

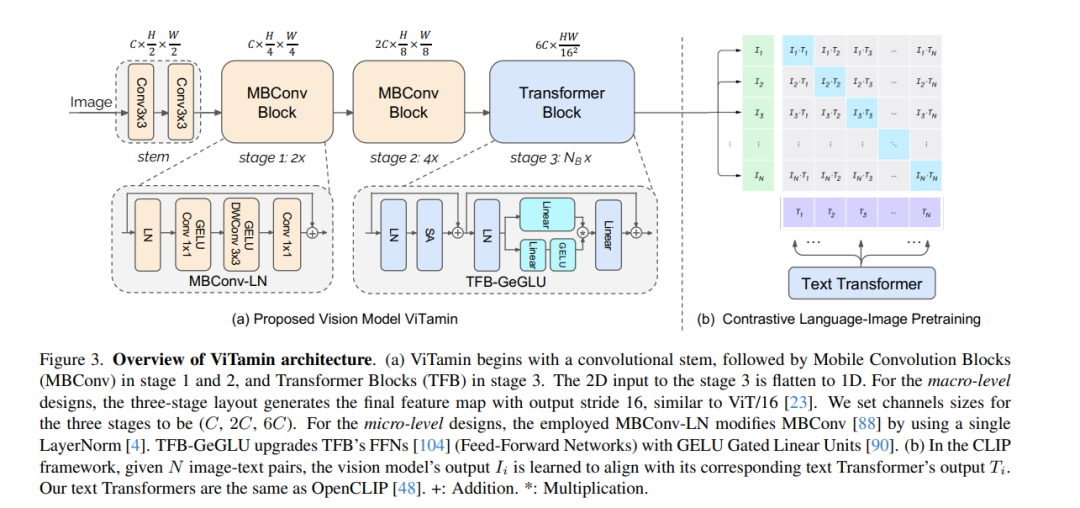
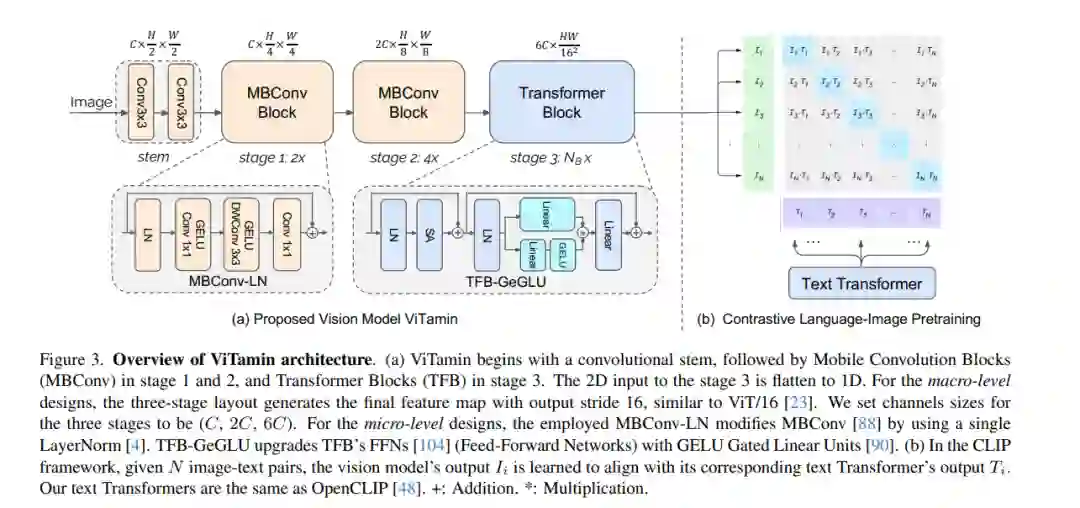
近期在视觉-语言模型(VLMs)方面的突破,为视觉领域翻开了新的一页。相比于从ImageNet预训练模型获得的特征嵌入,VLMs依托于大规模互联网图像-文本对的训练,提供了更强大、更具泛化能力的特征嵌入。然而,尽管VLMs取得了惊人的成就,但原始的视觉变换器(ViTs)仍然是图像编码器的默认选择。尽管纯变换器在文本编码领域证明了其有效性,但在图像编码方面是否同样有效仍有待商榷,特别是考虑到在ImageNet基准测试上提出了各种类型的网络,遗憾的是,这些网络在VLMs中很少被研究。由于数据/模型规模小,ImageNet上模型设计的原始结论可能是有限且偏颇的。在本文中,我们旨在建立一个在视觉-语言时代下,基于对比性语言-图像预训练(CLIP)框架的视觉模型评估协议。我们提供了一种全面的方式来基准测试不同的视觉模型,涵盖了它们的零样本性能和在模型及训练数据规模上的可扩展性。为此,我们引入了ViTamin,一种为VLMs量身定制的新视觉模型。ViTamin-L在使用相同的公开可用的DataComp-1B数据集和相同的OpenCLIP训练方案时,其ImageNet零样本准确率比ViT-L高出2.0%。ViTamin-L在60个多样化的基准测试中展现出了有希望的结果,包括分类、检索、开放词汇检测和分割,以及大型多模态模型。当进一步扩大模型规模时,我们的ViTamin-XL仅使用436M参数就达到了82.9%的ImageNet零样本准确率,超过了EVA-E以十倍参数量(4.4B)所实现的82.0%。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日