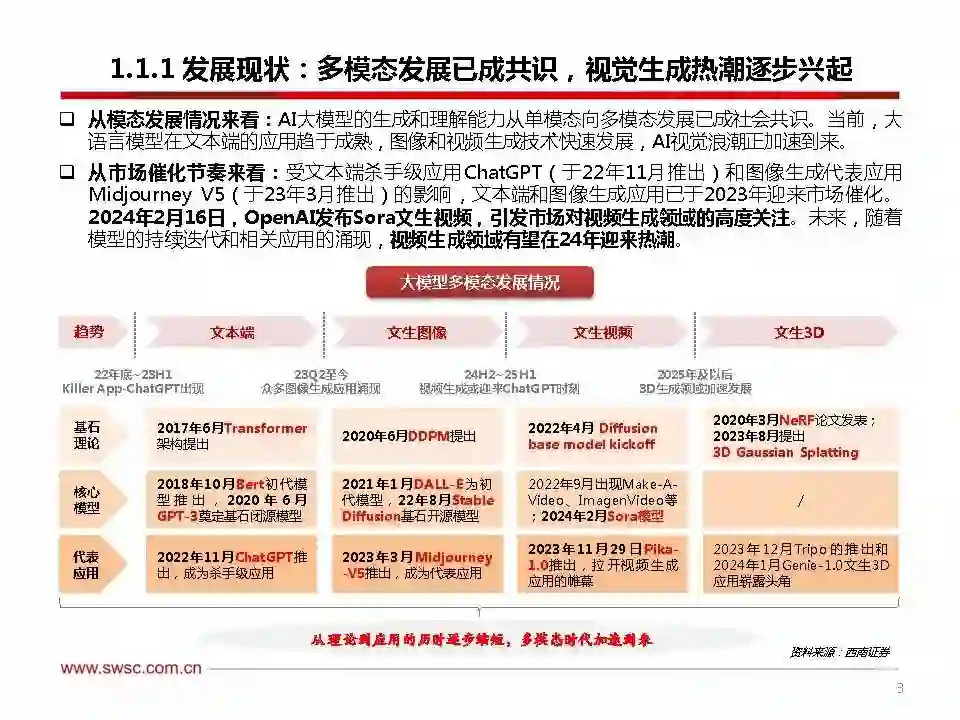
核心观点 事件:2024年2月16日,OpenAI发布文生视频模型——Sora及其技术报告《Video generation models as world simulators》。 从Sora模型看文生视频的技术路径:技术路径尚未收敛,Transformer扩展特性优势凸显。市场大多认为扩散模型是图像和视频生成领域的主流路径,但没有重视Transformer架构scaleup的能力。OpenAI技术报告指出,Sora是基于扩散模型,但更强调,Sora是一个基于Transformer架构的扩散模型,其优秀的生成能力离不开Transformer架构优秀的scaling特性。当前,为构建性能更优、效率更高的视频生成模型,已出现多种结合Diffusion Model和Transformer架构的构建方式。 从Sora模型看文生视频的最新能力(假设展示视频可以代表Sora的一般性表现):1)强大的理解能力:Sora模型不仅可以理解Prompt的内容,还能理解事物在物理世界中的存在方式,突出的语言理解能力是其能够准确生成视频的前提。2)优秀的生成能力:①长度:可生成60s视频;②复杂度:能够生成包含多个角色、多种主题、多类运动形态的复杂场景;③逼真度:能够呈现更多的视觉细节,具备更高清的画质,为用户提供逼真的视觉体验;④连贯性&一致性:可以生成同一角色的多个镜头,保持其在整个视频中的外观,在角度移动和切换情况下,人物和场景元素在三维空间中的位置关系能够保持一致的运动;⑤可控性:在某一Prompt基础上只改动一个关键词仍能生成优质的视频,具备较好的可控性。3)其他能力:图生视频,视频扩展/编辑/拼接/模拟等。 从Sora模型看文生视频的行业影响:目前OpenAI已向部分视觉艺术家、设计师和电影制作人提供访问权限,以获取专业的反馈。我们认为,以Sora为代表的视频生成模型有望给广告/设计/短视频/游戏等行业带来变化。从中短期来看,视频生成模型将更多的作为创作工具对相关行业进行赋能。