深度学习可解释进展到哪了?CIKM2022教程《深度学习可解释:数据视角》,194页ppt

深度学习模型在从计算机视觉、自然语言处理到图形挖掘等各种任务中都取得了卓越的预测性能。许多不同领域的企业和组织正在构建基于深度学习的大规模应用程序。然而,人们越来越关注这些模型的公平性、安全性和可信性,这主要是由于其决策过程的不透明性质。最近,人们对可解释深度学习越来越感兴趣,它旨在通过解释模型的行为、预测或两者都解释来减少模型的不透明度,从而在人类和复杂深度学习模型之间建立信任。近年来,针对模型的低可解释性和不透明性问题,提出了一系列的解释方法。在本教程中,我们将从数据的角度介绍最近的解释方法,针对分别处理图像数据、文本数据和图形数据的模型。我们将比较它们的优势和局限性,并提供实际应用。
https://sites.google.com/gwmail.gwu.edu/tutorial-proposal-cikm-2022/home?authuser=0
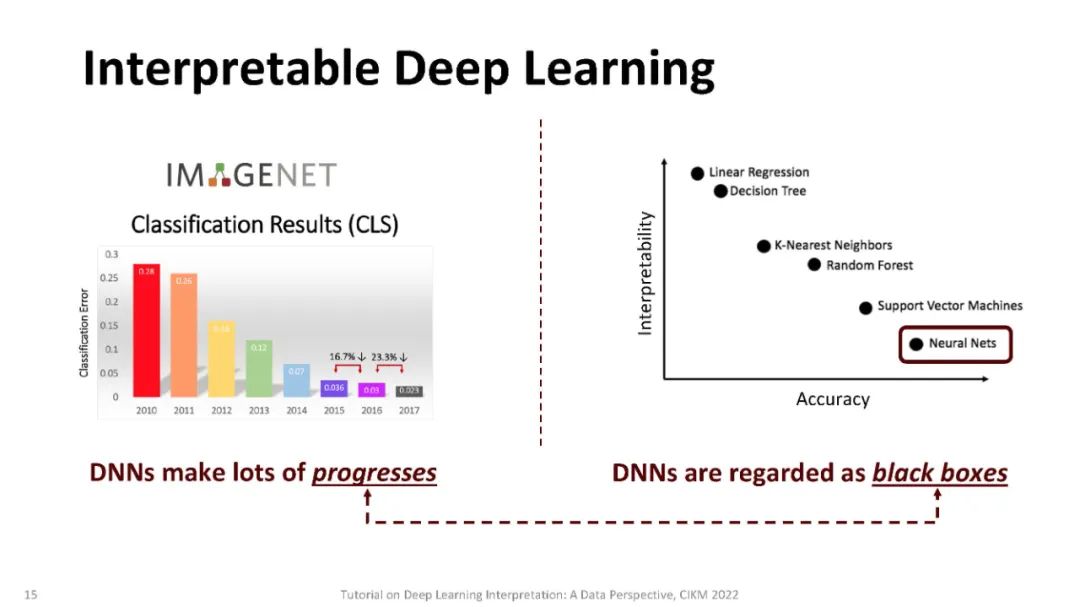
深度学习模型在各种各样的任务中取得了卓越的预测性能,如计算机视觉(CV)、自然语言处理(NLP)、图挖掘和强化学习[11,14,20,22,38,41]。许多跨不同领域的企业和组织正在构建基于深度学习模型的大规模应用程序,但人们越来越关注这些模型的公平性、安全性和可信性[12],这主要是由于它们的决策过程的不透明性质。例如,面部识别的深度学习模型在面对皮肤较黑的女性图像[3]时表现非常糟糕,自动驾驶系统在检测与行人互动的人群分组时识别精度低得令人无法接受,为STEM工作招聘新员工的NLP系统有很强的偏见,认为男性比女性更合格[16]。由于缺乏令人信服的可解释性模型,深度学习在高风险预测应用(如医疗保健、刑事司法和金融服务)中广泛采用还不可能。
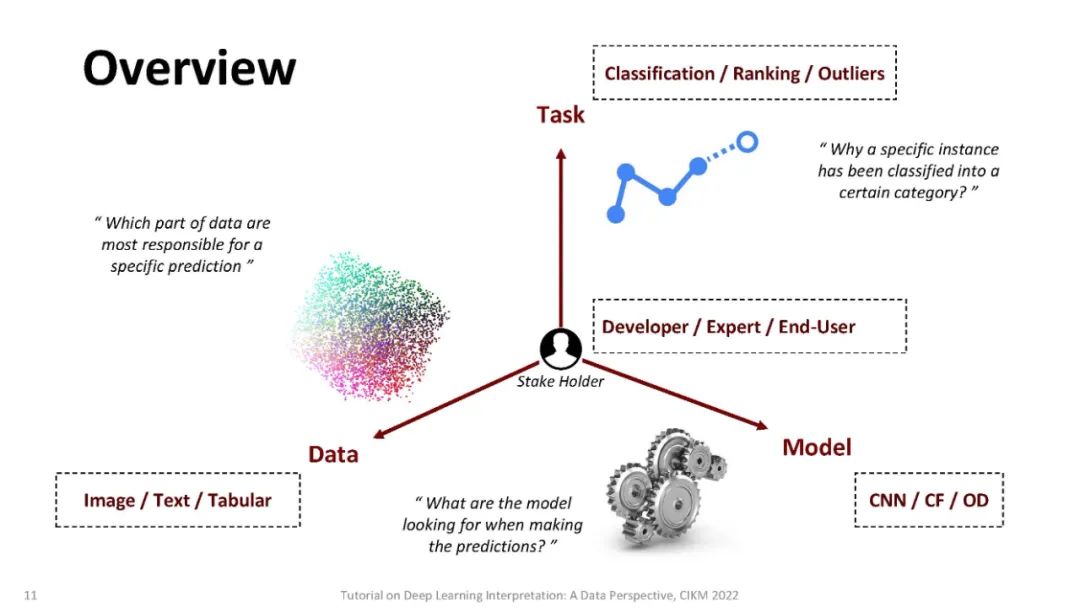
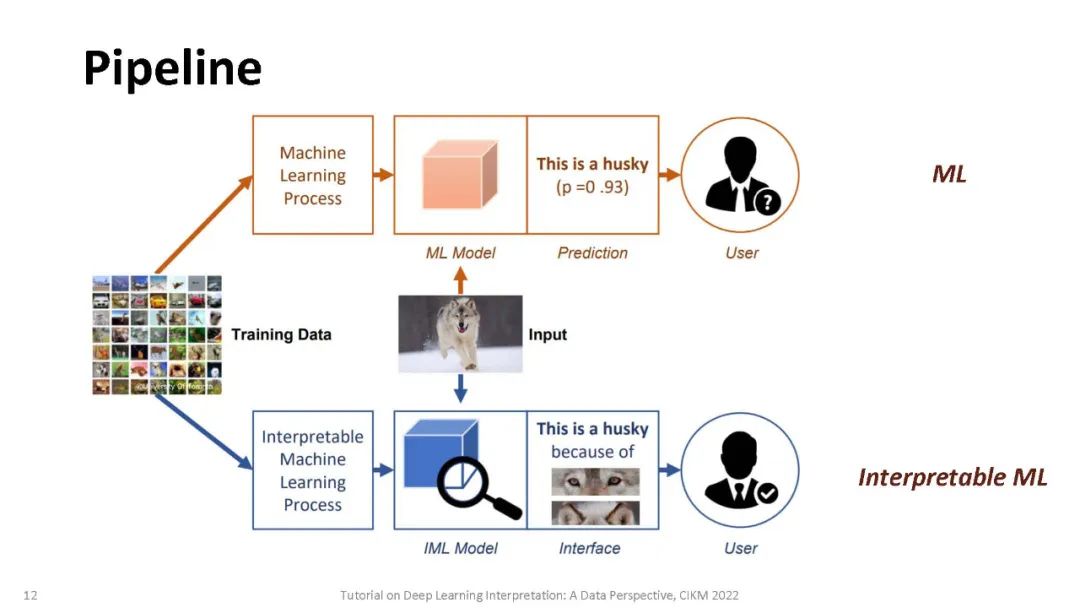
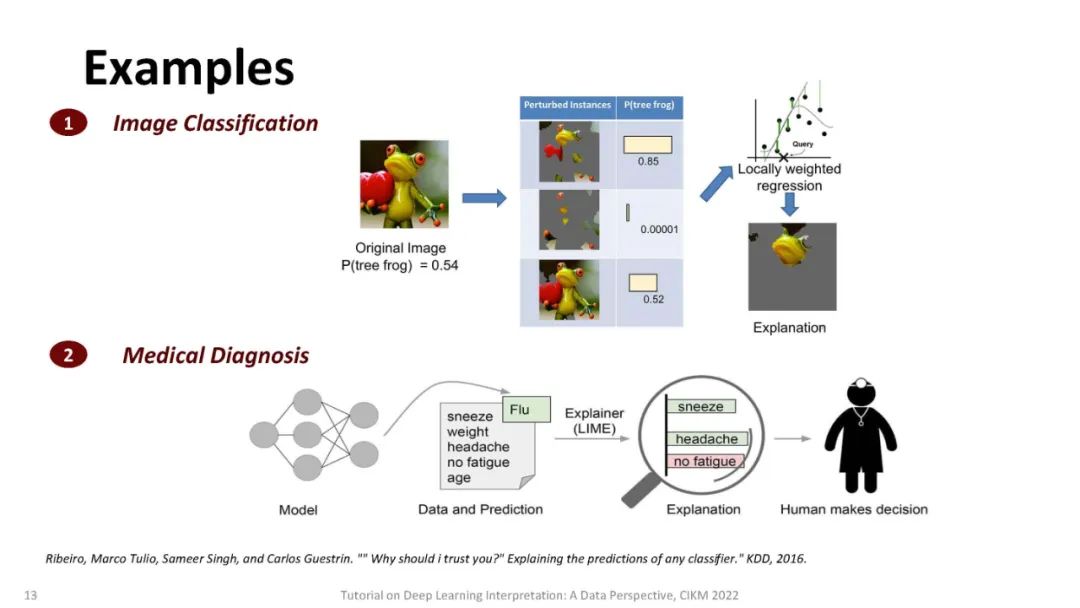
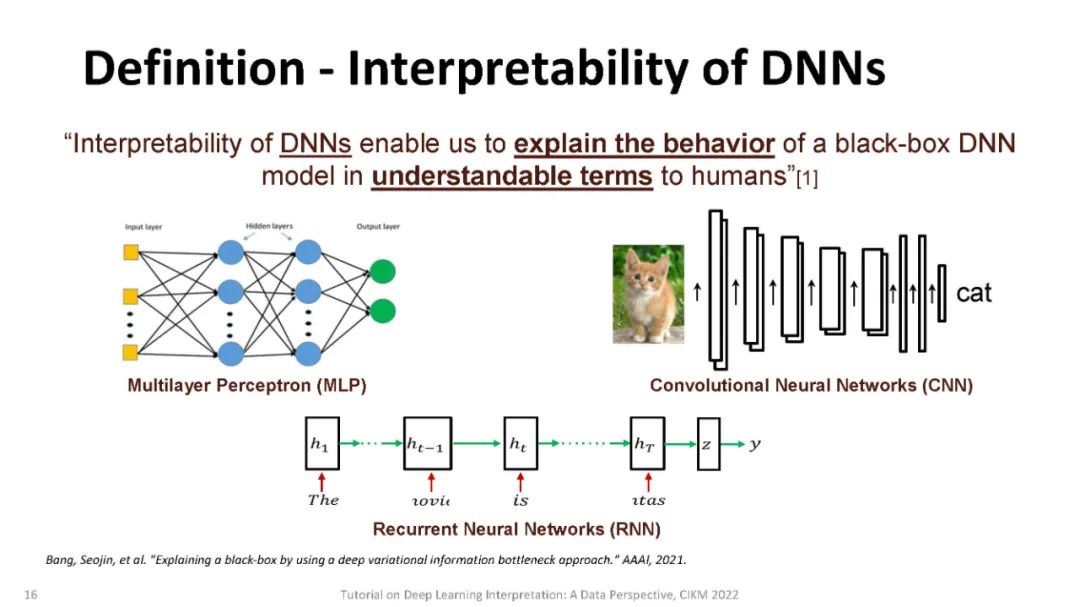
尽管其他类型的模型(如线性回归或基于树的方法)也存在潜在风险,但通过检查模型使用的节点的权重或拆分并选择那些产生最佳性能的节点,可以很容易地理解它们的决策[13,18]。不像其他经典的机器学习模型,检查模型使用的节点的权重或分割,并选择一个具有最佳性能的[13]是不可能的,因为它们的过度参数化,实际上可以超过数百万个参数,以及分层非线性的性质。最近,人们提出了一系列方法来解释深度学习模型的行为或预测。这些方法可以根据: (a)这些方法是否假定可以访问模型的内部结构(模型相关),或者是否可以应用于任何黑盒模型(模型无关)。(b)模型是解释单个实例(局部解释)还是解释模型的整体行为(全局解释)。(c)可解释性是通过梯度(基于梯度的)还是通过非梯度的分析(非基于梯度的)实现的。与此同时,现实应用中的数据可能具有不同的格式,如图像、文本和图表,显示出不同的特征。因此,它激发了从数据角度对解释方法的研究。
在本教程中,将介绍深度学习解释的基本定义和术语。我们的教程分为四个部分:(i)图像分类的解释; 对文本的解释;(iii)图的解释,(IV)解释深度强化学习。我们还将详细介绍目前流行的可解释模型,并强调它们的优点和局限性。本教程的学习成果如下:(1)了解主流可解释模型的理论动机、分类和理论表述。(2)比较目前流行的可解释模型的优点和局限性,并提出推广这些方法的可能机会。(3)通过编码、训练和可视化指导原则,介绍在解释图像、NLP、图表和深度强化学习的预测DNN方面的实际应用。
讲者:











专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“D194” 就可以获取《深度学习可解释进展到哪了?CIKM2022教程《深度学习可解释:数据视角》,194页ppt》专知下载链接





