深度生成模型旨在复制给定的数据分布以产生新的样本,在近年来取得了前所未有的进步。他们的技术突破使得在视觉内容的合成上实现了无与伦比的质量。然而,他们巨大成功的一个关键先决条件是有足够数量的训练样本,这需要大量的计算资源。当在有限的数据上进行训练时,生成模型往往会因过度拟合和记忆化而导致严重的性能下降。
**因此,研究人员近来花费了大量的精力来开发能够从有限的训练数据生成合理且多样化图像的新型模型 **。尽管在有限数据情况下提高训练稳定性和合成质量的努力众多,但仍缺乏一个系统的调查,该调查提供1)清晰的问题定义、关键挑战和各种任务的分类;2)对现有文献的优点、缺点和剩余限制的深入分析;以及3)对有限数据下图像合成领域的潜在应用和未来方向的深入讨论。
为了填补这个空白,并为新入门这个主题的研究人员提供一个信息丰富的介绍,这个调查提供了一个全面的审查和一个关于有限数据下图像合成发展的新的分类。特别是,它全面而全方位地涵盖了问题的定义、要求、主要解决方案、流行的基准和剩余的挑战。我们希望这个调查能为研究人员和实践者提供一个信息丰富的概览和一个宝贵的资源,并推动这个重要主题的进一步进步和创新。除了相关的参考文献,我们的目标是不断维护一个最新的存储库,以在GitHub/awesome-few-shot-generation上追踪这个主题的最新进展。
1. 引言
深度生成模型已经取得了巨大的发展,并已经被应用于广泛的智能创造任务,特别是在图像和视频合成[1],[2],[3],[4],[5],[6],[7],[8],[9],音频和语音合成[10],[11],[12],[13],[14],[15],多模式生成[16],[17],[18]等方面。他们的技术突破也直接方便了我们日常生活的许多方面,包括各种表示形式(例如,3D/2D表示)的内容创建[19],[20],[21],[22],定制生成和编辑[23],[24],[25],[26],[27],以及艺术合成/操作[28],[29],[30],[31]。尽管取得了这些显著的进步,但大多数现有的生成模型需要大量的数据和计算资源进行训练。例如,最常用的数据集,人脸FFHQ [2],[32](70K),户外/室内场景LSUN [33](1M),和对象ImageNet [34](1M),都包含足够的训练样本。这样的先决条件对只有有限训练样本的实践者和研究者(如著名艺术家的绘画和稀有疾病的医疗图像)构成了重大挑战。因此,有越来越多的需求要在有限的训练数据下学习生成模型,这在近年来引起了广泛的关注。 在有限数据下进行图像合成的主要挑战是模型过拟合和记忆化的风险,这可以显著影响生成样本的真实度和多样性[35],[36],[37],[38],[39]。也就是说,由于过度拟合,模型可能只是复制训练图像,而不是生成新的图像,从而导致合成质量下降。例如,当在有限数据下训练生成对抗网络(GANs)[40]时,判别器容易记住训练图像,从而对生成器提供无意义的指导,导致不利的合成。为了解决这些限制,许多研究工作已经开发出来,以改善在少数情况下的合成质量[35],[36],[37],[41],[42]。这些工作提出了各种策略,从不同的角度来减轻过拟合和记忆化的风险,如数据增强、正则化和新的架构。
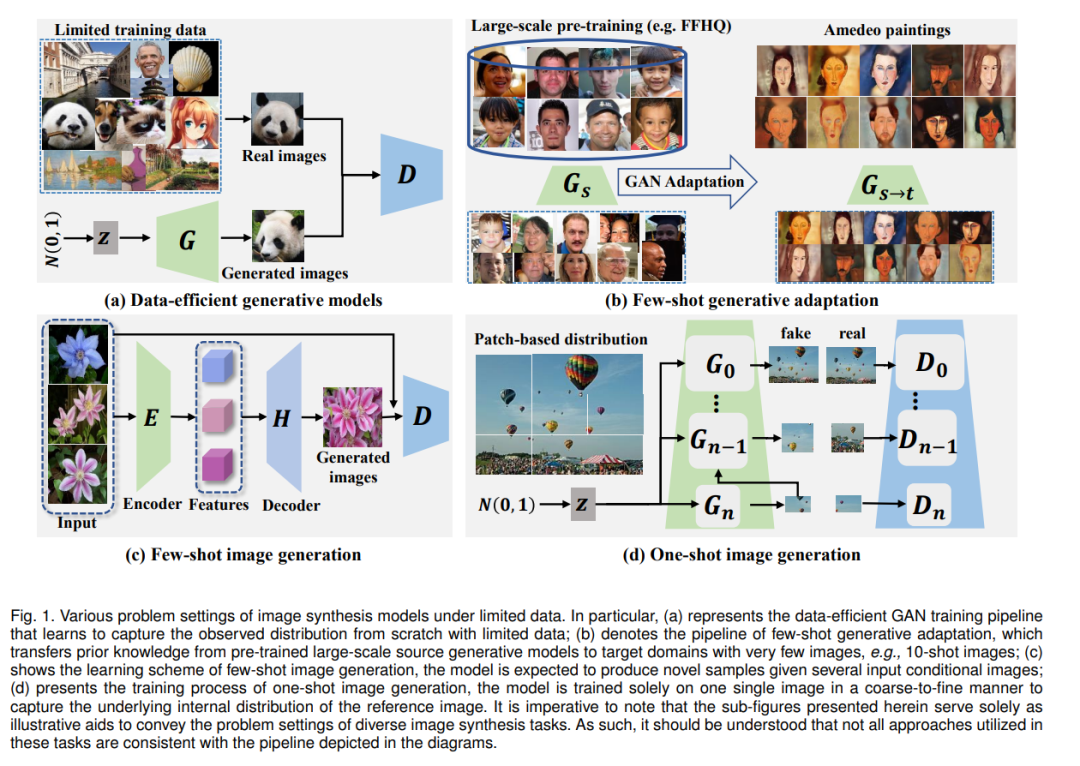
尽管在有限数据下的图像合成领域已经取得了显著的进步,但该领域缺乏统一的问题定义和分类。例如,少样本图像生成在[41],[43],[44],[45]中被定义为给定一个类别的少量图像,生成这个未见过的类别的多样化和逼真的图像,而在[46],[47],[48],[49],[50]中,少样本图像生成指的是将大规模和多样化的源域的先验知识适应到一个小的目标域。然而,他们在问题需求、模型训练和测试设置上有显著的不同。这种不一致的定义可能会导致不熟悉这些工作的读者产生歧义和误解。因此,一个全面的问题定义和分类对于更清晰地理解这个领域是至关重要的。此外,考虑到系统性调查的缺乏和有限数据生成的兴趣增加,我们认为有必要组织一个调查,以帮助社区追踪其发展。为此,本文首先为少样本范式中的各种任务提供了一个清晰的问题定义,并将它们分为四类:数据高效生成模型(第4节),少样本生成适应(第5节),少样本图像生成(第6节),和单样本图像合成(第7节)。然后,本文对该领域的先前研究进行了全面的概述。特别是,现有替代方案的技术演变、优点和缺点都有所呈现。另外,我们介绍了几个相关的应用,并突出了需要未来工作进一步研究的开放问题(第8节)。总的来说,这项调查旨在为新入门该领域的学者提供有限数据下图像合成的全面和系统的理解。我们希望我们的工作能为那些愿意仅用数十张训练图像开发自己的生成模型的研究者提供一种指导。本调查的贡献总结如下:
• 清晰的问题定义和分类。本调查为有限数据下的图像合成中的各种合成任务提供了清晰且统一的问题定义。此外,本调查提出了一个系统的分类法,将这些任务划分为四类:数据高效图像生成、少样本生成适应、少样本图像生成和单样本图像合成。 • 全面性。本调查对少样本范例中现有的最先进的生成模型进行了全面的概述。我们比较和分析了现有方法的主要技术动机、贡献和局限性,这些可以启发进一步改进的潜在解决方案。 • 应用和开放的研究方向。除了技术调查外,本调查还讨论了潜在的应用,并突出了需要进一步调查以改善有限数据下图像合成的开放性研究问题。 • 及时的最新资源库。为了持续追踪这个领域的快速发展,我们在GitHub/awesome-few-shotgeneration上提供了最新相关论文、代码和数据集的策划列表。
本综述关注的是训练深度生成模型在有限训练数据下生成多样化和合理的图像的方法。这些方法的主要目标是通过充分利用有限训练数据的内部信息并在数据分布范围内生成新的样本来减轻过拟合问题。然而,这些方法在模型输入、训练图和评估方面有所不同。
因此,在这项调查中,我们的目标是1) 让读者对有限数据下图像合成领域的各种问题设置有清晰的理解,2) 对先前艺术的模型概念、方法特性和应用提供深入的分析和深思熟虑的讨论,以及3) 提出一些未来研究的方向,并激发出更多有趣的工作以进一步改进。特别是,根据问题定义和实验设置,我们将现有的方法分为四类:数据高效生成模型、少样本生成适应、少样本图像生成、单样本图像生成。需要注意的是,所有这些类别都旨在生成与数据分布相对应的逼真和多样化的图像。这与少样本学习中的生成建模形成鲜明对比,后者显式地估计概率分布以计算给定样本的类标签[51],[52]。关于少样本学习的进展,我们建议读者参阅[53],[54]以获取更全面的评述。
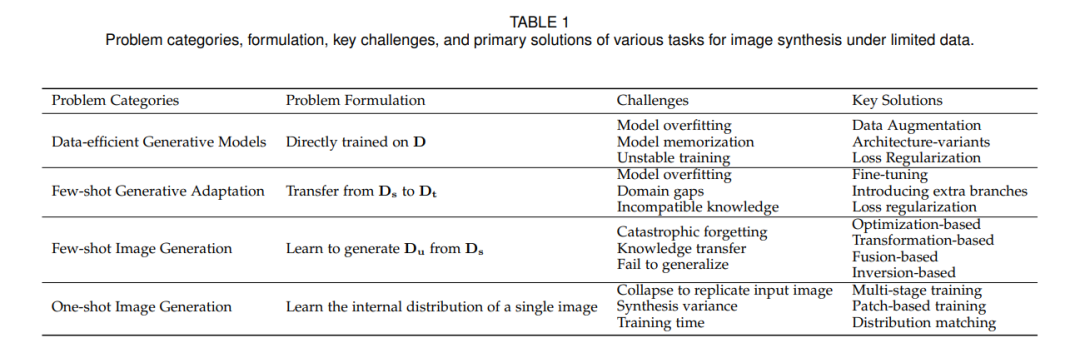
在这次调查中,我们的目标是提供关于有限数据下图像合成的各种任务的清晰理解。为了实现这个目标,我们提出了每个任务的定义和表述,考虑到每个问题背后的训练范式和任务特定的需求。我们已经构建了四个独立的问题,即数据高效生成模型、少样本生成适应、少样本图像生成和单样本图像生成。为了更好地说明这些问题,我们考虑了深度生成模型家族中的一个代表性类别,即生成对抗网络(GANs),来描绘这些问题的训练流程(见图1)。需要注意的是,所呈现的流程并不是为了代表每个任务中使用的所有方法,而是作为一个示例。此外,我们在表1中总结了每个任务的定义、模型需求和主要挑战。详细的方法设计和分类分别在相应的部分进行了介绍。