完全依靠自主系统的技术在推动海底领域的环境研究方面发挥了重要作用。无人潜水器(UUV),如美海军研究生院的UUV研究平台,在推进用于研究目的的自主系统的技术水平方面发挥了作用。使用自主系统进行研究正变得越来越流行,因为自主系统可以将人类从重复性的任务中解脱出来,并减少受伤的风险。此外,UUVs可以以相对较低的成本大量制造。此外,由于计算和电池技术的进步,UUVs可以在没有人类干预的情况下承担更多的扩展任务。
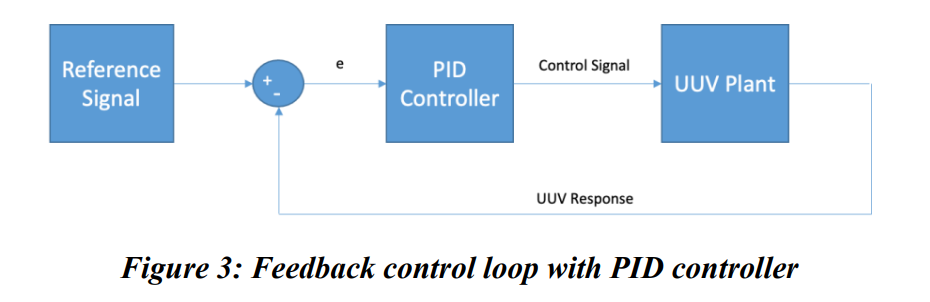
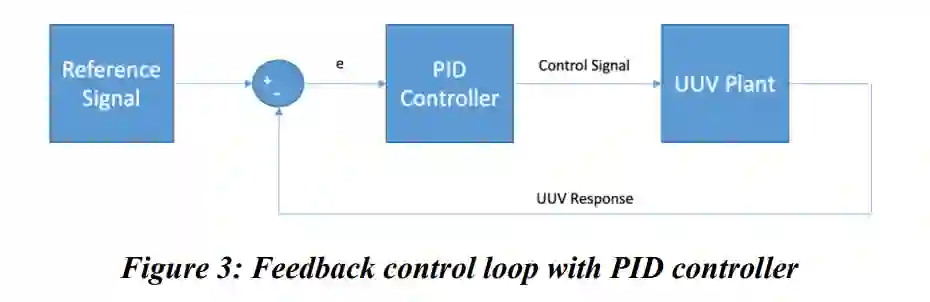
UUV的重要部分之一是控制系统。UUV控制系统的配置可能会根据车辆的有效载荷或环境因素(如盐度)而改变。控制系统负责实现和保持在目标路径上的稳定飞行。PID控制器在UUV上被广泛实施,尽管其使用伴随着调整控制器的巨大成本。由于两个主要问题,陡峭的成本并不能提供稳健或智能解决方案的好处。
第一个问题是,PID控制器依赖于复杂的动态系统模型来控制UUV。动态系统模型有简化的假设,使控制问题得到有效解决。当假设不成立时,PID控制器可以提供次优的控制,甚至会出现完全失去控制的情况。第二个问题是,PID控制器并不智能,不能自主学习。PID控制器需要多名工程师和其他人员花数天时间收集和分析数据来调整控制器。调整PID控制器是一项手动任务,会带来人为错误的机会。
在使用深度强化学习方法进行自主车辆控制系统方面,有很多正在进行的研究,并且已经显示出有希望的结果[1,2]。深度强化学习控制器已被证明优于执行路径跟踪任务的UUV的PID控制器[3]。此外,与PID控制器相比,基于深度强化学习的控制器已被证明能够为无人驾驶飞行器(UAVs)提供卓越的姿态控制[4-5]。虽然这个例子不是专门针对UUV的,但这个来自空中领域的概念可以转化到海底领域。
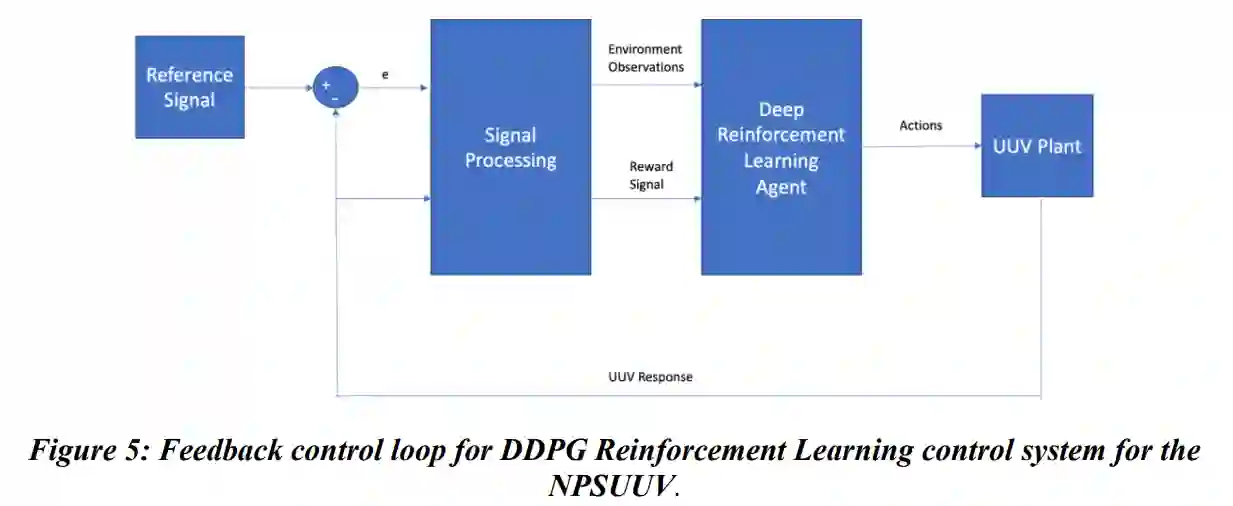
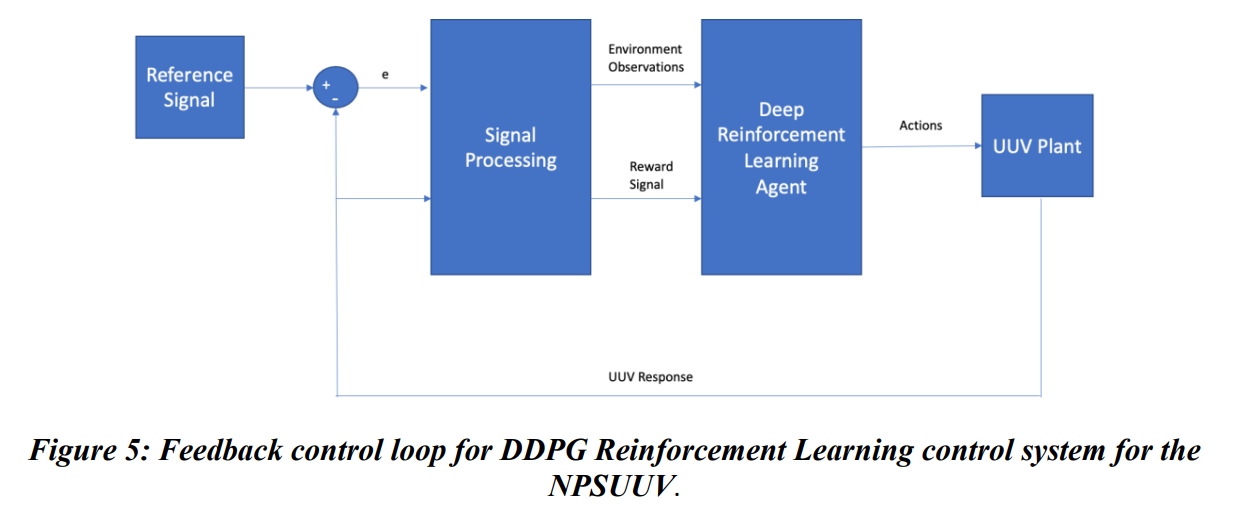
一些最流行的深度强化学习算法被用于自主车辆控制系统的开发,包括近似策略优化(PPO)[6]和深度确定策略梯度(DDPG)[7]算法。本研究将重点关注DDPG算法。DDPG算法是一种角色批判型的深度强化学习算法。Actor-Critic算法同时学习策略和价值函数。Actor-Critic算法的概念是:策略函数(演员)根据当前状态决定系统的行动,而价值函数(批评家)则对行动进行批评。在深度强化学习中,政策和价值函数是由DNNs近似的,在本研究中具体是多层感知器(MLPs)。
与UUV的传统PID控制器相比,基于DDPG算法的深度强化学习控制器有两个主要好处。第一个好处是,DDPG算法是无模型的。它不需要任何关于车辆或环境动态的知识来提供最佳控制。因此,它避免了有效解决复杂的车辆或环境动态系统模型所需的简化假设的弊端。其次,基于深度强化学习的控制系统可以被自主地调整(训练)。与PID控制系统相比,这将减少调整基于深度强化学习的控制系统所需的资源。
与UUV的传统PID控制器相比,基于DDPG算法的深度强化学习控制器有两个主要好处。第一个好处是,DDPG算法是无模型的。它不需要任何关于车辆或环境动态的知识来提供最佳控制。因此,它避免了有效解决复杂的车辆或环境动态系统模型所需的简化假设的弊端。其次,基于深度强化学习的控制系统可以被自主地调整(训练)。与PID控制系统相比,这将减少调整基于深度强化学习的控制系统所需的资源。
在利用降低精度来提高强化学习的计算效率方面,目前的研究很有限。[11]的作者展示了如何使用量化技术来提高深度强化学习的系统性能。文献[12]的作者展示了一种具有6种方法的策略,以提高软行为批评者(SAC)算法低精度训练的数值稳定性。虽然正在进行的研究集中在基准强化学习问题上,但这一概念在科学应用上相对来说还没有被开发出来,比如使用深度强化学习代理对UUV进行连续控制。
本研究将证明在混合精度和损失比例的情况下,训练DDPG代理对UUV的连续控制不会影响控制系统的性能,同时在两个方面使解决方案的计算效率更高。首先,我们将比较用固定和混合数值精度训练的DDPG代理的性能与1自由度速度控制问题的PID控制器的性能。我们将研究用固定和混合精度训练DDPG代理的训练步骤时间。其次,本研究将研究DNN大小和批量大小的阈值,在此阈值下,用混合精度训练DDPG代理的好处超过了计算成本。
本文的其余部分结构如下。问题表述部分将提供关于DDPG算法、NPSUUV动力学、PID控制和混合数值精度的简要背景。实验分析部分将描述本研究中运行的数值实验的设置和结果。最后,在结论和未来工作部分将描述整体工作和未来计划的工作。