最近大火的“扩散模型”首篇综述来了!北大最新《扩散模型:方法和应用》综述,23页pdf涵盖200页文献

扩散模型是一类具有丰富理论基础的深度生成模型,在各种任务中都取得了令人印象深刻的结果。尽管扩散模型比其他最先进的模型取得了令人印象深刻的质量和样本合成多样性,但它们仍然存在昂贵的采样程序和次优的似然估计。近年来,研究人员对扩散模型性能的改进表现出极大的热情。在这篇文章中,我们提出了扩散模型的现有变体的第一个全面的综述。具体地说,我们提供了扩散模型的第一个分类,并将它们的变体分为三种类型,即采样-加速增强、可能性-最大化增强和数据泛化增强。我们还详细介绍了其他五种生成模型(即变分自编码器、生成对抗网络、归一化流、自回归模型和基于能量的模型),并阐明扩散模型和这些生成模型之间的联系。然后对扩散模型的应用进行了深入的研究,包括计算机视觉、自然语言处理、波形信号处理、多模态建模、分子图生成、时间序列建模和对抗性纯化。此外,我们提出了关于发展这一生成模式的新观点。
https://www.zhuanzhi.ai/paper/edf9ba1200e0740b307a923e23f4c966
导论
扩散模型是深度生成模型中最先进的模型。扩散模型在图像合成[1]上超越GAN后,在不同的任务上也显示出了一种很有前途的算法,如计算机视觉[2,3,4,5]、自然语言处理[6]、波形信号处理[7,8]、多模态建模[9,10,11]、分子图建模[12,13]、时间序列建模[14]和对抗式净化[15]。此外,扩散模型与其他研究领域有着密切的联系,如鲁棒学习[16,17,18],代表性学习[11,19,20,21]和强化学习[22]。然而,原始的扩散模型仍然存在采样过程缓慢的问题,通常需要数千步的评估才能得到一个样本[23]。它一直难以实现与其他基于似然的模型(例如自回归模型[24])竞争的对数似然。最近的一些研究从实际考虑或从理论角度分析扩散模型的能力来改进扩散模型的性能。然而,目前还没有文献对扩散模型的最新研究进展进行系统的综述。为了反映这一快速发展的领域的进展,我们首次对扩散模型进行了全面的综述。我们设想我们的工作将阐明扩散模型的设计考虑和先进方法,介绍其在不同领域的应用,并为未来的研究指明方向,我们的综述方案如图1所示。
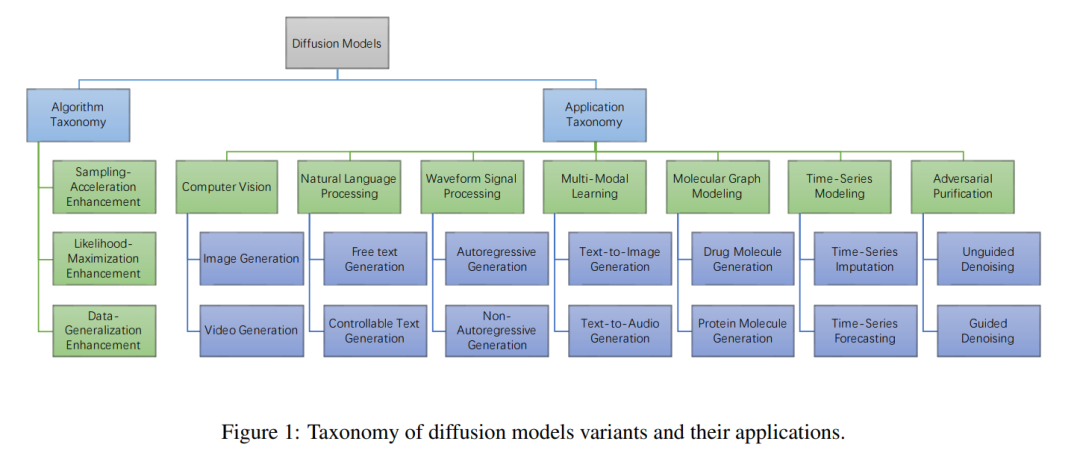
扩散概率模型最初是受非平衡热力学的启发,作为一种潜在变量生成模型提出的。这类模型由两个过程组成,第一个是通过在多个尺度上添加噪声来逐步干扰数据分布的正向过程,第二个是学习恢复数据结构的反向过程[23,25]。从这个角度看,扩散模型可以看作是一个层次非常深的VAE,即破坏和恢复过程分别对应编码和解码过程。因此,许多研究的重点是学习编码和解码过程,并结合变分下界的设计来提高模型的性能。或者,扩散模型的过程可以看作是随机微分方程(SDE)的离散化[26,27],其中正向和反向过程对应着正向SDE和反向SDE。因此,通过SDE对扩散模型进行分析,可以提供密集的理论结果和模型改进,特别是在采样策略方面。基于这些观点,我们建议将扩散模型分为三类: 采样过程增强(第3节)、可能性最大化增强(第4节)和泛化能力增强(第5节)。在这两类模型中,分别分析了离散时间和连续时间两种具有丰富经验和理论结果的模型。
在分析了三种扩散模型之后,我们介绍了其他五种常用的生成式模型(第6节),即变分自编码器、生成式对抗网络、归一化流、自回归模型和基于能量的模型。由于扩散模型具有良好的性质,研究人员开始将扩散模型与传统的生成模型相结合。我们对这些组合工作进行了具体的介绍,并阐明了对原始生成模型的改进。然后,我们系统地介绍扩散模型在大量任务中的应用(第7节),包括计算机视觉、自然语言处理、波形信号处理、多模态建模、分子图生成、时间序列建模和对抗性纯化。对于每个任务,我们给出了问题的定义,并介绍了利用扩散模型来处理问题的工作。在第8部分,我们提出了这一快速发展的领域的潜在研究方向,并在第9部分总结了综述。
本综述的主要贡献
新分类法。我们首先提出了一个新的和系统的分类扩散模型及其应用。具体而言,我们将现有的扩散模型分为三大类: 采样加速增强、似然最大化增强和数据泛化增强。此外,我们将扩散模型的应用分为七大类: 计算机视觉、自然语言处理、波形信号处理、多模态学习、分子图生成、时间序列建模和对抗性净化。
全面综述。本文首次全面概述了现代扩散模型及其应用。对每一类扩散模型进行了改进,并进行了必要的比较,总结了相应的文献。对于每种类型的扩散模型应用,我们演示了要处理的主要问题,并说明它们如何处理这些问题。
未来研究方向。本文对扩散模型在算法和应用方面的发展提出了一些有待进一步研究的问题和建议。
本文的组织本文的其余部分组织如下。在第二节中,我们对扩散模型进行了初步的介绍,并给出了扩散模型的标准形式,然后对扩散模型的变体进行了分类。从第3节到第5节,我们阐述了各类型扩散模型的主要增强,并分析了它们的优点和局限性。在第6节中,我们介绍了其他五种常用的生成模型,并说明了它们与扩散模型之间的联系。在第7节中,我们列出了扩散模型的一系列应用,提供了问题定义和解决方案分析。第8节讨论了挑战和可能的未来方向。在第9节中,我们总结了这一综述。
应用
由于扩散模型的灵活性和强度,它们最近已被应用于许多现实世界的应用。在本节中,我们将这些应用分为七个部分,包括计算机视觉、自然语言处理、波形信号处理、多模态学习、分子图建模、时间序列建模和对抗性净化。在每个小节中,我们首先对每个任务进行简要介绍,然后详细介绍如何利用扩散模型来提高性能。
图像超分辨率与修复
图像超分辨率是指从低分辨率(LR)图像中恢复高分辨率(HR)图像,而图像修补是指重建图像中缺失或破坏的区域。超分辨率扩散(SRDiff)[2]是第一个基于扩散的单幅图像超分辨率模型,该模型利用数据似然的变分界进行优化。SRDiff能够提供多样化和现实的超分辨率(SR)结果,通过逐步转换高斯噪声条件下的LR输入与马尔可夫链。重复细化超分辨率(SR3)[116]采用去噪扩散概率模型[23,25]进行条件图像生成,通过随机迭代去噪过程进行图像超分辨率。LDM[117]提出了潜在扩散模型,这是一种既提高了去噪扩散模型的训练效率和采样效率,又不损失质量的有效方法。为了帮助扩散模型使用有限的计算资源进行训练,同时保持质量和灵活性,LDM还利用预训练的自动编码器在潜在空间中利用它们。RePaint[118]设计了一种改进的去噪策略,通过重采样迭代来更好地调节图像。RePaint没有减慢扩散过程[119],而是在扩散过程中前进和后退,产生有语义意义的图像。调色板[120]提出了一个基于条件扩散模型的统一框架,并对该框架进行了四项具有挑战性的图像生成任务[121]的评估,如着色、修复、取消裁剪和JPEG恢复。级联扩散模型(cascade Diffusion Models, CDM)[122]由级联的多重扩散模型组成,生成分辨率逐渐增加的图像。CDM能够在类条件ImageNet[123]生成基准数据集上生成高质量的图像,不需要任何来自辅助图像分类器的监督信息。多速度扩散(MSDiff)[124]产生了一种条件多速度扩散估计器(CMDE),这是一种条件分数估计器,它结合了以往的条件分数估计方法[116,125]。
语义分割
语义分割是将图像中属于同一类别的部分聚类在一起。预训练可以提高语义切分模型的标签利用率,生成模型是一种替代预训练的方法。最近的一项研究[3]对最先进的DDPM[23]学习的表征进行了调查,并表明它们有能力捕捉对下游视觉任务有价值的高级语义信息。它开发了一种简单的方法,在少样本的操作点上利用这些学习到的表示,并显著优于包括VDVAE[126]和ALAE[16]在内的替代方法。受扩散模型成功的启发,学者们还研究了通过对自动编码器去噪学习到的表示在语义分割中的有效性[127]。解码器去噪预训练(Decoder去噪预训练,DDeP)[128]使用监督学习程序对编码器进行初始化,只在去噪目标引导下对解码器进行预训练。
异常检测
异常检测是机器学习和计算机视觉中的一个关键和具有挑战性的问题[129]。生成模型已经被证明具有强大的异常检测机制。它们有助于建立正常或健康参考数据的模型,这些参考数据随后可被用作异常评分的基线[130],包括GAN、VAE和扩散模型[131,132]。AnoDDPM[131]提出了一种新的异常检测方法,该方法利用DDPM破坏输入图像,并重建图像的健康近似。该方法比对抗性训练具有更好的建模性能和更高的样本质量,并且训练更加稳定。DDPM- cd[132]提出了一种通过DDPM将大量无监督遥感图像纳入训练过程的新方法。它利用预训练的DDPM和来自扩散模型解码器的多尺度表示进行遥感变化检测。它的目的是训练一个光变化检测分类器,有效地检测精确的变化。
视频生成
在深度学习时代,由于视频帧的时空连续性和复杂性,高质量的视频生成仍然具有挑战性[4,5]。最近的研究求助于扩散模型来提高生成视频的质量。柔性扩散模型(Flexible Diffusion Model, FDM)[137]提出了一种新的基于DDPM的视频生成框架,可以在不同的现实场景下生成长期的视频补全。它引入了一个生成模型,可以在测试期间对视频帧的任意子集进行采样,并提出了一个为此目的设计的架构。受神经视频压缩研究进展的启发[138],残差视频扩散(RVD)提出了一种自回归的端到端优化视频扩散模型。它通过反向扩散过程产生的随机残差来修正确定性的下一帧预测,从而连续生成未来帧。视频扩散模型(Video Diffusion Model, VDM)[139]引入了一种用于视频时空扩展的条件采样方法。它超越了之前提出的方法,并生成长、高分辨率的视频。
自然语言处理
自然语言处理是旨在理解、建模和管理人类语言的研究领域。文本生成也被称为自然语言生成,已经成为自然语言处理中最关键和最具挑战性的任务之一[140]。它的目标是在给定输入数据(如序列和关键字)或随机噪声的情况下,用人类语言生成可信和可读的文本。研究人员已经开发了许多用于文本生成的广泛应用的技术[141,142]。离散去噪扩散概率模型(D3PMs)[6]引入了用于字符级文本生成的类扩散生成模型[143]。他们通过超越具有统一转移概率的腐蚀过程,推广了多项扩散模型[144]。大型自回归语言模型(LMs)能够生成高质量的文本[90,145,146,147]。为了在实际应用中可靠地部署这些LM,文本生成过程通常是可控的。这意味着我们需要生成能够满足要求的文本(如主题、句法结构)。在文本生成中,不需要再训练就能控制语言模型(LMs)的行为是一个重要的问题[148,149]。尽管最近的研究在简单句子属性(如情感)的控制上取得了显著的成功[150,151],但在复杂的、细粒度的控制(如句法结构)上却鲜有进展。为了解决更复杂的控制问题,Diffusion-LM[152]提出了一种基于连续扩散的新的语言模型。Diffusion-LM从一系列高斯噪声向量开始,逐级降噪成单词对应的向量。逐步去噪的步骤有助于产生分层连续的潜在表征。这种分层连续的潜在变量可以使简单的、基于梯度的方法实现复杂的控制。
未来方向
新视角。我们观察到离散扩散模型仍存在一些未解决的问题,这些问题在自然语言处理中具有实用价值。由于数据的离散性,在连续的高斯噪声下很难恢复已损坏的数据。但如果我们加入像随机游走这样的离散噪声,那么评分函数将变得不明确,评分匹配框架将不再适用。同样的问题也存在于其他数据类型中,比如图。因此,需要新的方法和视角[197]。在理论层面,我们仍然需要检验扩散模型中一些公认的前提。例如,在实践中,人们普遍认为正向处理会将数据转换为标准的高斯噪声。然而,SDE的有限时间解不能忘记原始数据的分布。这些实践和理论之间的不匹配可以激发更好的模型设计[198]。在实践层面,由于扩散模型的灵活性,许多经验方法的泛化能力有待进一步评价和分析[34,199,200,197]。
泛化到更多的应用。如第7节所示,扩散模型已应用于7种不同类型的场景,从计算机视觉到对抗性纯化。然而,仍有一些场景有待开发,如文本到视听语音合成和视觉问答(VQA)。此外,我们可以明显地发现,现有的大多数应用都局限于单一输入/输出或简单输入/输出。因此,如何使扩散模型能够处理复杂的输入并产生多种输出,并在现实场景中获得更好的性能,是研究人员面临的关键和挑战。虽然扩散模型在鲁棒学习、代表性学习和强化学习等研究领域已经得到了研究,但仍存在与更多研究领域相联系的机会。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DM23” 就可以获取《最近大火的“扩散模型”首篇综述来了!北大最新《扩散模型:方法和应用》综述,23页pdf涵盖200页文献》专知下载链接





