无人机图像处理技术精髓汇总 (二) 机器学习图像分割剖析
航拍是无人机在实际场景中的重要应用。本系列文章将简单介绍无人机上的视觉算法。
自动分析航拍图像的内容是很多行业迫切需要的,尤其是图像规模大,需求复杂的情况下。以前常用一些较为简单的算法(阈值分割,色彩空间变换等)完成该项任务。近年来,随着机器学习中神经网络方法取得重大进展,很多这方面的需求可以改用神经网络完成。本篇文章将简单解析机器学习用于航拍图像分割的流程。
本文作者工作于泛化智能(giai.tech),负责泛化航空(Generalized Aviation)项目,致力于使用计算机视觉等技术完成无人机自动驾驶。
简单介绍一下使用机器学习方法进行航拍图像分割的全流程。
数据集采集#
可以使用网络上公开的数据集,也可以自行录制并标注。
MSCOCO是常用的图像任务数据集,其中有图像分割任务对应的标注。(链接:http://cocodataset.org/#home 选择里面的Object Segmentation)。
对于航拍图像,CrowdAI挑战赛用的数据集较为实用。(链接:https://www.crowdai.org/challenges/mapping-challenge/dataset_files)
神经网络方法的本质是有监督机器学习方法。有监督机器学习的本质是从一组数据映射(f(X)->y)中学习某函数f。
例如,一幅航拍图像中包含建筑,道路,农田三种类型的像素点。则理想的映射模型为:
图像中的点->对应类型。
人经过简单的培训可以轻松的分析如下图的图像。但要将这一任务通过手动编写程序,分析像素在图像或空间中的位置(x,y,z或GPS经纬度)及其颜色对其进行分类是很困难的。通过机器学习方法,我们将手动编写这一函数f的过程转化为提供一组恰当的X,y的数据和f的形式,让计算机自动选择较为合适的f以达到最优化结果的目的。图像X是通过航拍采集或从网上下载的,如果没有对应的标注信息,就需要通过手动标注图像获取。幸运的是常用的分割任务网络上是有数据集的,因此只有一些特殊类型的分割需求需要手动标注。
原始图像

分割后的结果图
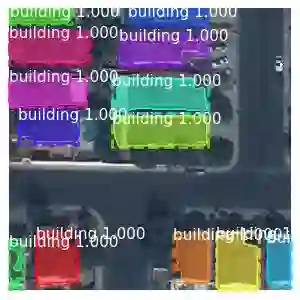
图像分割算法#
2.1 传统算法简单介绍**(对传统算法不感兴趣的读者可以直接到下一小节)#
在卷积神经网络方法占据主流的今天,这些传统算法虽然已经不是常用方法,但对一些数据集较少,或有一定特殊需求(可解释性,分割精度,简单情况下的稳定性)的场景下仍有应用,因此仍有必要简单介绍。
RGB阈值分割:
如草地和道路分割等简单应用。提取像素的G和B分量,设计分类器即可。
这对一些多光谱/高光谱遥感图像(红外,紫外等)一样适用。有些RGB图像下需要图像上下文关联的任务(如火焰,作物和杂草)在某些光谱图像下可以直接在颜色通道上分割。因此遇到这种情况可以权衡使用RGB图像并设计模型和直接采购多光谱/高光谱图像或其传感器的成本。
如果对直接分割产生的结果不满意,可以考虑使用腐蚀-膨胀等形态学方法进行后处理,消除一些杂散的噪点。
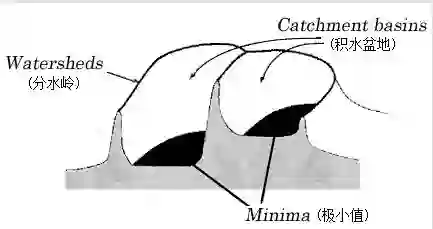
2.分水岭算法
在图像函数中注入"水",沿着空间亮度函数的局部"山脊",将图像分割成许多小块。这种算法往往需要结合手动标注,以合并产生的过多的小块,因此除了用于快速标注,一般没有太多实用价值。
3.流蛇法能量最小化
这一算法曾经是较为主流的方法。但它仅适用于较为简单的图像。它的基本思想是:构造一组约束,使得曲线既不过分复杂曲折(弯曲能量约束,因为过分曲折的曲线往往是分割太过于注重细节而出错了),边界又较为清晰(灰度能量约束)。

4.聚类法/高斯混合模型
这类算法将相似的像素聚类在一起,认为像素的分布服从一定的统计模型。由于不需要训练数据,只需要根据经验调整参数,因此也有一定的应用。
然而对一些较为复杂的应用,这些传统方法就显得很吃力了。这些算法不但不能给出区域内的像素到底属于哪种类型,甚至连明确的分割一些稍微复杂的情况(遮挡,不良光照)都很困难。
比如,试试这个?


2.2 神经网络方法#
现在流行的神经网络方法的理论基础很简单:深层(含有至少一个隐藏层)的全连接神经网络可以拟合任意连续函数。
要讲图像分割,我们先从精度和复杂度低一些的图像检测说起。
最经典的图像检测网络是R-CNN.R-CNN在图像上生成若干个候选区域(通过Selective Search,得到类似分水岭分割后的许多不规则小块,通过这些小块产生候选框),并对这些候选区域进行特征计算(也就是将其输入卷积神经网络,获取输出的向量),再将特征向量送入一个SVM(可以理解成进行一次简单的非线性变换然后分割,SVM的表达能力逊于神经网络,但不容易过拟合,适合少量有典型特征数据的分类)。在对每个区域进行分类的同时,还有一个简单的线性回归,使得物体检测框收缩的更精确。
在这之后是Fast R-CNN。主要改进是:
将SVM替换成了一小块神经网络。
图像的特征提取算法只运行一次。这里要用到卷积的平移不变性质。在整张图像运行卷积网络之后,生成的结果图的对应位置是可以精确对应到原图的相应位置的。以信号处理中常用的一维卷积举例: ( t[100] * u[20] )[0],不进行补零延长,就是t的前20个截断和u的卷积。对二维卷积也一样。生成整个图像之后,由于神经网络的结果是语义的(也就是对图像内容较为抽象的理解),因此可以使用一种特殊的局部取最大策略,ROI Pooling,进行大小放缩,归一化到统一的大小以便后续操作。ROI Pooling可以理解成是对图像的缩放操作,只不过这里的图像不是我们常见的RGB图像,放缩策略也不再是双线性插值而是区域内取最大。
这里很有价值的就是ROI Pooling的思想:既然原始图像可以进行大小放缩,那特征图像也可以做对应的操作,且网络的性质仍然得到保证。
Faster R-CNN是对Fast R-CNN的一次重大改进。这里提出了一种选取候选区域的神经网络,Region Proposal Layer。这部分网络提出一些候选的区域(也就是中心点和长宽的组合)。这些被提出的候选区域将被用来指导ROI Pooling选取对应的结果。这里比较有价值的思想是使用神经网络选取感兴趣的区域,而不再使用Selective Search这类的算法。这些选取不是随意的,而是基于一些确定的位置和选框形状,进行自动精修和舍弃,以提高选框的精度。
对于图像分割算法,其分割结果可以分为基于类型的和基于实例的。基于类型的方法将不同类型的物体分隔开,而基于实例的方法先分割实例,再为它们指派类型。如果图像中有多个人物,基于类型的方法只将人和背景分开,而基于实例的方法将每个人对应的像素也分到不同的组中。
这两种算法的本质区别出现在图像中出现概念重叠的时候。如果图像中人物的身上有领带,那么领带对应的像素是属于人还是属于领带?基于类型的分割无法提供令人满意的结果;而基于实例的方法认为这部分像素既属于人又属于领带,这显然是更合理的。
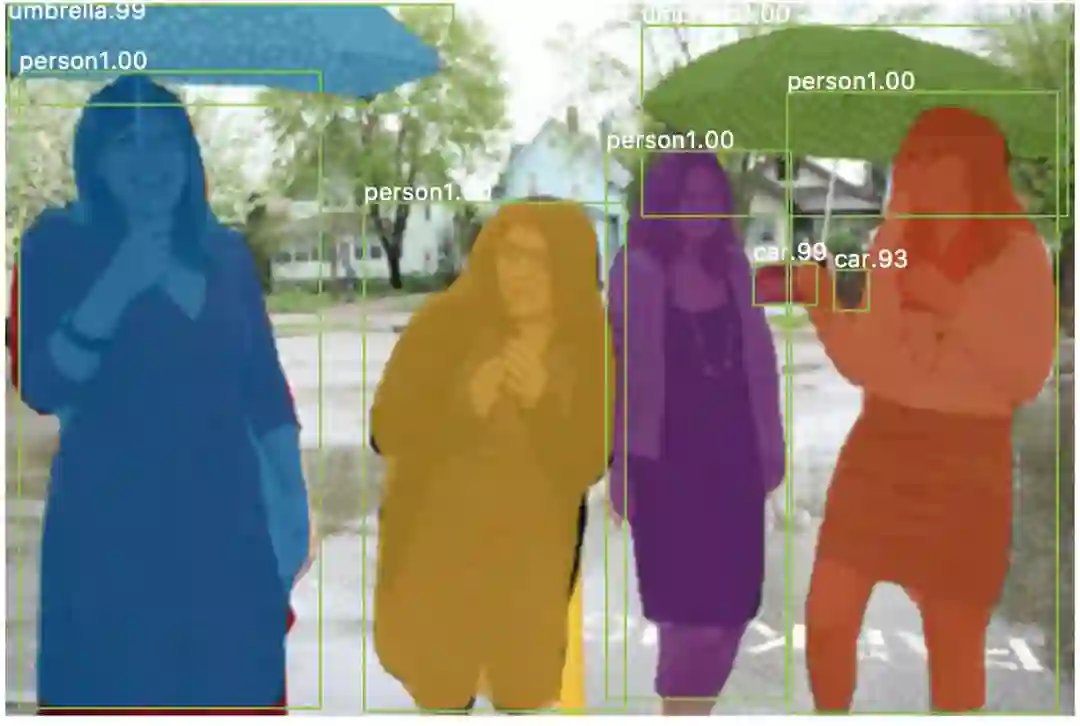
基于这种想法,Mask R-CNN被提出。Mask R-CNN改进了ROI Pooling操作,将取最大操作改为类似图像缩放的双线性插值。通过这种变化使得原图和分割后的图像像素对应更精准了。
基于类型的分割结果:
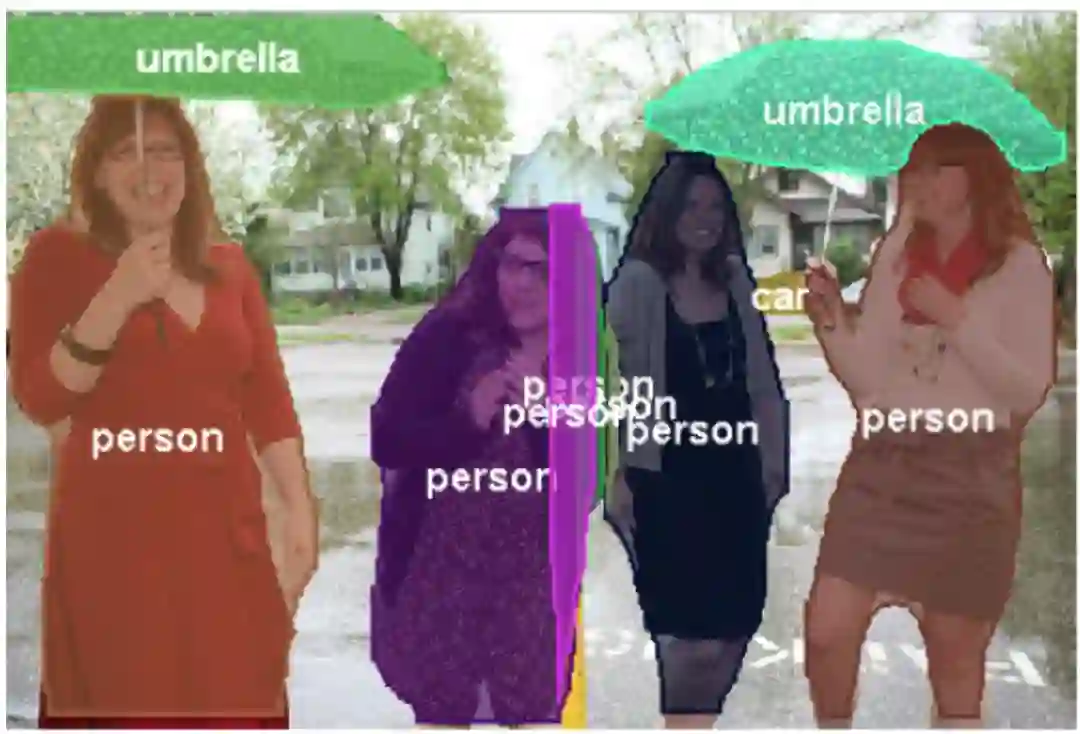
Mask R-CNN效果:
3.算法部署
Mask R-CNN等神经网络方法的部署可在普通PC机上进行,但最好有支持CUDA的显卡加速。有显卡加速时运算速度约为5张/s量级,纯用CPU计算可能一张图需要消耗10s级别的时间。显卡加速的原理类似图形渲染,使用显卡中大量的流核心进行快速的批量矩阵运算。
这部分软硬件配置和部署工作较为繁琐,我们(泛化智能)推出了一款在线工具,可以使用您的图像进行快速分割尝试。这一工具将很快在dimianzhan.com为大家免费提供。未来我们会为大家提供更多这类方便易用的工具。




