生成模型作为统计建模的一个重要家族,其目标是通过生成新实例来学习观察到的数据分布。随着神经网络的兴起,深度生成模型,如变分自编码器(vais)和生成对抗网络(GANs),在二维图像合成方面取得了巨大的进展。近年来,由于三维数据与我们的物理世界更接近,在实践中具有巨大的潜力,研究者们将研究的重点从二维空间转向了三维空间。然而,与2D图像不同的是,2D图像本质上拥有高效的表示(即像素网格),表示3D数据可能面临更多的挑战。具体地说,我们希望理想的3D表示能够足够详细地建模形状和外观,并且能够高效地建模高分辨率数据,速度快,内存成本低。然而,现有的三维表示方法,如点云、网格和最近的神经场,通常不能同时满足上述要求。在本文中,我们从算法和更重要的表示两方面对3D生成的发展进行了全面的回顾,包括3D形状生成和3D感知图像合成。我们希望我们的讨论可以帮助社区跟踪这一领域的发展,并进一步激发一些创新的想法来推进这一具有挑战性的任务。
https://www.zhuanzhi.ai/paper/494ecc28feabb3aeaade6da6523b430f
概述
深度学习[1]的快速发展显著推进了计算机视觉领域的许多任务,如视觉物体识别[2]、[3]、物体检测[4]、[5]、[6]、图像渲染[7]、[8]、[9]等,并在许多方面促进了我们的日常生活,如自动驾驶[10]、[11]、生物研究[12]、智能创造[13]、[14]。在所有类型的技术中,生成建模[15],[16],[17]在数据分析和机器学习中扮演着重要的角色。与直接对输入进行预测的判别模型不同,生成模型旨在通过创建新实例来再现数据分布。为此,需要对数据进行全面的描述。例如,一个检测模型可以忽略与任务无关的信息(例如,颜色)而不牺牲性能,但是生成模型被期望管理图像的每一个细节(例如,对象排列以及每个对象的纹理),以获得令人满意的生成。从这个角度来看,学习生成模型通常更具挑战性,但促进了一系列应用[14],[18],[19],[20]。
在过去的几年里,深度生成模型[15],[16],[17]在2D图像合成中取得了不可思议的成功[14],[21],[22]。尽管公式不同,变分自编码器(vais)[16]、自回归模型(ARs)[23]、归一化流(NFs)[24]、生成对抗网络(GANs)[15]和最新的扩散概率模型(DPMs)[17]都能够将潜在变量转换为高质量图像。然而,如今二维空间中的学习生成模型已经不能满足一些现实应用的需求,因为我们的物理世界实际上位于3D空间之下。以电影行业为例,我们希望设计3D数字资产,而不是简单地生产2D图像,带来沉浸式的体验。现有的内容创建管道通常需要大量的专业知识和人力,这可能是耗时和昂贵的。在研究如何自动生成3D数据a1方面,已经进行了许多开拓性的尝试[25],[26],[27],[28],[29],[30],但这类研究仍处于早期阶段。
2D生成和3D生成之间的一个关键区别是数据格式。具体来说,二维图像可以自然地表示为像素值的数组,神经网络[2]、[3]可以方便地处理这些像素值。相反,有许多3D表示来描述一个3D实例,如点云[31],[32],网格[33],[34],体素网格[35],[36],多平面图像[37],隐式神经表示[9]等。每种表示都有其优点和局限性。例如,网格紧凑地表示3D形状,但由于数据结构不规则,神经网络很难分析和生成。相比之下,体素网格有规律地位于三维空间中,与标准卷积神经网络工作良好,但体素网格消耗内存,难以表示高分辨率3D场景。因此,选择合适的表示形式对于3D内容生成至关重要。
鉴于3D生成模型的快速发展,文中对该领域进行了全面的综述,以帮助社区跟踪其发展。我们想提到的是,在文献中已经有一些调查研究生成模型[38],[39],3D视觉[40],[41],[42],[43],以及3D结构[44]和面孔[45]的生成,但仍然缺少对3D生成的全面回顾。如前所述,要完成这样一项具有挑战性的任务,有许多候选算法(如vais和GANs)和表示(如点云和隐式神经表示)可供选择。这个调查有助于理清不同类型的生成模型如何适用于不同的表示。我们将本文的其余部分组织如下。第二节阐明了这项综述的范围。第三节介绍了3D生成任务的基本原理,包括各种生成模型的公式和流行的3D表示。第4和第5节分别总结了现有的3D形状生成方法和3D感知图像合成方法。第6节讨论了3D生成模型的下游应用。第7节提供了3D生成领域的未来工作。
本综述范围
在本研究中,我们重点研究训练网络对目标三维样本的数据分布进行建模的方法,并支持三维表示合成的采样。我们还包括基于某些输入(如图像、部分点云或文本句子)预测条件概率分布的方法。请注意,这些条件生成方法旨在合成尊重输入的3D表示,同时保持生成多样性。这与经典的三维重建方法形成对比,后者建立从输入到目标三维表示的一对一映射。我们建议读者参考[40]、[46]对这些方法的综述。虽然我们的综述包括生成3D表示的方法,但我们没有完全覆盖神经渲染方法,[40]和[47]中已经详细讨论过。该综述是对现有的生成模型[38],[39],[44]的调查的补充。
基础模型
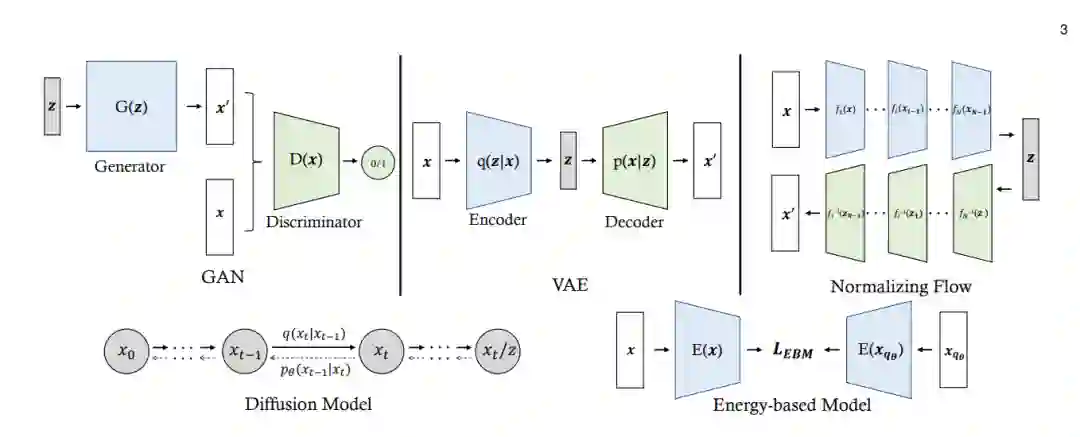
生成式模型旨在以一种无监督的方式了解实际的数据分布,通过尝试从给定的信息中生成尽可能真实的数据,从而捕获更多的细节并显示出更多的创造力。具体来说,首先需要生成模型来总结输入数据的分布,然后利用生成模型在给定的数据分布中创建或合成样本。一般来说,生成模型可以分为两大类。一种是基于似然的模型,包括变分自编码器(ves)[16],归一化流(N-Flows)[24],扩散模型(DDPMs)[17]和基于能量的模型(EBMs)[48],这些模型是通过最大化给定数据的似然来学习的。另一种是无似然模型,包括生成对抗网络(GANs)[15],它建立在两名玩家的最小最大博弈之上,以寻找纳什均衡。下面,我们将简要回顾不同类型的生成模型。图1显示了每个生成模型的一般概念。
计算机视觉和计算机图形社区已经开发了各种3D场景表示,包括体素网格、点云、网格和神经场。这些表示在三维形状生成和三维感知图像合成任务中表现出各自的优点和缺点。例如,与结构良好的2D图像相比,大多数3D表示都不是常规格式,不能用标准cnn直接处理。3D体素网格通常是规则的,这使得它能够很好地与3D卷积网络一起工作。然而,体素网格往往消耗内存,因此难以表示高分辨率的形状。神经场理论上支持高分辨率形状建模,但训练过程中对隐式表示的有效监督是一个有待解决的问题。
三维形状生成
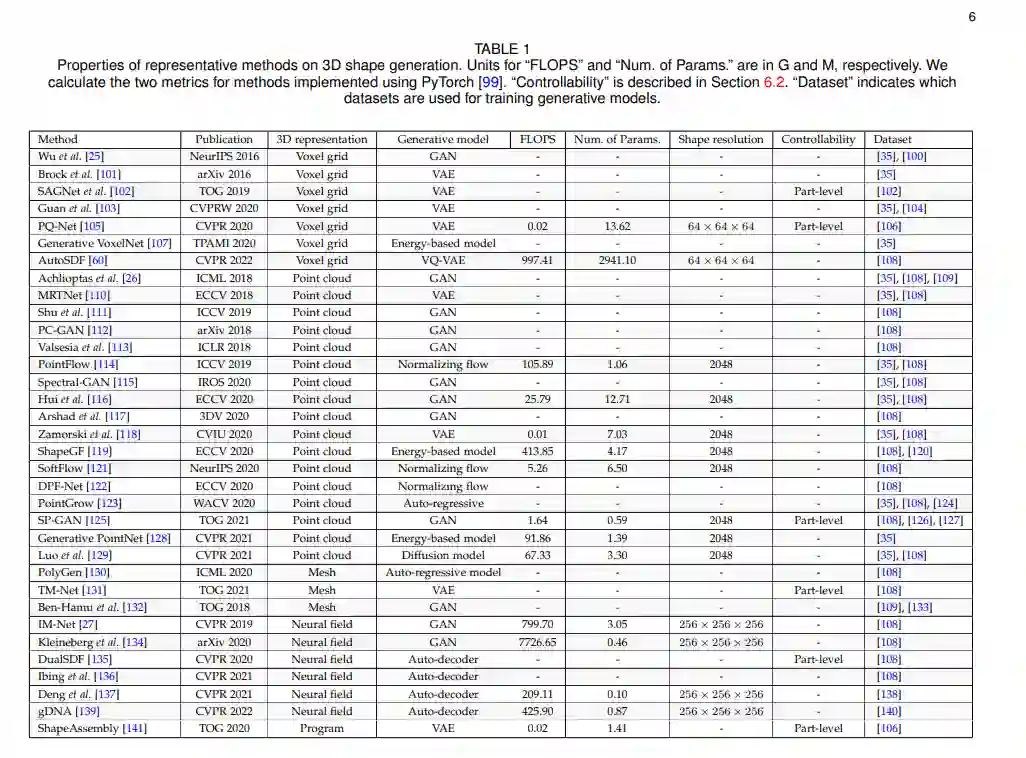
目前,大多数三维形状生成方法都是训练深度神经网络来获取三维形状的分布。与2D图像相比,3D形状有许多类型的表示,如体素网格、点云、网格和神经场。这些表示方法在三维形状生成任务中各有优缺点。评估3D表示是否能与深度生成模型很好地工作,可以考虑很多方面,包括网络处理表示的容易程度,允许高效生成高质量和复杂的3D形状,以及生成模型获取监督信号的成本。表1总结了三维形状生成的代表性方法。
三维感知图像生成
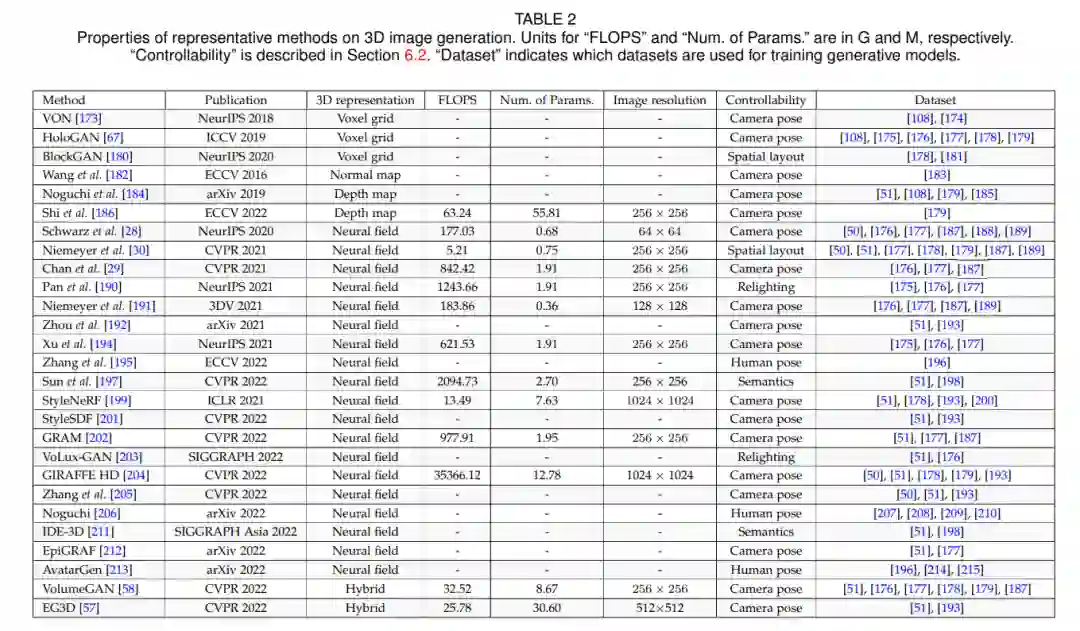
三维感知图像生成的目标是在合成图像时显式地控制相机的视点。基于二维gan的模型[217],[218],[219],[220],[221]通过发现与视点轨迹相对应的潜在空间方向来实现这一目标。尽管它们提供了令人印象深刻的结果,但在潜在空间中找到一个合理的方向并不容易,通常不能支持渲染视点的完全控制。本研究的重点是为三维图像合成明确生成三维表示的工作。与直接用形状训练的3D形状生成方法相比,大多数3D感知的图像生成方法都是通过可微神经渲染的图像来监督的,因为通常没有高质量和大规模的可渲染的3D表示数据集来训练生成模型。由于缺乏可渲染的3D表示,自动编码器架构在此任务中很少使用。大多数方法采用生成对抗模型,从潜在空间中提取潜在向量并将其解码为目标表示。
6 应用
3D生成模型的兴起使许多有前途的应用成为可能,如图12所示。在本节中,我们将讨论3D生成模型在编辑、重建和表示学习方面的应用。

7 未来的工作
3D生成模型的发展非常迅速,但在将其用于下游应用程序(如游戏、模拟和增强/虚拟现实)之前,仍有许多挑战需要克服。在这里,我们讨论了3D生成模型的未来发展方向。
通用性:大多数现有的3D生成模型都是在简单的对象级数据集上进行训练的,例如,用于3D形状生成的ShapeNet和用于3D感知图像合成的FFHQ。我们认为,将3D生成模型扩展到更大程度的通用性是未来研究的一个富有成效的方向。它的通用性包括生成通用对象(如ImageNet或Microsoft CoCo)、动态对象或场景以及大规模场景。与其专注于单一类别,不如学习一种通用的3D生成模型,用于各种类别,如DALL-E2和Imagen[257],[258]和无限3D场景[259],这是非常有趣的。
可控性:3D生成模型的可控性落后于2D生成模型。理想情况下,用户应该能够通过用户友好的输入控制3D生成过程,包括但不限于语言、草图和程序。此外,我们认为物理特性的可控性应该进一步研究,包括照明,材料,甚至动力学。
效率:许多3D生成模型需要在多个高端gpu上进行3-10天的训练,并且在推理过程中速度较慢。我们认为,提高三维生成模型的训练效率是必要的,而提高推理效率对于下游应用至关重要。
训练稳定性:3D生成模型的训练,特别是3D感知的图像合成模型,通常更容易发生模式崩溃。一种可能的解释是,物理上有意义的因素的分布,例如相机姿势和渲染参数,可能与真实图像不匹配。因此,研究生成模型的训练稳定性就显得尤为重要。