

神经压缩是将神经网络和其他机器学习方法应用于数据压缩。统计机器学习的最新进展为数据压缩开辟了新的可能性,允许使用强大的生成模型(如归一化流、变分自编码器、扩散概率模型和生成式对抗网络)从数据中端到端地学习压缩算法。本文旨在通过回顾信息论(如熵编码、率失真理论)和计算机视觉(如图像质量评估、感知度量)的必要背景,并通过迄今为止文献中的基本思想和方法,提供一份有条理的指南,将这一领域的研究介绍给更广泛的机器学习受众。
数据压缩的目标是减少表示有用信息所需的比特数。神经压缩,或学习压缩,是神经网络和相关机器学习技术在这项任务中的应用。本文旨在通过回顾神经压缩的先决背景和代表性方法,为对压缩感兴趣的机器学习研究人员提供一个切入点。在当前的深度学习时代[1]-[4]之前,基于学习的数据压缩的基本思想早已以各种形式存在。许多用于神经压缩的工具和技术,特别是图像压缩,也借鉴了计算机视觉中基于学习的方法的丰富历史。事实上,图像处理和恢复中的许多问题都可以看作是有损图像压缩;例如,图像超分辨率可以通过学习固定编码器(图像下采样过程)[5][6]的解码器来解决。事实上,神经网络早在20世纪80年代末和90年代就已经应用于图像压缩[7][8],甚至有一篇早期的综述文章[9]。与早期工作相比,现代方法在规模、神经结构和编码方案方面有显著差异。

深度生成模型的出现,如GANs [10], VAEs[11][12],归一化流[13],以及自回归模型[14],[15]。虽然这些模型允许我们从样本中捕获复杂的数据分布(神经压缩的关键),但研究往往专注于生成真实的数据样本[16],[17]或实现高数据日志密度[12],[18],目标不一定与数据压缩一致。可以说,第一个探索用于数据压缩的深度生成模型的工作出现在2016年[19],自此神经压缩的主题得到了显著增长。多个研究人员已经确定了变分推断与无损[20]、[21]以及有损[22]、[23]、[24]、[25]压缩之间的联系。本文希望进一步促进这些领域之间的交流,提高对压缩的认识,将压缩作为生成建模的一种富有成效的应用以及相关的挑战。本文不调查大量文献,而是旨在涵盖神经压缩的基本概念和方法,为精通机器学习但不一定精通数据压缩的读者提供参考。我们希望通过强调生成模型和机器学习的联系来补充现有的调查,这些调查具有更专业或更实用的重点[27][28][29]。在本文的大部分内容中,我们基本上不对数据做任何假设,只假设它是独立同分布的(i.i.d),这是机器学习和统计学的典型设置。本文围绕图像压缩展开讨论,大多数神经压缩方法都是在这里首次开发的,但本文提出的基本思想与数据无关。最后,在3.7节中,我们提升了i.i.d.假设,并考虑视频压缩,这可以被视为现有思想在时间维度上的扩展。
神经压缩可以以数据驱动的方式简化数据压缩算法的开发和优化。这对于新的或特定领域的数据类型尤其有用,例如VR/AR内容或科学数据,在这些领域开发自定义编解码器可能很昂贵。事实上,基于学习的方法正在应用于新兴的数据类型,如点云[30]-[32],隐式3D表面[33]和神经辐射场[34]。有效压缩这样的数据可能需要新的神经架构[33]和/或领域知识,以将数据转换为神经网络友好的表示[32]。然而,这里介绍的减少学习表示的熵或比特率成本的基本思想和技术保持不变。
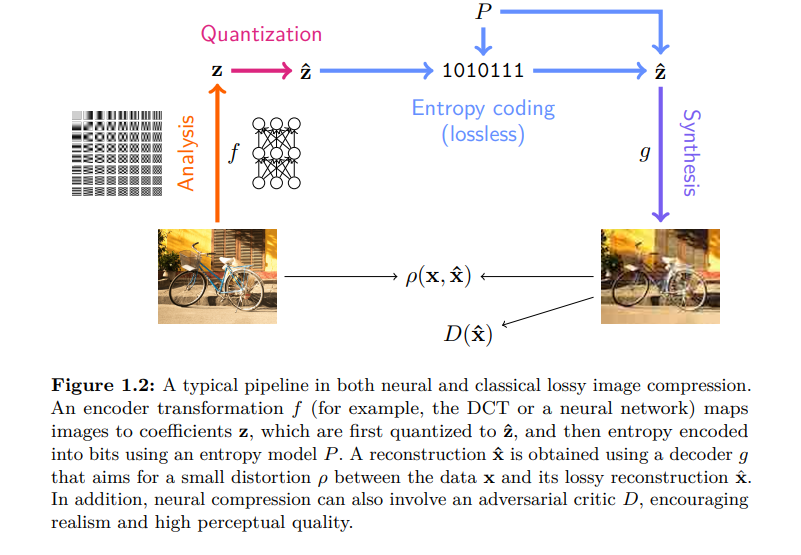
概述。本章主要由两个部分组成,无损压缩(第2节)和有损压缩(第3节),后者依赖前者来压缩数据的有损表示(见图1 - 2)。我们首先回顾基本编码理论(第2.1节),并学习如何在熵编码的帮助下将无损压缩问题转化为学习离散数据分布。为了在实践中工作,我们使用生成建模的工具分解潜在的高维数据分布,包括自回归模型(第2.2节)、潜变量模型(第2.3节)和其他模型(第2.4节)。每个模型类对不同的熵编码算法的兼容性不同,并且在压缩比特率和计算效率之间提供了不同的权衡。有损压缩引入了额外的要求,最常见的是重构的失真,基于此,我们回顾了经典的率失真理论和算法,如矢量量化和变换编码(第3.1节)。介绍了神经有损压缩作为变换编码的自然扩展(第3.2节),讨论了量化表示的端到端学习所需的技术(第3.3节),以及试图绕过量化的有损压缩方案(第3.4节)。在简要回顾视频压缩(第3.7节)之前,探讨了其他要求,如重建的感知质量(第3.5节)和学到的表示对下游任务的有用性(第3.6节)。最后,在第4节中总结了神经压缩的挑战和开放问题,这些问题可能会推动其未来的进展。


