
来源| 麻省理工学院
编辑| 专知翻译整理
机器学习模型能否克服有偏置的数据集?
研究人员报告说,模型的泛化能力受数据多样性和模型训练方式的影响。
Nature Machine Intelligence:When and how convolutional neural networks generalize to out-of-distribution category–viewpoint combinations(卷积神经网络何时以及如何推广到非分布的分类视点组合)

人工智能系统或许能够快速完成任务,但这并不意味着它们总是公平地完成任务。如果用于训练机器学习模型的数据集包含有偏置的数据,那么系统在实践中做出决策时可能会表现出同样的偏置。
例如,如果数据集主要包含白人男性的图像,那么使用这些数据训练的面部识别模型对于女性或具有不同肤色的人来说可能不太准确。
麻省理工学院的一组研究人员与哈佛大学和富士通有限公司的研究人员合作,试图了解机器学习模型何时以及如何能够克服这种数据集偏差。他们使用神经科学的一种方法来研究训练数据如何影响人工神经网络是否能够学会识别它以前从未见过的物体。神经网络是一种机器学习模型,它模仿人脑的方式,其中包含处理数据的互连节点或“神经元”层。
新结果表明,训练数据的多样性对神经网络是否能够克服偏差有重大影响,但同时数据集的多样性会降低网络的性能。他们还表明,神经网络是如何训练的,以及在训练过程中出现的特定类型的神经元,可以在它是否能够克服有偏置的数据集方面发挥重要作用。
“神经网络可以克服数据集偏差,这是令人鼓舞的。但这里的主要内容是我们需要考虑数据的多样性。我们需要停止认为,如果您只收集大量原始数据,那您就会有所收获。我们首先需要非常小心地设计数据集,”大脑与认知科学系 (BCS) 和大脑、思维和机器中心 (CBMM) 的研究科学家 Xavier Boix 说,并且论文的高级作者。
合著者包括前麻省理工学院研究生 Timothy Henry、Jamell Dozier、Helen Ho、Nishchal Bhandari 和目前正在哈佛大学攻读博士学位的通讯作者 Spadan Madan;Tomotake Sasaki,前访问科学家,现为富士通研究院高级研究员;Frédo Durand,麻省理工学院电气工程和计算机科学教授,计算机科学与人工智能实验室成员;Hanspeter Pfister,哈佛工程与应用科学学院计算机科学系教授。该研究今天发表在Nature Machine Intelligence上。
01 像神经科学家一样思考
Boix 和他的同事通过像神经科学家一样思考来解决数据集偏差问题。Boix 解释说,在神经科学中,通常在实验中使用受控数据集,这意味着研究人员尽可能多地了解其中包含的信息的数据集。
该团队构建了包含不同姿势的不同物体图像的数据集,并仔细控制了组合,因此一些数据集比其他数据集更具多样性。在这种情况下,如果数据集包含更多仅从一个角度显示对象的图像,则数据集的多样性会降低。一个更多样化的数据集有更多的图像显示来自多个视点的对象。每个数据集包含相同数量的图像。

研究人员使用这些精心构建的数据集来训练用于图像分类的神经网络,然后研究它能够从网络在训练期间没有看到的视点识别物体的能力(称为分布外组合)。
例如,如果研究人员正在训练模型以对图像中的汽车进行分类,他们希望模型能够了解不同汽车的外观。但是,如果训练数据集中的每一个福特雷鸟都是从正面显示的,那么当训练模型得到一张从侧面拍摄的福特雷鸟图像时,即使它是在数百万张汽车照片上训练的,它也可能会对其进行错误分类。
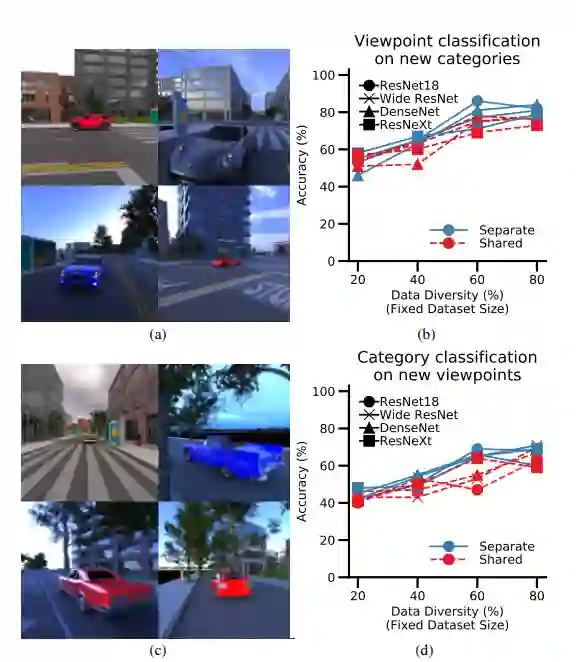
研究人员发现,如果数据集更加多样化——如果更多图像显示来自不同视点的对象——网络能够更好地泛化到新图像或视点。Boix 说,数据多样性是克服偏置的关键。
“但这并不是说更多的数据多样性总是更好;这里有一种张力。当神经网络在识别它没有看到的新事物方面变得更好时,它就会变得更难识别它已经看到的事物,”他说。
02测试训练方法
研究人员还研究了训练神经网络的方法。
在机器学习中,训练网络同时执行多个任务是很常见的。这个想法是,如果任务之间存在关系,如果网络一起学习它们,它将学会更好地执行每个任务。
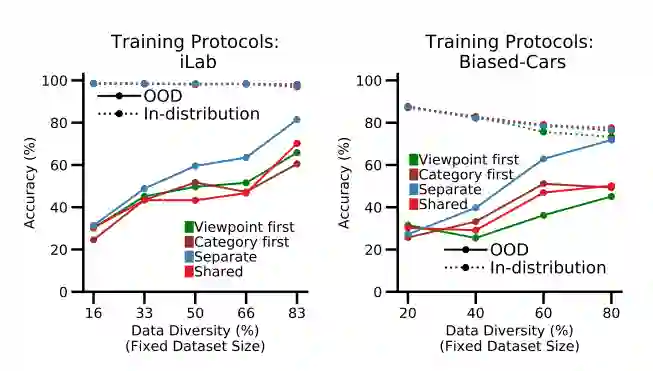
“结果真的很惊人。事实上,我们第一次做这个实验的时候,还以为是bug。我们花了几个星期才意识到这是一个真正的结果,因为它太出乎意料了,”他说。
他们深入研究了神经网络,以了解为什么会发生这种情况。
他们发现神经元特化似乎起了主要作用。当神经网络被训练识别图像中的物体时,似乎出现了两种类型的神经元——一种专门识别物体类别,另一种专门识别视点。
Boix 解释说,当网络被训练为单独执行任务时,那些专门的神经元会更加突出。但是,如果一个网络被训练为同时完成这两项任务,一些神经元就会被稀释,不会专门从事一项任务。他说,这些非特化神经元更容易混淆。
“但现在的下一个问题是,这些神经元是如何到达那里的?你训练神经网络,它们从学习过程中出现。没有人告诉网络在其架构中包含这些类型的神经元。这是令人着迷的事情,”他说。
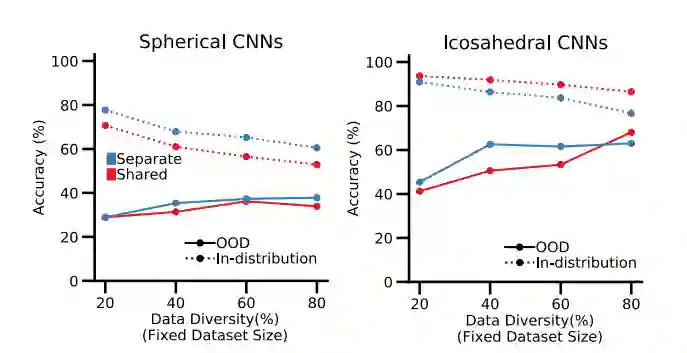
Boix 对神经网络可以学会克服偏置感到鼓舞,他希望他们的工作能够激发其他人对他们在 AI 应用程序中使用的数据集更加深思熟虑。
这项工作得到了国家科学基金会、谷歌学院研究奖、丰田研究所、大脑、思想和机器中心、富士通研究中心和麻省理工学院-Sensetime 人工智能联盟的部分支持。
03 成果在顶级期刊【Nature Machine Intelligence】发表

标题
When and how CNNs generalize to out-of-distribution category-viewpoint combinations 作者 Spandan Madan, Timothy Henry, Jamell Dozier, Helen Ho, Nishchal Bhandari, Tomotake Sasaki, Frédo Durand, Hanspeter Pfister, Xavier Boix
摘要
对象识别和视点估计是视觉理解的核心。最近的研究表明,卷积神经网络 (CNN) 无法推广到分布外 (OOD) 类别 - 视点组合,即在训练期间看不到的组合。在这里,我们通过评估训练来分类对象类别和 OOD 组合的三维视点的 CNN,并确定促进这种 OOD 泛化的神经机制,研究何时以及如何实现这种 OOD 泛化。我们表明,即使使用相同数量的训练数据,增加分布内组合(数据多样性)的数量也会显着提高对OOD 组合的泛化能力。我们比较分离和共享网络架构中的学习类别和观点,并观察在分销和 OOD 组合上截然不同的趋势,也就是说,虽然共享网络有助于分销,但在 OOD 组合中,单独的网络明显优于共享网络。最后,我们证明了这种 OOD 泛化是由特化的神经机制促进的,即两种类型的神经元的出现——对类别有选择性的神经元和对视点保持不变的神经元,反之亦然。
paper
https://arxiv.org/pdf/2007.08032.pdf
code
https://github.com/Spandan-Madan/generalization_biased_category_pose



