

图相关应用在学术界和工业界都有着显著的增长,这主要是因为图具有强大的表示能力。然而,高效地执行这些应用面临多种挑战,如负载不平衡、随机内存访问等。为解决这些挑战,研究人员提出了各种加速系统,包括软件框架和硬件加速器,所有这些系统都包含图预处理(GPP)的步骤。GPP作为应用正式执行之前的准备步骤,涉及到诸如采样、重新排序等技术。然而,GPP的执行常常被忽视,因为主要的关注点通常是增强图应用本身。这种疏忽令人担忧,特别是考虑到实际图数据的爆炸性增长,其中GPP变得至关重要,甚至占据了系统运行开销的主导地位。
此外,由于高度定制,GPP方法在不同设备和应用中表现出显著的差异。不幸的是,还没有全面的工作系统地总结了GPP。为了解决这一缺口,并促进对GPP更好的理解,我们呈现了一个专门针对这一领域的全面调查。我们提出了一个双层GPP分类法,同时考虑到算法和硬件的视角。通过列出相关的工作,我们阐述了我们的分类法,并对不同的GPP技术进行。
https://www.zhuanzhi.ai/paper/13520de2fddf1159cd8a72d80bc67e6d
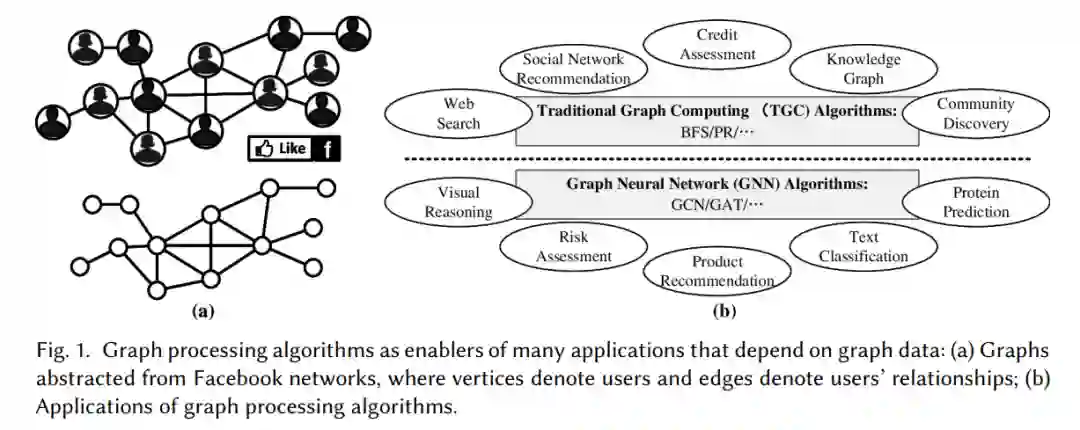
图处理应用因其从图数据中提供有价值洞见的能力而受到了显著关注。在各种实际应用场景中,数据可以使用图结构进行有效表示,其中社交网络是一个典型例子[103]。例如,图1(a)描述了Facebook社交网络的图抽象。有两种最广泛使用的图处理应用类型:传统图计算(TGC),包括广度优先搜索(BFS)、页面排名(PR)等算法;以及图神经网络(GNN),如图卷积网络(GCN)和图注意力网络(GAT)。这些图处理算法在多种场景中得到了广泛应用,包括社交网络推荐[130]、知识图分析[79]、蛋白质预测[37]、视觉推理[117]等。为了应对图数据规模的指数级增长,这些算法日益受到欢迎,并广泛部署在各种数据中心,如谷歌地图[28]、微软学术图[46]、阿里巴巴电商平台[112]、百度地图[31]等。
图处理算法的执行面临着几个挑战,人们已经做出了许多努力来缓解这些问题。首先,在TGC算法中,执行行为,包括资源利用率和操作顺序等因素,往往表现出不规则性。这些不规则性源于图的不规则拓扑,导致不规则的工作负载、内存访问和通信[13]。为了解决这些挑战,提出了各种基于通用硬件平台(CPU & GPU)的框架,如GraphChi [55]和CuSha [54]。此外,还开发了定制的架构以进一步加速,如基于ASIC(Application-Specific Integrated Circuit)的Graphicionado [42],基于FPGA(Field Programmable Gate Array)的ForeGraph [25],以及基于PIM(Processing-In-Memory)的GraphR [89]。其次,GNN算法表现出不规则和规则执行行为的结合[107, 110],因为增加了神经网络(NNs)来转换每个顶点的高维特征向量。为了解决GNN中的正则和不规则特性,已经提出了几个专用的加速平台,如基于ASIC的HyGCN[108]和基于FPGA的GraphACT[118]。
图处理的执行严重依赖于一个关键操作——图预处理(GPP)。例如,GraphChi [55]、Graphicionado [42]、GraphDynS [109]、FPGP [24]和HyGCN [108]利用重组技术将图数据预分割为多个分片,以实现连续的内存访问并提高性能。在Pregel [74]、GraphLab [70]、DistDGL [132]和PaGraph [63]等并行图处理系统中,通过预先进行图划分,将大规模的图数据划分为多个子图,并将其分配给多个处理器/机器,实现负载均衡并最小化通信开销。为了促进GNN的并行高效训练,PaGraph [63]和DistDGL [132]使用采样技术创建小批量。GraphACT [118]和GCNInfer [120]预先合并共同邻居,以减少后续的冗余操作。因此,GPP对于高效执行图处理算法至关重要,有利于广泛的图处理系统,包括单机图处理框架、分布式图处理框架、图处理加速器等。为了提供清晰性,我们将一个典型的图处理系统抽象为两个主要步骤:图预处理(GPP)和图形式处理(GFP),如图2所示。在GPP步骤中,对原始图数据进行各种操作,以准备输入数据集,以便后续执行图处理算法。在GFP步骤中,计算单元加载预处理的数据,并执行图处理算法以获得最终结果。值得注意的是,GPP方法的选择取决于原始图数据集的特征以及执行平台。例如,在并行系统中,使用分区来管理大规模图数据,如使用CPU集群的DistDGL [132]和使用多GPU的PaGraph [63]。GraphACT [118]使用重构方法来减少FPGA上的冗余计算,从而实现高性能和能效。总体而言,GPP提供了两个主要好处:a)减少计算、存储和通信开销;b)满足各种算法在资源有限的设备上的执行需求。

不幸的是,由于图数据的爆炸性增长,GPP开销变得越来越重要。接下来,我们给出以下示例,通过数值比较来可视化GPP的重要性。在Graph500比赛1中,百亿级超级计算机Fugaku[81]展示了390秒的高GPP时间(C_TIME),与0.25秒的BFS执行时间相比,这是一个惊人的1560×。在Gorder [102]中,在一个大型Twitter数据集上进行图重排需要1.5小时,而PageRank仅在13.65分钟内完成了100次迭代。因此,如果输入图不经常重用,对于大型数据集来说,大量的GPP时间可能不是一个值得的投资。同样,在Graphite [38]中,当执行GraphSAGE时,采样时间占总训练时间的80%以上。这些示例突出了减少GPP开销以提高图处理系统的整体执行效率的重要性。基于上述分析,出现了两个重要结论,突显了GPP调查的迫切需求。首先,GPP对于高效的图处理至关重要。其次,GPP开销变得越来越显著和不可忽视,因此有必要降低GPP开销。因此,GPP领域具有巨大的潜力,需要进行更深入的研究,以充分探索GPP提供的优化可能性。然而,尽管有一些研究分析了单个GPP方法[2, 3, 21, 66],但缺乏对整个领域的GPP技术的全面综述。这一差距阻碍了对通过GPP实现的潜在优化的全面理解。在表1中,我们列出了图处理领域相关调查的列表,这些调查涉及GPP方法。一些调查既探讨了TGC加速技术,也探讨了GNN加速技术,其中一些涉及GPP方法。例如,对基于GPU和FPGA的TGC的调查[11, 88]涉及处理大型图的划分技术。其他工作[40, 45, 76, 83]分析了分布式系统和基于内存的图处理系统的静态和动态图划分。最近的调查[1, 16, 59, 62, 67, 86, 87, 97, 127]广泛地涵盖了GNN加速,并描述了GPP步骤在GNN执行中的意义。然而,这些调查仍然集中在分析GFP步骤的优化上,而GPP并不是他们的主要关注点。
为了充分利用GPP在图处理中的潜力,进行硬件和算法优化至关重要。然而,GPP中的硬件加速和算法优化之间存在差距。现有研究主要集中在GFP的硬件加速上,对GPP的关注有限,或者可能只在算法层面分析单个GPP技术。本文主要旨在通过提供系统和全面的GPP方法总结和分析来弥补这一差距,包括算法和硬件两个方面。我们很荣幸地提出了GPP方法的全面概述,旨在为GPP的进步做出贡献,并为该领域的进一步研究提供参考。我们的工作可能为GPP执行和图处理加速的未来优化提供有价值的见解。我们的贡献如下:综述:我们回顾了与图处理执行相关的挑战,考虑了计算、存储和通信方面的问题。我们通过相关示例强调了GPP对优化执行的重要意义。分类:我们对现有的GPP方法进行分类,并从算法和硬件的角度提出了一个双层分类。算法类别包括图表示优化和数据表示优化。硬件类别包括高效计算、存储和通信。分析:根据提出的分类,我们对现有的GPP方法进行了详细介绍。具体而言,我们从算法和硬件的角度列举和分析了相关工作。比较:我们综合考虑算法和硬件方面,对现有的GPP方法进行了全面的总结和比较,以便更好地了解它们的优势和劣势。讨论:我们讨论了与GPP相关的挑战,如高开销、准确性损失等。最后,我们概述了未来探索的潜在研究方向。
本文的其余部分组织如下:第2节提供了GPP的初步信息,涵盖了图概念和算法。第3节探讨了图处理的执行挑战,并展示了GPP如何解决这些挑战。第4节提出了基于算法优化因素和硬件优化效果的双层GPP分类。第5节和第6节分别从算法和硬件角度举例分析了GPP方法。第7节提供了全面的总结和比较。第8节讨论了普遍存在的GPP瓶颈和潜在的研究方向。最后,第9节总结了我们的工作。
2 图预处理:解决图处理中的挑战
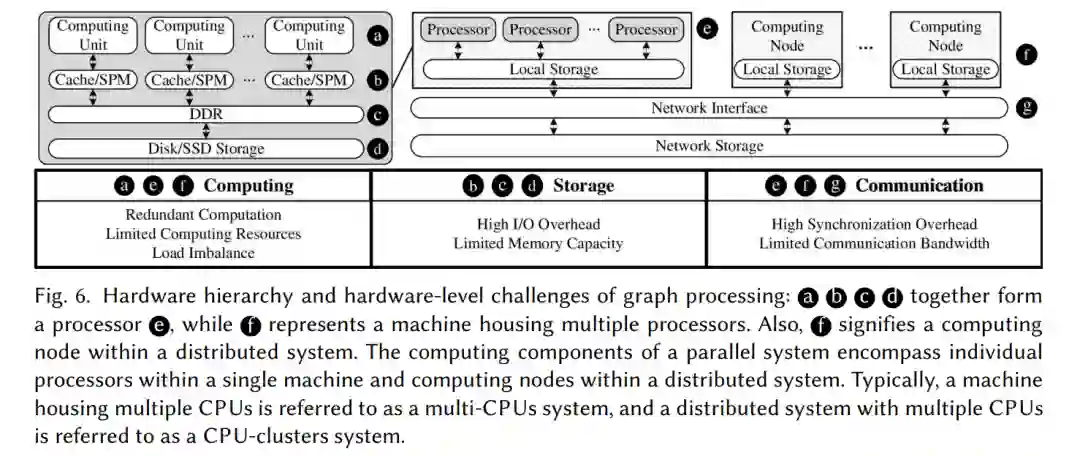
在本节中,我们将探索图处理执行中的硬件级挑战。通过探索这些挑战,强调了GPP方法在提高图处理性能方面的关键作用。我们从图特征概述开始,详细介绍了出现的不同执行行为。分析了来自这些行为的挑战,强调了GPP在解决这些问题以实现高效图处理方面的重要性。
图预处理:双层决策分类法
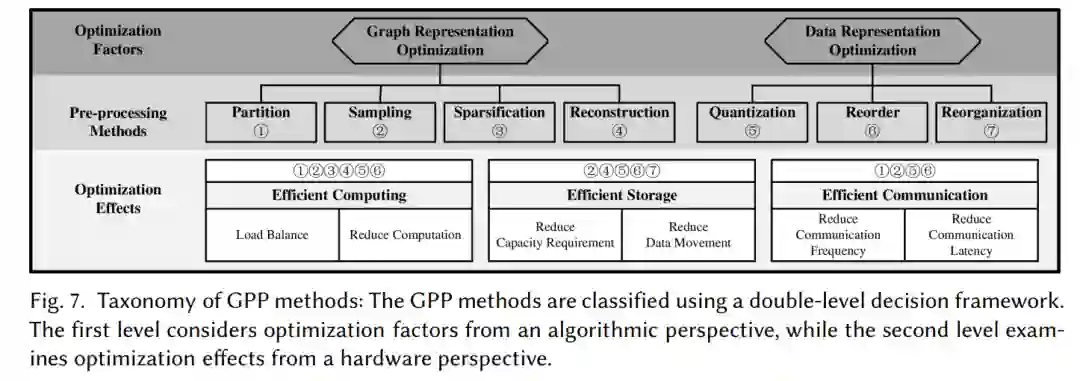
在本节中,我们将介绍一个全面的GPP方法分类,利用一个双层决策框架,如图7所示。在算法层面,根据优化因子的不同,将这7种方法分为图表示优化和数据表示优化。从硬件角度分析了GPP效应,将GPP方法分为高效计算、高效存储和高效通信3类;这个框架增强了理解。接下来,概述分类方法并解释分类背后的基本原理。
算法角度的分类(Taxonomy in Algorithmic Perspective)
图处理问题(GPP)涉及两种类型的输入图数据调整:图表示优化和数据表示优化。图表示优化通过改变图的拓扑结构或密度来提高图算法的性能,而数据表示优化则调整存储顺序或压缩数据精度。通过运用这两种优化方法,研究人员可以探索各种GPP方法,以在算法性能和准确性之间取得平衡,从而提高图算法执行的效率和有效性。
图表示优化:这一组包括分区、采样、稀疏化和重构技术。执行图处理算法时面临的挑战通常源于图结构的不规则性。这些GPP方法修改输入图的结构,以提高内存访问和算法执行效率。值得注意的是,分区、采样和稀疏化可能导致信息丢失,这可能潜在地影响准确性。相比之下,重构仅改变拓扑结构,而不影响算法的最终结果。
数据表示优化:这一组包括量化、重新排序和重新组织技术。与图表示优化方法不同,这些技术不改变图的拓扑结构,而是专注于调整数据存储。然而,量化降低了数据的精度,引入了准确性和执行效率之间的权衡。另一方面,重新排序和重新组织主要调整数据访问模式,以提高性能,而不影响算法的最终结果。
硬件视角下的分类(Taxonomy in Hardware Perspective)
考虑到第三节中突出的挑战和优化目标,图处理问题(GPP)在三个方面提供了优化图算法执行的机会:高效计算、高效存储和高效通信。通过有效管理计算负载,优化图处理系统的性能和资源利用率。
高效计算:从两个角度来提高计算效率:负载均衡和计算减少。首先,负载均衡确保了计算工作在资源之间均匀分布,最大化它们的利用率,避免过载计算资源。其目标是有效利用可用的计算单元,从而提高性能。其次,通过最小化计算量(包括减少冗余计算和数据量)可以减少计算开销。用于高效计算的GPP方法包括分区、采样、稀疏化、重构、量化和重新排序。
高效存储:可以通过减少容量需求和减少数据移动来实现。首先,为了减少容量需求,需要减少片上缓冲的数据量,从而减少I/O开销。一个有效的方法是减少总体数据量。其次,最小化数据移动可以显著提高内存访问带宽的利用率。通过有效管理存储资源并优化数据移动,存储效率可以得到提高,从而提高整体性能和资源利用率。用于高效存储的GPP方法包括采样、重构、量化、重新排序和重新组织。
高效通信:可以通过减少通信频率或延迟来实现。首先,通过减少通信频率,可以最小化计算组件的同步开销,包括单台机器中的处理器和分布式系统中的计算节点。提高数据局部性是一种减少组件之间数据交换需求的有用方法。其次,减少通信延迟意味着充分利用通信带宽。一种有效的方法是减少不规则和冗余的通信请求。用于高效通信的GPP方法包括分区、采样、量化和重新排序。
