前需要的其他元素,如预测目标和任务,以及通用的评估指标(第3.4节)。然后,我们将在第5、6和7节中讨论预测方法。在第8.2节中,我们回顾了近期在衔接预测和决策方面的工作。在第8节中,我们调研了利用这些模型的计划和经验,并讨论了实时部署的挑战。最后,在第9节中,我们讨论了主要的挑战和重要的开放研究问题的所有主题调查。
**该综述分为7个部分,**如图2所示。在第2节中,我们讨论用于流行病预测的传统和较新的数据来源。在第3节中,我们描述了预测设置,包括定义预测目标和具体任务。然后我们讨论常用的定量评估指标。然后,我们转向预测建模技术(第4节),我们将其分为机械的、统计的和混合的,并进一步根据它们的关键建模思想对它们进行分类。对于每一种建模技术,我们都将对一些突出的方法进行深入的回顾,从研究良好的机械模型(第5节)开始,然后转向统计模型(第6节),统计模型更灵活地利用大量多样的数据来源,从过去的数据中学习复杂的模式,通常提供更准确的预测。在这里,我们密切关注深度学习创新,这是一个非常活跃的研究领域,有多个最新的例子。在第7节中,我们将描述最近引起人们兴趣的混合模型,并将可解释的、基于理论的机械模型的长期建模能力与更灵活、准确和数据驱动的统计模型结合起来。在第8节中,我们调查了最近的“战壕”行动和利用这些模型进行流行病和大流行预测的经验,讨论了现实部署的挑战,包括根据预测做出决策。最后,在第9节中,我们讨论了与流行病预测管道的各个方面相关的主要挑战和重要的开放研究问题。