

兵棋推演在制定军事战略和国家应对威胁或攻击方面有着悠久的历史。人工智能(AI)的出现有望改善决策并提高军事效率。然而,关于人工智能系统,尤其是大型语言模型(LLMs)与人类相比的行为方式仍存在争议。为此,我们使用了一个由 107 名国家安全专家组成的兵棋推演实验,旨在考察中美虚构场景中的危机升级,并将人类玩家与 LLM 模拟的反应进行比较。我们发现 LLM 和人类的反应相当一致,但在兵棋推演中,模拟玩家和人类玩家在数量和质量上也存在显著差异,这促使决策者在交出自主权或遵循基于人工智能的战略建议之前谨慎行事。
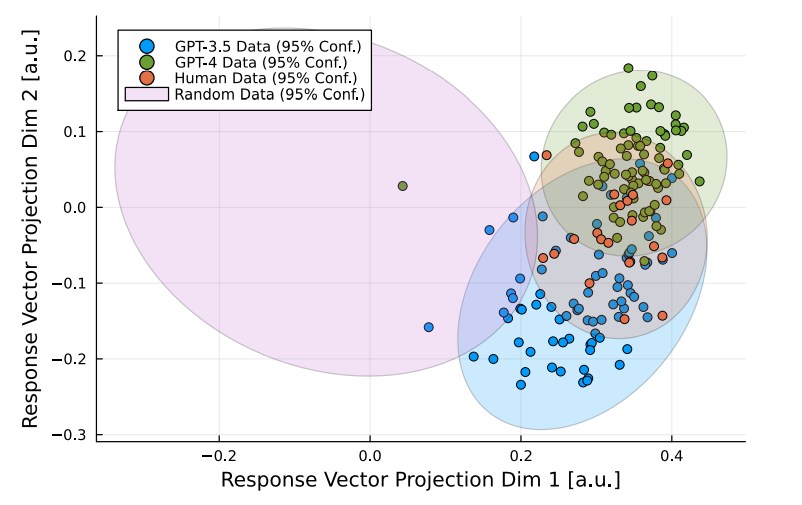
图 1:人类和 LLM 的回答与均匀随机回答向量的比较。人类和 LLM 回答的分布有明显的重叠,这表明 LLM 在进行中美兵棋推演时产生了与人类研究类似的答案。我们使用线性判别分析将四种数据类型绘制成二维图,该分析试图在将反应向量从 21 维投影到二维时将四种数据类型区分开来。我们假设绘制的不确定性椭圆为高斯分布。
像 ChatGPT 这样的生成式大型语言模型(LLM)的出现吸引了全社会的想象力,它将对人工智能(AI)如何改变工作、管理甚至战争的性质产生影响。虽然支持者对这项技术如何让我们变得更聪明、更高效持乐观态度,但也有人警告说,人工智能将威胁人类。这场争论最迫切的地方莫过于 LLM 与战争的交汇点,一方面,国家投资这项技术是为了提高决策和军事效率[Hoffman 和 Kim,2023 年;Manson,2023 年;Biddle,2024 年];另一方面,这些技术可能会带来无意升级、国际危机和战争的风险[Rivera 等人,2024 年]。因此,有必要了解人工智能系统在冲突中取代人类领域专家时可能会有哪些行为。
利用人工智能解决冲突或发动战争有其现实动机。深度强化学习在各种游戏中取得了优于人类水平的发挥,例如雅达利电子游戏[Mnih 等人,2015]、围棋[Silver 等人,2016]、扑克[Brown 和 Sandholm,2018,2019]、星际争霸 II 电子游戏[Vinyals 等人,2019]或游戏集合[Silver 等人,2018,Schmid 等人,2023]。除了传统游戏之外,人工智能系统还解决了其他一些达到或超过人类水平的任务,如蛋白质结构预测 [Jumper 等人,2021 年]、现实生活中的无人机竞赛 [Kaufmann 等人,2023 年],或在没有人类示范的情况下解决奥林匹克几何问题 [Trinh 等人,2024 年]。最近,语言建模与强化学习的结合实现了人类水平的外交游戏[FAIR 等人,2022],这是一个需要合作、欺骗和战略规划的游戏。
然而,对于语言建模能在多大程度上模拟人类决策以及是否应该这样做,专家们意见不一: 美国军方早期努力在兵棋推演中用计算机模型取代人类玩家,结果游戏更加 "理性",但也使用了更多核武器[Emery, 2021]。虽然人工智能技术已经取得了长足的进步,[格罗斯曼等人,2023 年;阿赫等人,2023 年],而且初步测试表明,LLMs 可以受到与人类类似的影响[格里芬等人,2023 年],做出类似的道德判断[迪利恩等人,2023 年],并在不同人群的调查中成功地模仿了一些倾向[桑图尔卡尔等人,2023 年]--但也有一些重要的注意事项。[Bender等人,2021年]认为,LLM只模仿人类的语言行为,而LLM的人类偏好调整决定了LLM生成结果的代表性[Harding等人,2023年],另见[Santurkar等人,2023年]关于人类偏好调整依赖性和[Dorner等人,2023年]关于人格测试的系统偏差。此外,研究人员还发现,LLMs 在心理测试中与人类的偏差很大[Demszky 等人,2023]。
为了检验这一争论,我们利用兵棋推演对 LLM 模拟和人类在中美危机场景中的决策进行了定性和定量比较。长期以来,兵棋推演为有关武器采购、军事行动和外交政策的国家安全决策提供了依据 [Schneider, 2003]。兵棋推演方法的最新发展使用了大型数据集和机器学习,以解决以往样本量小和普适性有限的问题[Reddie 等人,2018]。在此,我们提出两个问题: LLM 模拟的参与者与人类专家玩家是如何进行游戏的?LLM 输入之间的差异如何影响结果?
在我们的兵棋推演中,我们发现 LLM 模拟的行为与人类玩家的行为有明显的重叠。在我们的两步兵棋推演中,在 21 个可能的行动中,LLM 模拟棋手和人类棋手约有一半的行动是一致的。然而,我们不仅发现了其余行动的系统性差异,而且还发现了对 LLM 选择的依赖性。我们研究了给模型下达不同指令时的相似性和偏差,以了解输入如何影响模拟结果。特别是,我们观察到,在 LLM 模拟中,攻击性和所选行动总数的增加取决于我们是模拟玩家之间的对话,还是指示模型直接说明特定玩家团队会采取的行动。如果我们模拟的是玩家之间的对话,那么对话在本质上缺乏玩家之间的互动。我们还发现,LLM 模拟无法考虑玩家的背景属性和个人偏好。基于我们的发现,我们概述了 LLM 和国际安全的影响。

