人体解析旨在将图像或视频中的人体分割成多个像素级的语义部分。在过去的十年中,它在计算机视觉社区中获得了极大的兴趣,并在广泛的实际应用中得到了应用,从安全监控到社交媒体,再到视觉特效,这只是其中的一小部分。尽管基于深度学习的人工解析方案已经取得了显著的成就,但许多重要的概念、存在的挑战和潜在的研究方向仍然令人困惑。全面回顾了单人体解析、多人体解析和视频人体解析这3个核心子任务,介绍了它们各自的任务设置、背景概念、相关问题和应用、代表性文献和数据集。还在基准数据集上对所审查的方法进行了定量的性能比较。此外,为了促进社区的可持续发展,提出了基于Transformer的人体解析框架,通过通用、简洁和可扩展的解决方案,为后续研究提供了高性能的基线。最后,指出了该领域一些未被充分研究的开放问题,并提出了未来研究的新方向。我们还提供定期更新的项目页面,以持续跟踪这个快速发展的领域的最新发展:https://github.com/soeaver/awesome-human-parsing。
https://www.zhuanzhi.ai/paper/80d08dd611f75862e84484b42c310cf0
1. 引言
人体解析[1]-[5]是以人类为中心的视觉理解[6]的基础任务,旨在对图像或视频中的人体部位和服装配饰进行像素级分类。人体解析在安防监控、自动驾驶、社交媒体、电子商务、视觉特效、艺术创作等广泛应用领域发挥着重要作用,已经开展了大量的研究,催生了各种优秀的人体解析解决方案和应用。早在本世纪初,就有研究试图在非常有限的情况下识别上半身服装[10]的水平、服装[11]的语法表征以及人体轮廓[12]的变形。这些早期研究促进了像素级人体部位和服装识别的研究,即人体解析任务。随后,利用传统的机器学习和计算机视觉技术,如结构化模型[1]、[13]、[14]、聚类算法[15]、语法模型[16]、[17]、条件随机场[18]-[20]、模板匹配[21]、[22]和超像素[23]-[25]等,解决了人体句法分析问题。随后,深度学习和卷积神经网络[26]-[32]的繁荣进一步推动了人体解析的蓬勃发展。注意力机制[33]-[36]、尺度感知特征[37]-[40]、树形结构[3]、[41]、图结构[4]、[42]、[43]、边缘感知学习[44]-[46]、姿态感知学习[2]、[47]、[48]等技术[49]-[52]大大提高了人体解析的性能。然而,目前存在的一些挑战和研究不足使得人体解析仍然是一项值得进一步探索的任务。

随着人体解析的快速发展,出现了大量的文献综述。然而,现有的研究并不精确和深入:一些研究仅从宏观的时尚/社交媒体角度对人体解析进行了肤浅的介绍[53],[54],或者仅从微观的人脸解析角度对人体解析的子任务[55]进行了回顾。此外,由于分类的模糊性和方法的多样性,全面和深入的研究是非常必要的。本文提供了第一篇综述,系统地介绍了背景概念、最新进展,并对人体解析进行了展望。本综述从一个全面的角度回顾了人体解析,不仅包括单个人体解析(图1 (a)),还包括多个人体解析(图1 (b))和视频人体解析(图1 (c))。在技术层面,对近10年基于深度学习的人体分析方法和数据集进行综述。为了提供必要的背景,还介绍了非深度学习等领域的相关文献。在实践层面,对各种方法的优缺点进行了比较,并给出了详细的性能比较。在总结和分析现有工作的基础上,展望了人体解析的未来机遇,并提出了一个新的基于transformer的基线,以促进社区的可持续发展。人工解析方法和数据集以及提出的基于transformer的基线列表可以在https://github.com/soeaver/awesome-human-parsing上找到。
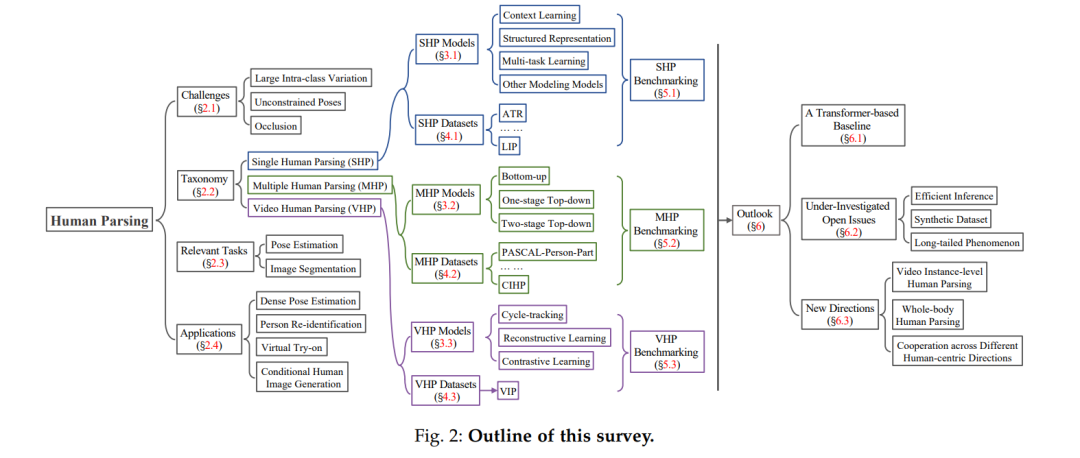
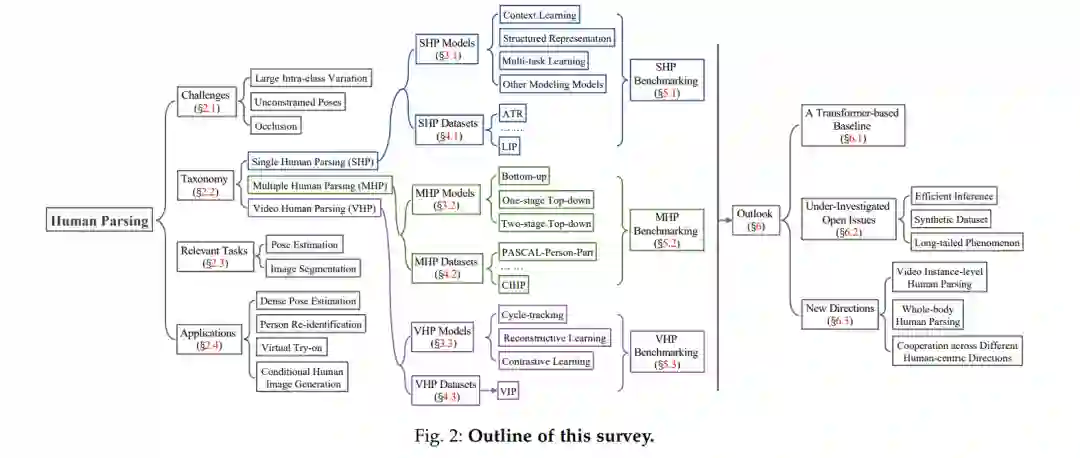
图2显示了这个综述的大纲。§2简要介绍了问题的形成和挑战(§2.1)、人体分析的分类(§2.2)、相关任务(§2.3)和人体分析的应用(§2.4)。§3详细回顾了具有代表性的基于深度学习的人体分析研究。常用的数据集和性能比较见§4和§5。在§6中提出了对人体分析未来机会的展望,包括一个新的基于transformer的基线(§6.1),几个未被研究的开放问题(§6.2)和未来研究的新方向(§6.3)。结论将在§7中得出。2. 基于深度学习的人体解析方法现有的人体解析可分为单人体解析、多人体解析和视频人体解析3个子任务,分别关注部件关系建模、人体实例判别和时间对应学习。根据这种分类法,我们对具有代表性的作品(图3下半部分)进行了梳理,并在下文进行了详细的回顾。**

单人体解析(SHP)模型
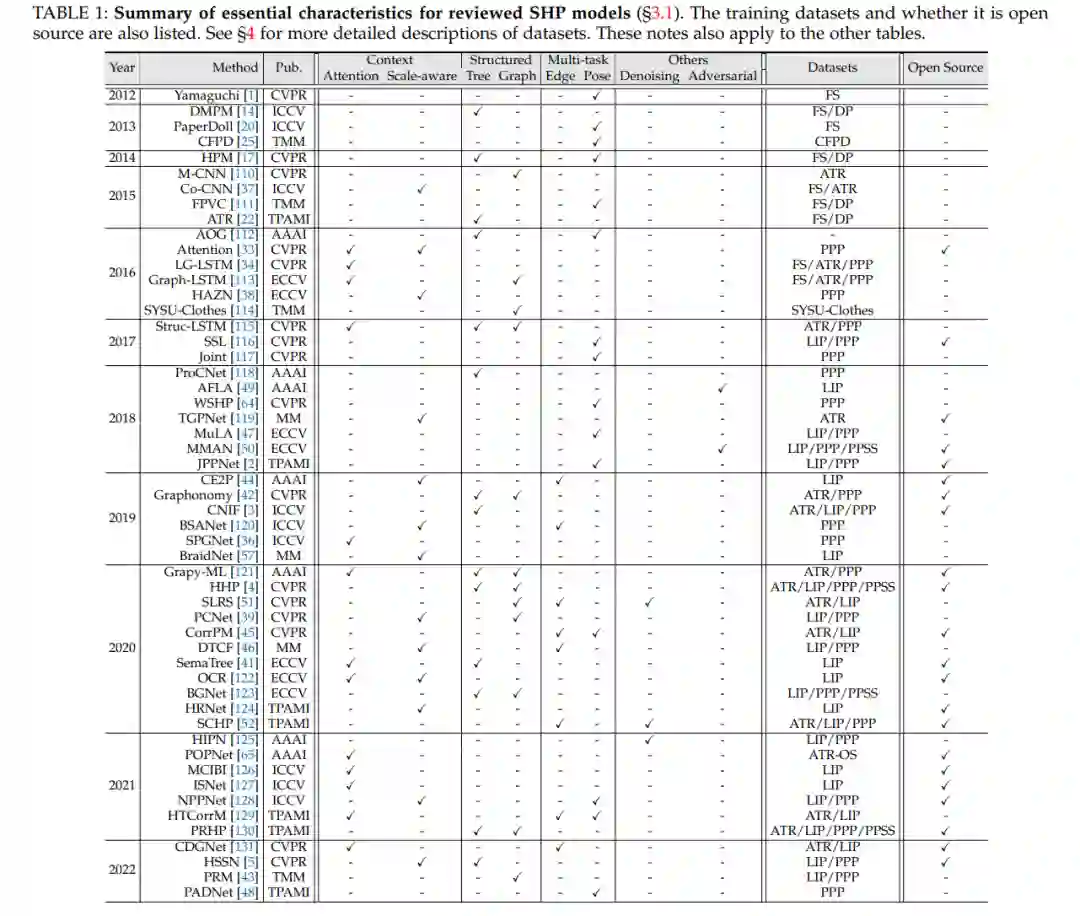
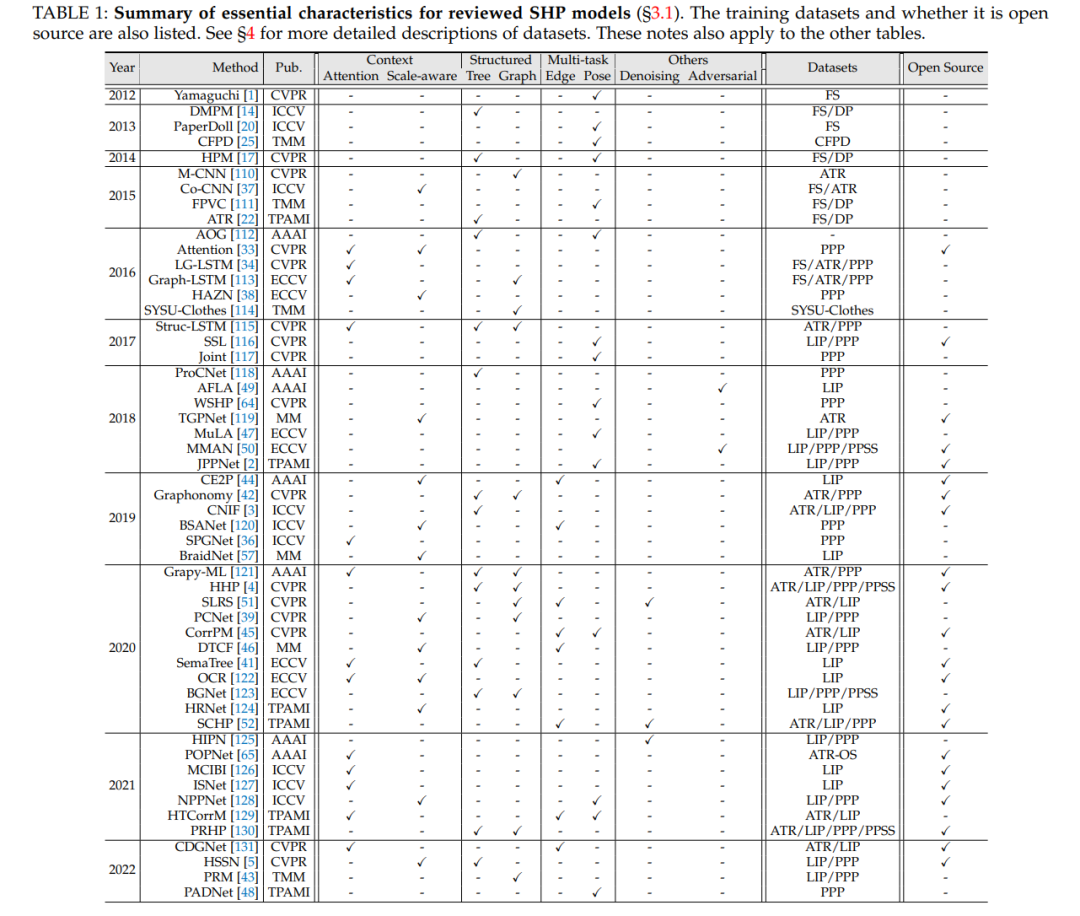
SHP考虑通过部件关系建模来提取人体特征。根据建模策略,SHP模型可分为3类:上下文学习、结构化表示和多任务学习。此外,考虑到一些特殊但有趣的方法,我们将其作为“其他建模模型”进行综述。表1总结了审查过的SHP模型的特点。
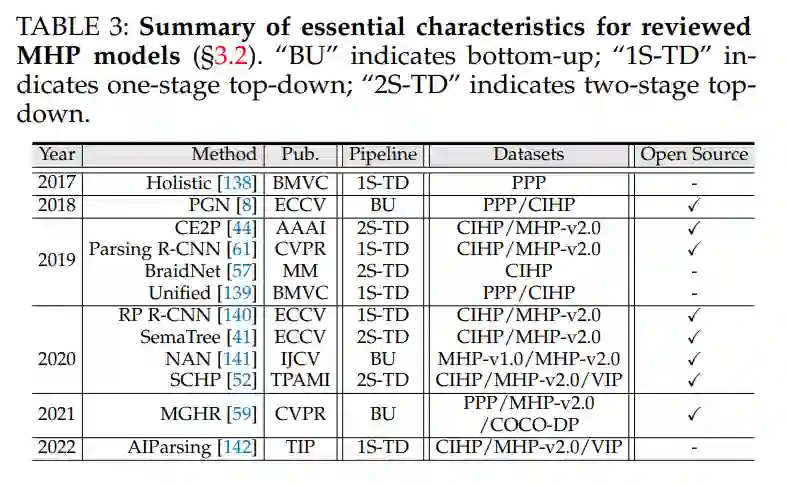
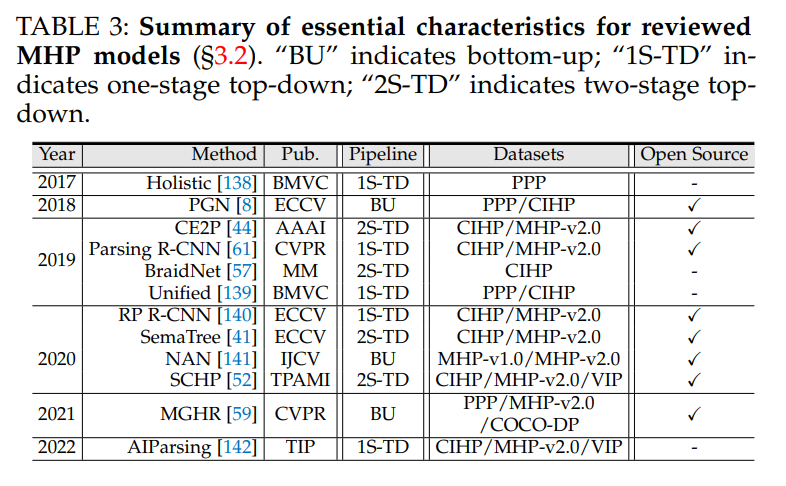
多人体解析(MHP)模型MHP寻求在图像平面上定位和解析每个人体。任务设置类似于实例分割,因此也称为实例级人工解析。根据其识别人类实例的管道,将MHP分为三种范式:自下而上、单阶段自上而下和两阶段自上而下。表3列出了所审查的MHP模型的基本特征。
视频人体解析(Video humanparsing, VHP)模型现有的VHP研究主要集中在通过亲和力矩阵将第一帧传播到整个视频中,亲和力矩阵表示从原始视频数据中学习到的时间对应关系。考虑到无监督学习范式,可以将其分为三类:周期跟踪、重构学习和对比学习。我们在表5中总结了所审查的VHP模型的基本特征。