在这份报告中,我们提出了一种数据驱动的方法,用于实验室技术载具的闭环控制。我们使用近似策略优化(PPO)算法,这是一种强化学习算法,已被证明在各种任务中表现良好。PPO的成功是由于它在寻找解决方案方面的稳定性,此外还具有策略梯度方法的许多积极特性。虽然PPO在整个文献中被证明是成功的,但在奖励稀疏的情况下,它确实受到了影响;这恰好是我们的精确弹药应用的情况,其目标是击中一个特定目标。为了解决这个稀疏奖励的问题,我们提出了一个围绕PPO的课程学习方法。该课程将学习分为几个阶段,这些阶段的复杂度逐渐增加,缓解了奖励信号的稀疏性。所提出的方法被证明优于没有课程的学习方法。


1 引言
最近,用于自主系统的引导、导航和控制的数据驱动方法已经得到了普及。这要归功于机器学习的最新进展,特别是深度学习和人工神经网络。强化学习(RL)是深度学习的一种类型,旨在利用与环境的互动来学习从环境状态到代理行动的适当映射,从而使所需的输出最大化。这个程序的灵感来自于自然过程,因为大多数生物系统通过大量的行动和随后的反馈来学习在其环境中的操作。在RL中,来自环境的反馈被称为奖励信号。系统试图调整输入以最大化这个期望的奖励信号。系统的输入被定义为代理行动,而状态和奖励是从环境中观察到的。这些收集的数值被用来驱动学习过程。在这项工作中,我们提出了一种RL方法来开发一个远程精确武器的闭环控制方案。我们在本报告中使用的数据驱动的方法是基于近似策略优化(PPO)RL算法的。
快速发展的机器学习行业导致了RL的新进展,使新颖的、数据驱动的方法能够用于控制开发。即使是高度密集的输入,如图像帧,也可以推断出行动,使性能最大化。很多时候,这种方法使闭环控制更加直接,如在基于视觉的系统中,基于图像的算法将不必与控制分开独立开发。这种非常规的方法与传统的控制器设计相反,它是一种基于模型的方法,依赖于系统模型的近似。由于参数的不确定性和/或系统的非线性而做出的近似,往往阻碍了基于模型的方法,导致控制器性能不足或保守的控制器。例如,自主特技飞行是一个具有挑战性的控制问题,因为它需要在飞行包络线的边缘进行精确控制。尽管传统的、基于模型的方法在面对不相干的情况时可能表现不佳,但它们确实对已知的操作领域提供了宝贵的性能保证,使它们通常是安全的和可预测的。另外,无模型方法需要较少的模型开发和调整来得出闭环控制。纯粹的数据驱动,无模型方法可以学习系统的复杂性,甚至可以扩展使用的代理数量。然而,他们需要更多的数据,而且控制设计中的性能保证可能更难实现。
RL方法得益于环境的简化,如奖励的塑造或行动空间和状态的离散化,以实现更快的学习。在经典的RL任务中,可以同时收集行动和奖励,以不断调整策略和最大化奖励。现实世界的问题很少以允许这种方式提出。例如,当训练一个自主代理找到一个迷宫的尽头时,在每个时间步骤中,没有迹象表明代理正在对系统应用正确的行动,直到它达到时间范围或目标。这些类型的问题注定要用稀疏的奖励信号来定义。为了帮助使用稀疏奖励的学习,设计者可以塑造奖励以持续提供反馈。这种成型的奖励有一个缺点,即无意中支配了闭环控制的解决方案,减少了通过允许代理不定向探索而获得的紧急解决方案的机会。然而,当有广泛的领域知识可供利用时,这种方法仍有其优点。好奇心驱动的方法采取相反的方法,鼓励对不为人知的领域进行探索。这已被证明在许多环境中是有效的,因为好奇心是唯一的奖励信号。另一种方法是将系统结构化,使其逐步学习更难的任务以获得期望的目标。这被称为课程学习,其中课程是系统必须逐步学习的逐渐困难的任务的集合。这里的想法是,当任务容易时,奖励会在开始时更频繁地出现,为RL算法提供有价值的反馈,以用于调整其控制器。
2 问题
RL已经在许多空间得到了实现,包括医疗、社会和工程应用。在本报告中,我们应用RL来控制一个智能弹药。以前关于导弹制导的RL的工作利用奖励塑造方法来克服稀疏的奖励问题。如前所述,这种方法可能导致系统不探索对设计者来说不直观的路径。由于弹丸的高度不确定性和非线性动力学,自主弹药制导、导航和控制是一项艰巨的任务。由于在估计视线率和走时方面的挑战,比例导航可能难以实现。
比例导航是基于线性化的啮合几何,这可能不适合于整个轨迹。这常常导致从 "中途 "制导法和 "终点 "制导法转换的临时决定点。估计方面的一些困难来自于系统的非线性,这迫使控制设计者对系统进行近似和线性化。一些用于射弹控制的系统使用飞行方程的数值微分,这导致控制决策是基于由噪声测量产生的可能错误的状态。数据驱动的方法对这些系统可能是有利的。然而,由于稀疏的奖励信号,机器学习过程非常困难。
2.1 贡献
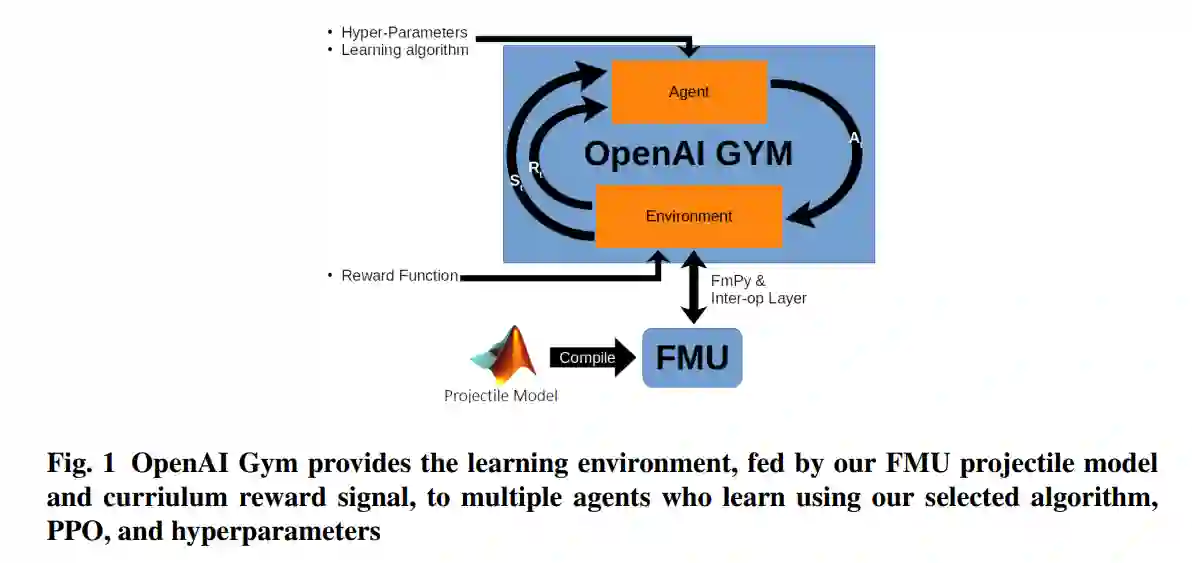
在这份报告中,我们提出了一种将RL应用于智能射弹的闭环控制这一难题的方法。我们设计了一个OpenAI gym环境,其中嵌入了一个功能模拟单元(FMU)模型,以密切模拟真实的射弹。因此,由于寻找有用的控制策略所需的探索任务的规模,这个问题比经典的RL任务更加困难。这里的状态包括位置、速度和与目标的距离。输入动作是在身体框架的水平和垂直方向上的加速指令。由于我们的问题中存在稀疏的奖励,因此实施了一种课程学习方法,其中课程的各个阶段与从大到小的 "目标 "尺寸一致。我们通过实验表明,通过这个系统,我们可以学会驾驶智能弹药并精确地击中目标。
2.2 组织
我们在第3节中介绍了我们的环境模拟,在第4节中提供了PPO算法的概述,在第5节中介绍了我们的课程学习方法,在第6节中给出了训练的概述,然后在第7节中介绍了我们的结果。